
从Qwen-Agent到Nanobot搭建股票ChatBI助手
摘要
本文介绍了搭建股票 ChatBI 助手的完整流程。项目利用 Tushare 获取数据存入 SQLite,先以 Qwen-Agent 为原型快速验证自然语言查询、ARIMA 预测及布林带分析等能力,随后迁移至 Nanobot 框架进行工程化改造,最终通过 Gradio 部署 Web 界面。文章对比了两个框架的性能和优缺点。
如何搭建一个股票 ChatBI 助手
写在前面
记录AI Coding 过程及经验分享:从数据收集、数据入库、智能体原型验证,到框架迁移和 Web 界面调试。
理解业务需求,先做轻量级 demo 验证,再做架构迁移与体验完善。
项目目标
股票分析场景下的 ChatBI (Chat Business Intelligence)助手:把数据采集、存储、分析、预测和可视化串在一起,让用户可以直接通过自然语言完成查询和分析。
当前项目围绕以下几只股票做本地验证:
贵州茅台
五粮液
广发证券
中芯国际
目标中的典型能力包括:
历史行情查询:收盘价、成交量、成交额、涨跌幅等
多股票对比:区间涨跌幅、走势对比、统计汇总
自动可视化:根据查询结果自动生成折线图或柱状图
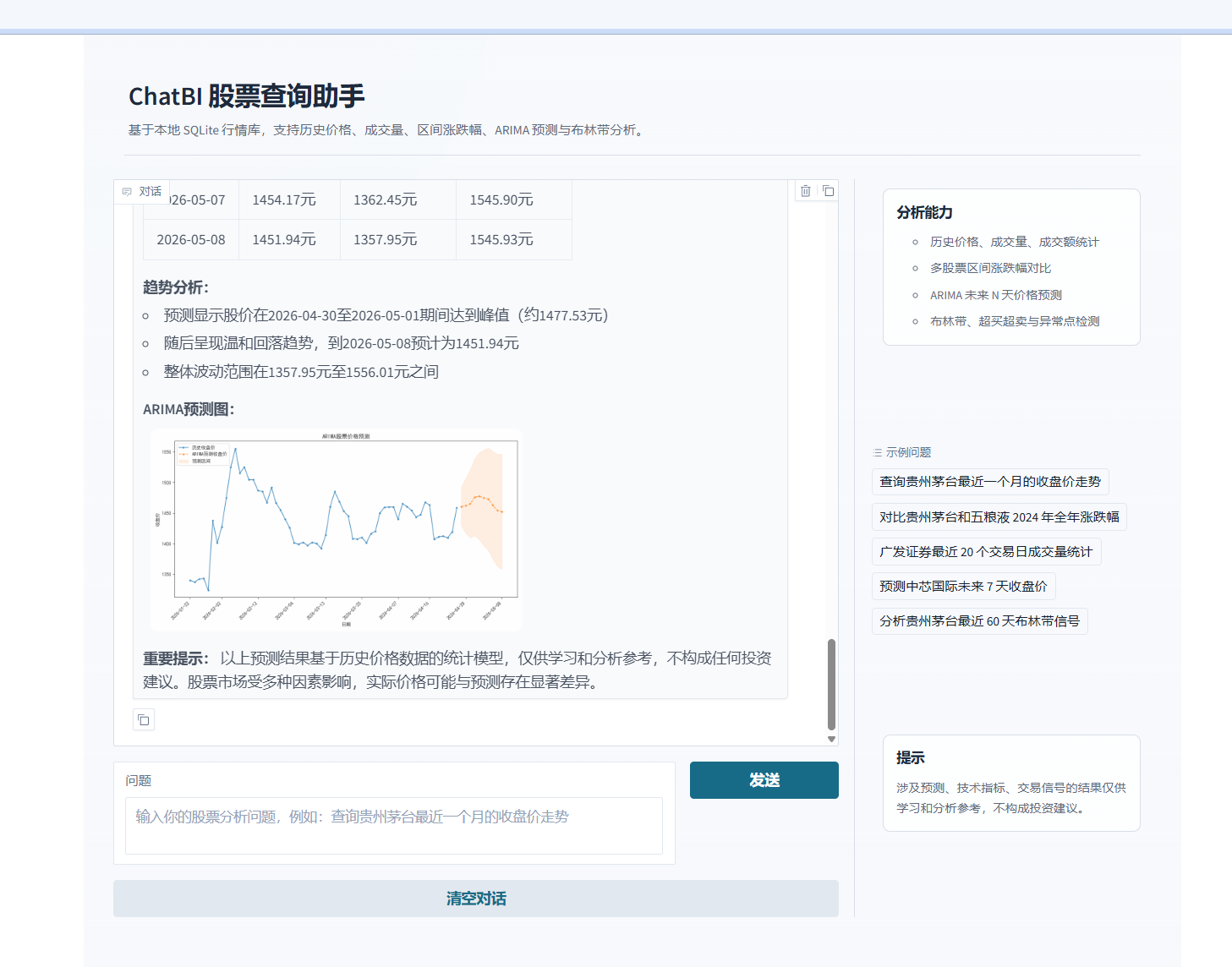
智能预测:基于 ARIMA 预测未来 N 个交易日价格
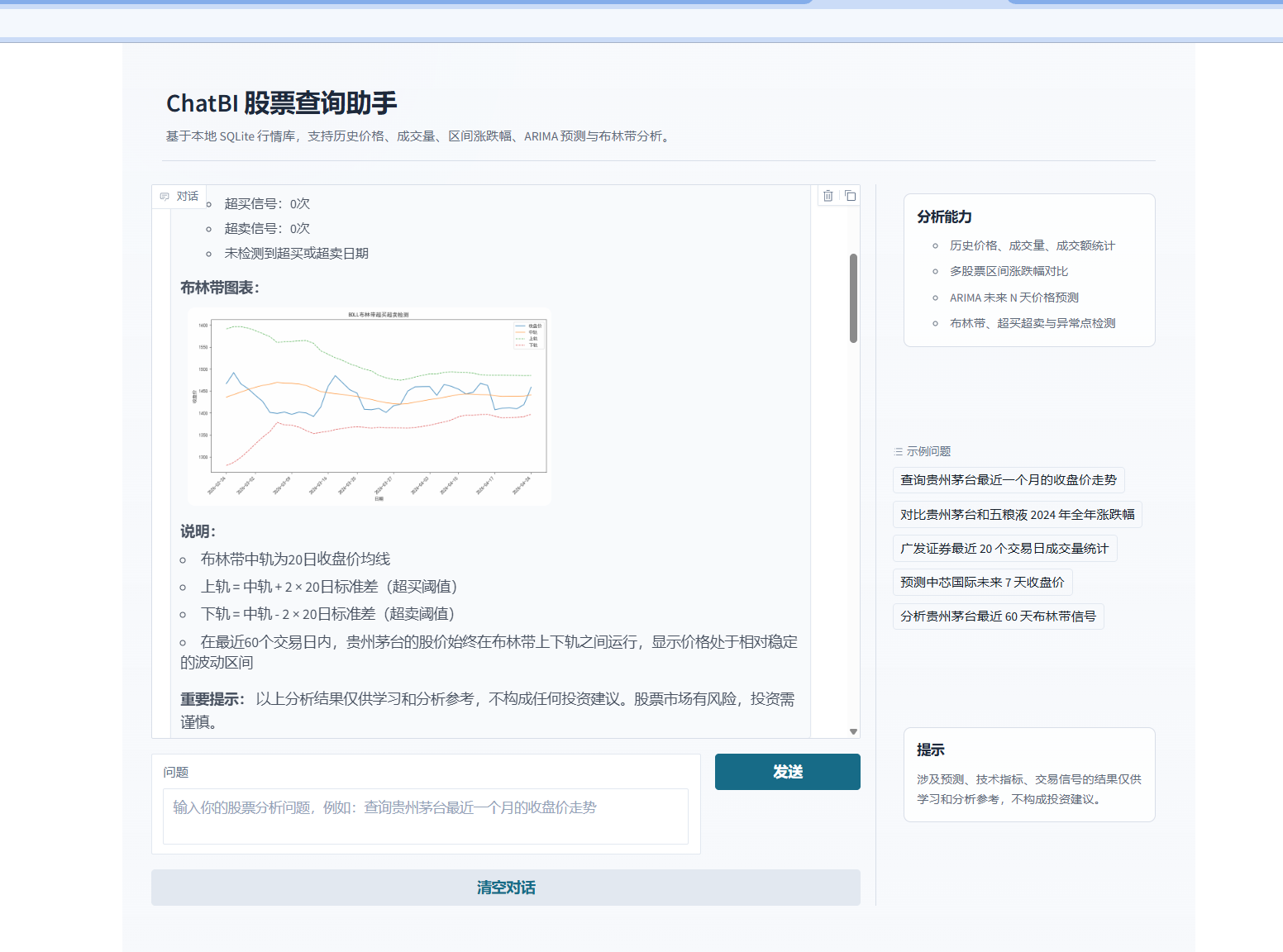
技术指标分析:使用布林带识别超买、超卖和异常点
当前版本 主要聚焦于本地 SQLite 数据库、历史行情查询、ARIMA、布林带和 Gradio 界面。后续可开发像“实时新闻查询”等能力。
本项目用到的工具与框架
1. nanobot
这个项目最终运行在 nanobot 框架上。它可以理解为一个偏工程化、偏运行时的智能体骨架,一个轻量级的 openclaw 。具备以下特点:
