
Dify部署与应用实践
摘要
本文整理 Dify 的本地部署、应用类型、Chatflow 与 Workflow 的区别,以及 LLM 联网搜索、智能客服、MinerU 文档分析和 API 调用几个代表性应用。重点说明 Dify 如何通过模型、工具、知识库和流程编排构建可落地的 AI 应用。
Dify部署与应用实践
写在前面
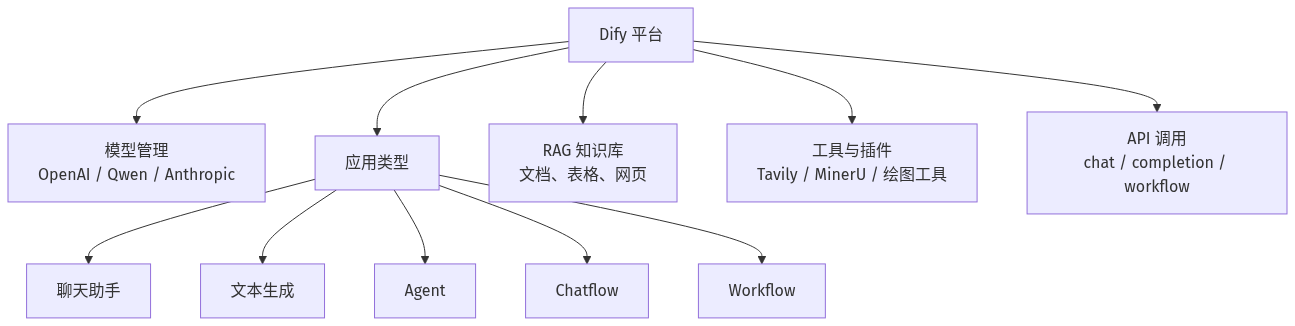
Dify 是一个开源 LLM 应用开发平台。它把模型管理、Agent 构建、Workflow 编排、Chatflow 对话流、RAG 知识库和 API 发布整合在一起,适合快速搭建生成式 AI 应用。
从使用体验上看,Dify 比直接写 LangChain 更容易上手。LangChain 更偏代码框架,适合深度定制;