配置驱动,模型、Provider、工具开关都可以放到
config.json运行链路清晰,有
AgentLoop、上下文构建、工具循环这些明确的边界很适合做本地 CLI 型智能体,调试时比黑盒框架更容易定位问题
2. Tushare
股票历史数据来源使用 Tushare获取。
通过
TUSHARE_TOKEN环境变量读取密钥拉取指定股票从
2020-01-01到当天的历史日线数据先保存为
.xlsx再写入本地 SQLite 数据库
这样做的好处是简单、可控、便于复现,也特别适合本地开发和提示词迭代。
3. SQLite
本地验证阶段使用 SQLite。
零部署
易于迁移和备份
查询可控
适合和 Pandas、SQLAlchemy、脚本工具链一起使用
4. Qwen-Agent
Qwen-Agent 的优势是结构相对直接,非常适合快速做一个带工具调用的聊天型助手,且功能完善,提供工程化抽象和开箱即用高级组件。
代码量少,容易看懂
Assistant + tool + WebUI的组合很适合快速试错适合把“自然语言 -> SQL -> 查询结果 -> 可视化”这条链先跑通
在本项目里,Qwen-Agent 更多承担的是 轻量原型框架 的角色。
5. Codex、Trae、Cursor 等 AI 编程工具
AI编程工具是AI开发的核心,或者说是新一代编程的核心,它让人由写代码转化为了读代码,提供思路,框架。但是AI编程的幻觉,针对复杂开发推荐使用TDD模式,本次开发较为简单,由Codex 直接完成。
6. 大模型 API
本项目使用的是阿里云百炼的 Qwen 系列模型,密钥通过环境变量 DASHSCOPE_API_KEY 注入。
为什么先用 Qwen-Agent,再迁移到 Nanobot
很多时候我们一上来就会问:到底该选哪个框架?但真正更有效的问题其实是:
当前阶段我最需要的是“快速验证”,还是“长期扩展”?
对于这个项目:
在原型阶段,我更需要快速验证
在迁移阶段,我更需要更清晰的运行架构
整体实现流程:

Qwen-Agent 负责“跑通思路”,Nanobot 负责“承接工程化版本”。当然,不止是Nanbot框架,可以根据需要迁移到不同的框架,我们需要提供一个能跑通的demo,让AI学习新框架的用法,在把当前版本代码迁移。
Qwen-Agent 框架

在本项目原型阶段,Qwen-Agent 的角色主要是:
接收用户关于股票查询的自然语言问题
根据提示词理解数据库结构和查询口径
生成 SQL 或调用封装好的工具
自动返回表格和图表
可以把它理解成一个 demo框架。
Nanobot 架构简介

关键模块理解
config.json
这个文件定义了模型、Provider 和工具开关,是整个项目的配置入口。例如当前项目里最关键的是这几个部分:
当前版本重点依赖本地脚本执行,因此 exec 打开,web 暂时关闭。
AgentLoop
AgentLoop 是整个运行时的核心引擎。它把消息总线、模型、工作目录、工具执行限制、上下文长度和时区等能力统一串起来。
本项目中的核心代码如下:
从这段代码就能看出,Nanobot 比较适合做“边界清楚的智能体系统”。
ContextBuilder
ContextBuilder 类把系统规则、技能说明、当前记忆和环境上下文拼接成模型真正看到的 System Prompt。
本项目里这样实现类似功能,在启动时写入时间上下文:
AgentRunner / LLM + 工具循环
从本质上看,Nanobot 的执行过程依然是“模型判断是否需要工具,再进入工具循环”。
本项目中的 ChatBIHook 把工具调用过程打印出来,方便观察执行过程:
项目具体实现步骤
第一步:用 Tushare 准备数据
让 AI 帮我写出一个数据采集脚本,从 Tushare 拉取四只股票从 2020-01-01 到今天的历史价格,并输出到 Excel 和 SQLite。
这里的思路非常直接:
第二步:生成建表 SQL,并把数据落入 SQLite
建表语句很简单,但它明确了后续整个项目的数据边界:
第三步:先用 Qwen-Agent 做出“能聊、能查、能画图”的原型
在这个阶段, 为了让大模型高效率的执行任务,可以准备一个demo.py代码,改代码可以是相似任务的实现,可以是利用qwen agent实现chatBI的样例。
第四步:不断打磨 SQL 工具的返回结果
这里根据调试过程中实际情况调整:
查询结果只有一行时,不做统计,也不画图
DataFrame 预览不只看前 10 行,而是更综合地展示头尾信息
结果返回中加入描述统计,帮助模型更准确地总结
自动根据数据规模选择折线图或柱状图
横坐标做抽样显示,避免图表标签挤成一团
第五步:补上 ARIMA 预测和布林带分析
这里需要注意:
即使是简单的任务,如果出现功能或者版本更新,需要用不同版本号。
这里采用了Viber coding中常用的做法,@一个能运行的代码或者项目,再根据需求生成新的代码,这里还是SDD模式。
AI开发项目如果让大模型完全从0开始开发不建议用SDD(Specification-Driven Development)模式,这种只适合功能简单,代码长度较短的任务,一旦项目功能复制,迭代次数增加,大模型出现幻觉概率直线上升,根据经验。
可以采用TDD(Test-Driven Development)模式,不是常规的以功能文档驱动,模型在长线执行任务的过程中会出现偷懒情况,虚假执行任务,TDD模式是先写测试用例,后续按照测试用例完善代码,只有测试用例不过,模型就必须完善代码,把复杂任务拆解为一个个有明确可执行目标的小任务。
Bollinger
第六步:从 Qwen-Agent 迁移到 Nanobot
当整个思路在 Qwen-Agent 中被验证得比较清楚之后,开始迁移项目到 Nanobot 版本。
迁移的重点是重新梳理运行结构:
配置归拢到
config.json模型 Provider 通过 DashScope 注入
通过技能文件约束不同分析能力的调用方式
利用
AgentLoop承接整个运行时保留 CLI 作为最稳定的调试入口
当前项目主入口是:
agent.py
其中最核心的构造函数是:
第七步:Gradio WebUI
最后一步,是把 CLI 助手接到一个更适合演示的 Web 界面上。
当前界面入口在:
webui.py
项目界面展示
1. 基于Qwen-Agent框架的ChatBI
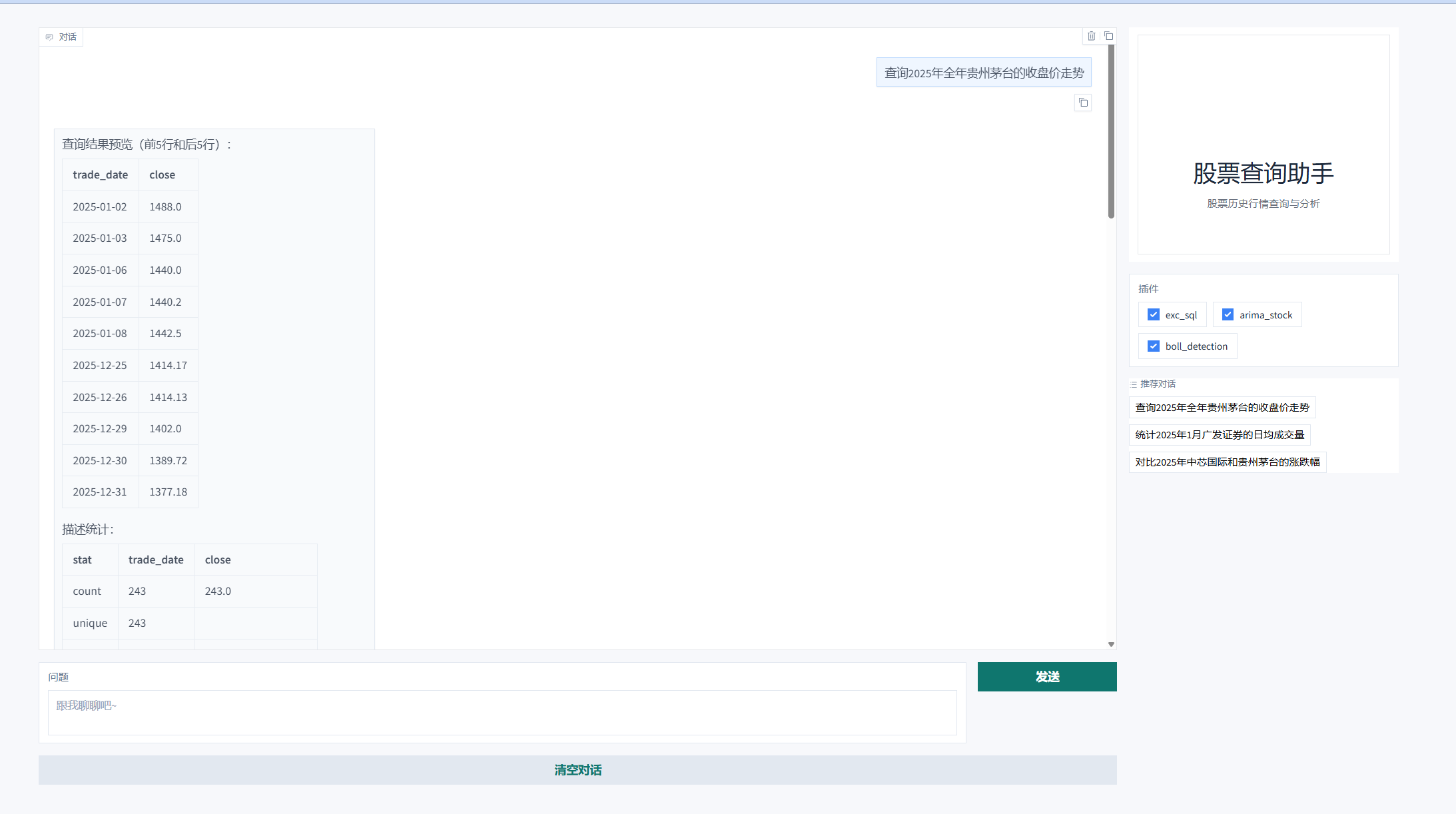
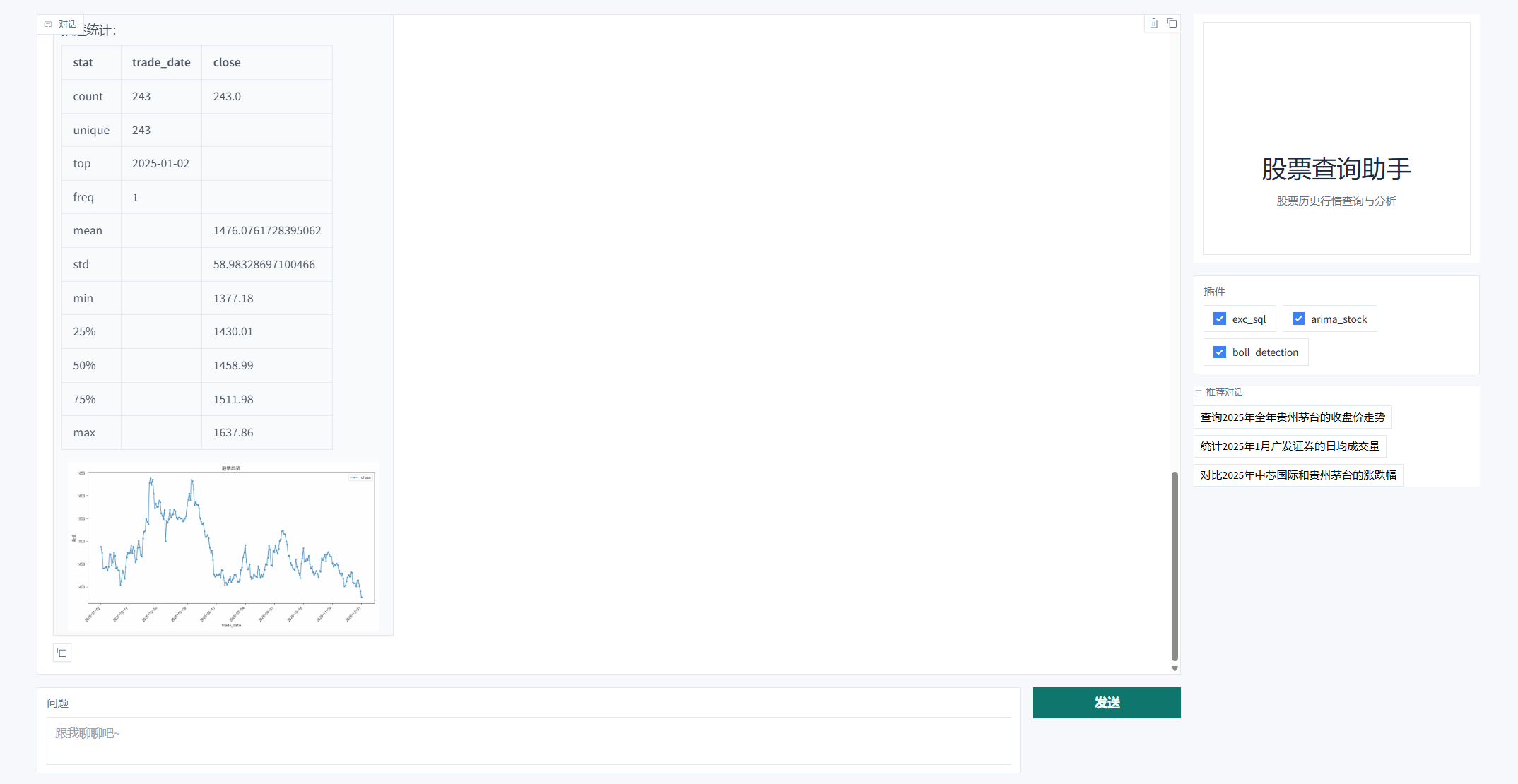
整体工作流:
阶段 | 步骤说明 | 核心操作 / 工具调用细节 | 耗时/时间点 |
系统启动 | 初始化组件 | 注册本地工具与 MCP 工具。初始化 | 17:23:38 |
--- | --- | --- | --- |
任务 1 | 接收用户指令 | 接收提问: | 17:23:59 |
意图与关键字提取 |
| 17:24:01 | |
RAG 知识检索 |
| 17:24:02 | |
执行 SQL 与制图 |
执行查询 (代码逻辑:工具内部静默调用 | 17:24:02 | |
生成最终回复 | Token 消耗完毕(Tokens: 546),组装 Markdown 表格、数据统计和本地图表链接,返回给 Gradio 前端。 | 17:24:05 | |
--- | --- | --- | --- |
任务 2 | 接收新指令 | 接收提问: | 17:25:24 |
意图与关键字提取 | 提取关键词: | 17:25:26 | |
RAG 知识检索 | 再次读取并切分 | 17:25:26 | |
执行预测模型 |
| 17:25:26 ~ 17:25:29 | |
生成预测报告 | 汇总 ARIMA 预测的 DataFrame 和内部生成的 | 17:25:29 |
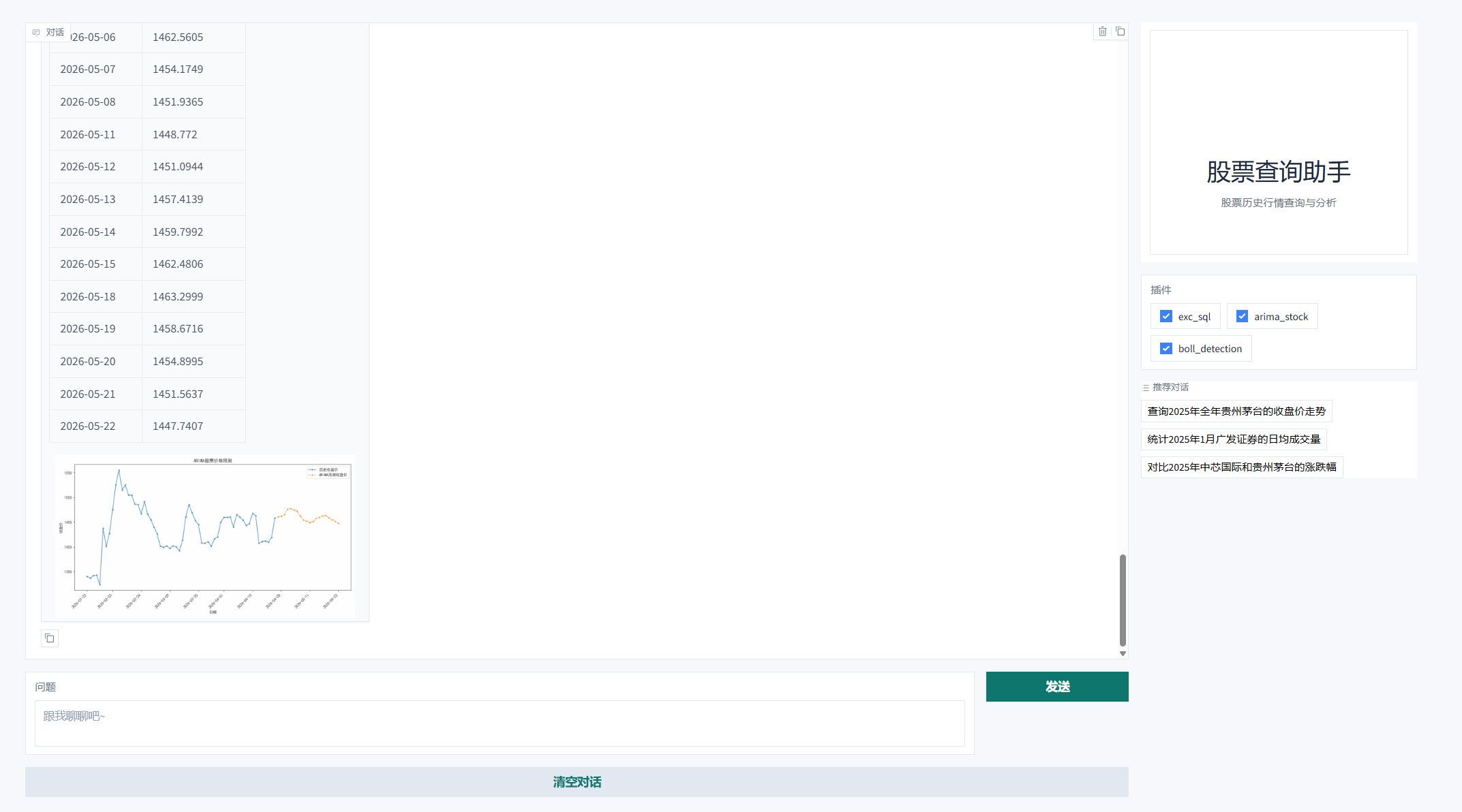
2. 基于Nanobot框架的ChatBI
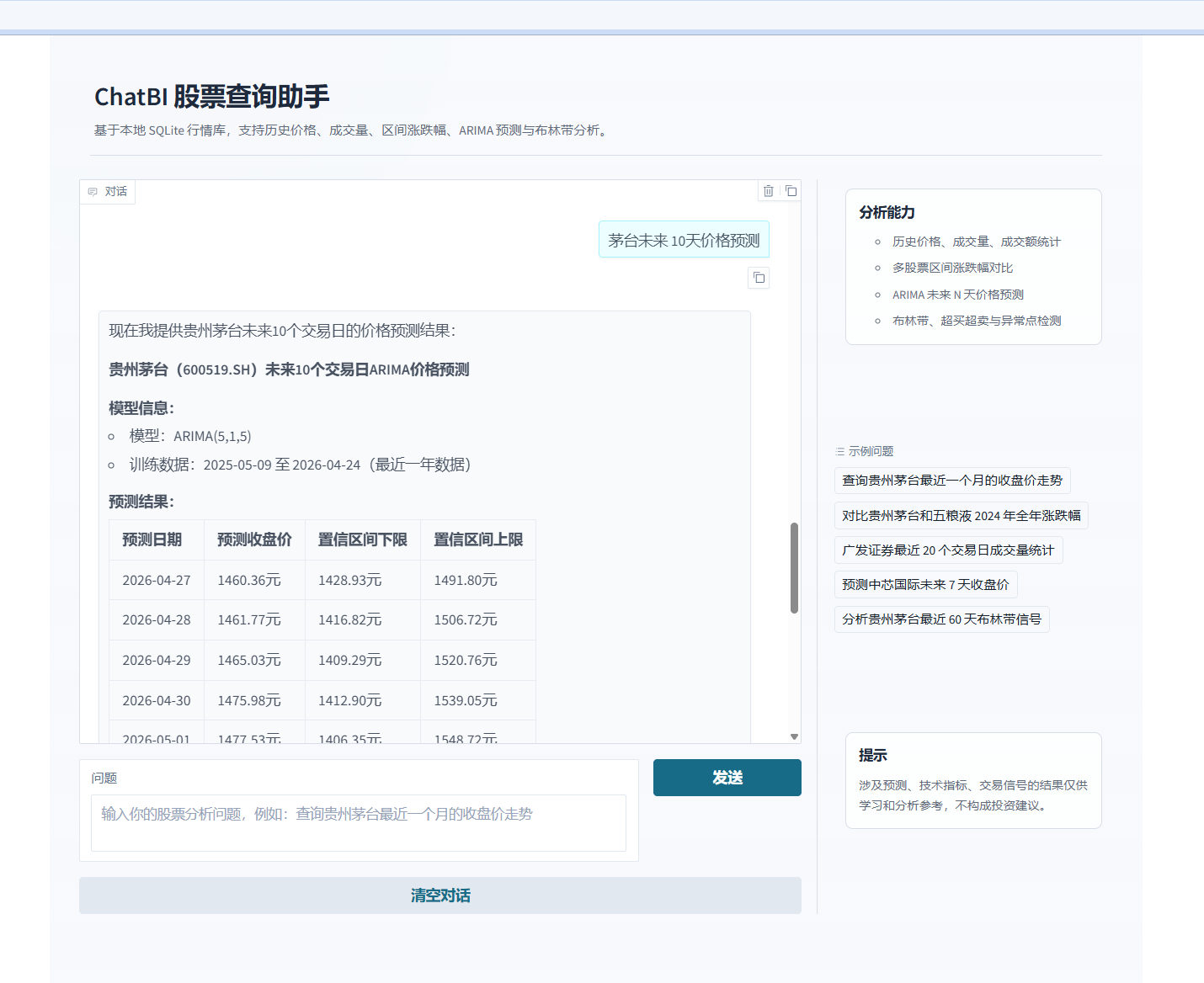
整体工作流:
阶段 | 步骤说明 | 核心操作 / 工具调用细节 | 耗时/时间点 |
任务 1 | 接收用户指令 | 接收提问: | 16:27:54 |
内存与网络检查 |
| 16:27:54 ~ 16:27:54 | |
执行 SQL 查询 |
附带 SQL 参数查询 | 16:28:01 | |
检查图表生成 |
| 16:28:04 | |
生成最终回复 | 基于工具返回的查询数据和图表状态,生成格式化的 Markdown 分析报告,并返回给 WebUI 前端。 | 16:28:16 | |
--- | --- | --- | --- |
任务 2 | 接收新指令 | 接收提问: | 16:29:50 |
内存与网络检查 | Token 增长至 10101,仍有充足空间。再次触发一次 LLM 连接重试。 | 16:29:51 | |
阅读技能文档 |
| 16:29:55 | |
执行预测模型 |
传入参数: | 16:29:58 | |
检查预测图表 |
| 16:30:08 | |
生成预测报告 | 汇总 ARIMA(5,1,5) 模型的输出结果,向前端输出最终的 10 天预测价格报告。 | 16:30:26 |
3. Qwen-Agent框架和Nanobot框架测试对比
对比维度 | Nanobot 架构 (CLI Agent) | Qwen-Agent 架构 (Native Function Agent) | 核心差异说明 |
设计哲学 | 基于操作系统的黑盒调用 像程序员在敲终端命令 | 基于代码环境的白盒内联 像主程序调用内部子模块 | Nanobot 跨语言通用性强;Qwen-Agent 深度绑定 Python 生态,控制力极强。 |
工具执行方式 | 外部 CLI 脚本 ( 拉起独立 Python 子进程 | 内部函数调用 ( 在同一个主进程内热启动运行 | Qwen-Agent 避免了反复冷启动 Python 解释器和重连数据库的巨大开销。 |
状态确认闭环 | 显式多步验证 执行脚本 ➔ 再次调用 | 隐式单步返回 工具执行完毕直接打包 Markdown 和图片路径返回 | Qwen-Agent 的工具集成了 UI 渲染逻辑,大幅精简了 Agent 的探索步骤。 |
知识库与 RAG | 被动发现式 (按需加载) 大模型觉得需要时,才去读 | 主动注入式 (前置召回) Jieba 分词 + 检索,提问前先注入 | Qwen-Agent 将检索从“模型思考的动作”前置为了“工程流水的预处理”,效率更高。 |
大模型交互次数 | 高频 (3~4 次往返) 思考➔读文档➔思考➔执行➔思考➔检查 | 低频 (1~2 次往返) 预检索➔执行内部工具并直接拿回所有结果 | 每次 LLM API 交互都有显著的网络延迟和推理耗时,频次直接决定了响应速度。 |
耗时:简单查询 (单 SQL + 查图) | 约 22 秒 | 约 6 秒 | 简单任务下,Qwen-Agent 提速约 3.6 倍。 |
耗时:复杂预测 (查文档 + 跑模型) | 约 36 秒 | 约 5 秒 | 复杂任务下,Qwen-Agent 提速约 7.2 倍(省去了主动查文档的推理时间)。 |
适用场景推荐 | 需调用跨语言外部脚本、控制老旧服务器、工具本身是黑盒的可执行文件。 | 所有业务逻辑均可用 Python 实现,追求极致交互响应速度、生产力级别应用。 | - |
这里需要注意,两种架构各有优势,本次对比仅限于本项目测试结果,不同样本和不同任务结果可能存在差异,二者LLM均采用qwen-max,大模型本身深度适配Qwen-Agent 架构 。
小结
Q1:这个 ChatBI 项目整体做了什么?
A:这是一个面向股票数据分析的 ChatBI 助手。用户用自然语言提问,比如“查询贵州茅台最近一个月收盘价走势”“预测中芯国际未来 7 天价格”,系统会自动选择 SQL 查询、ARIMA 预测、BOLL 布林带检测等能力,返回表格、统计结果和图表。
核心目标不是做一个单纯聊天机器人,而是让大模型负责理解意图和组织回答,把确定性计算交给工具执行。
Q2:项目的整体五段式架构怎么讲?
A:可以概括为:
在 qwen-agent 版本里,核心是 Assistant + function_list + tools + system_prompt。
在 nanobot 版本里,链路更工程化:config.json -> AgentLoop -> ContextBuilder -> AgentRunner -> Response。
qwen-agent 适合快速验证,nanobot 更适合后续工程化迁移。
Q3:为什么先用 qwen-agent,再迁移到 nanobot?
A:qwen-agent 的优点是轻量、调试快,适合验证“自然语言到工具调用”的闭环。比如 assistant_stock_bot.py 里直接注册 ExcSQLTool、ArimaStockTool、BollDetectionTool,很快能跑通 Demo。
nanobot 的优势是结构更清晰,适合把能力拆成 skills/*/SKILL.md 和独立脚本。这样上下文、工具说明、运行配置、会话管理都更容易维护。
Q4:ExcSQLTool 是怎么封装的?
A:ExcSQLTool 的职责不是简单执行 SQL,而是把 SQL 查询、结果预览、描述统计和图表生成封装成一个稳定工具。
它做了几件事:
校验 SQL,只允许 SELECT 或 WITH,避免误改数据库。
用 SQLite 查询本地 stock_daily_price 表。
如果结果多于一行,生成前 5 行 + 后 5 行预览。
生成 describe 描述统计。
自动根据结果生成折线图或柱状图。
最终返回 markdown 表格和图片路径。
这样大模型不需要自己计算数据,只需要解释工具返回结果。
Q5:为什么不能让 LLM 直接算涨跌幅、均值、预测结果?
A:因为金融数据分析属于高精度、可复现任务。LLM 适合理解问题和生成解释,不适合承担精确数值计算。
比如区间涨跌幅必须按公式算:
不能让模型凭文本推理,也不能用 pct_chg 的平均值替代。
所以项目里把数值计算交给 SQL、pandas/Polars、ARIMA、BOLL 工具完成,再把结果喂给 LLM 解释。
当前代码主要用 pandas,工程上也可以换成 Polars 来提升大数据场景下的性能。
Q6:为什么要做归一化对比分析?
A:不同股票价格量级差异很大。比如贵州茅台价格上千元,中芯国际可能只有几十元。如果直接画价格曲线,低价股票走势会被压扁,看不出变化。
归一化的思路是把不同股票统一到同一起点,比如:
这样比较的是相对涨跌,而不是绝对价格。
Q7:上下文问题?怎么解决?
A:常见问题是上下文太长、规则被稀释、工具选择不稳定。
本项目的解决方式是:
把核心业务规则写进 system_prompt 或 AGENTS.md。
把不同能力拆成技能文件,比如 stock-sql、arima-predict、bollinger。
只有需要某项能力时,再读取对应 SKILL.md。
工具返回结构化结果,减少模型自由发挥空间。
这样可以避免把所有规则一次性塞进 prompt,降低上下文污染。
Q8:知识库在这个项目里解决了什么问题?
A:知识库主要解决“业务口径”和“工具使用规则”的问题。
比如用户问“价格”,默认用 close 收盘价;问“全年涨跌幅”,必须用首尾收盘价计算;问“BOLL”,要调用布林带工具。这些规则如果只靠模型记忆,很容易出错。
所以项目里通过 faq.txt、AGENTS.md、skills/*/SKILL.md 把规则显式化,让 Agent 在执行前有依据。
Q9:为什么要把 ARIMA 和 BOLL 做成独立工具?
A:因为它们是明确的算法能力,不应该让 LLM 临时生成代码或口算。
ARIMA 工具负责:
从 SQLite 读取最近一年收盘价。
使用 ARIMA(5,1,5) 建模。
预测未来 N 个交易日。
生成预测曲线图。
BOLL 工具负责:
计算 20 日均线。
计算上轨和下轨。
判断 close > upper_band 为超买,close < lower_band 为超卖。
返回异常点和图表。
这样每个工具边界清楚,也方便后续替换模型或算法。
Q10:这个项目里 LLM 和工具的边界怎么划分?
A:LLM 负责理解和表达,工具负责事实和计算。
LLM 负责:
理解用户意图。
判断调用哪个工具。
组织自然语言回答。
总结表格和图表含义。
工具负责:
SQL 查询。
涨跌幅计算。
描述统计。
ARIMA 预测。
BOLL 检测。
图表生成。
这个边界能降低幻觉,提高可复现性。
相关文章
暂无相关文章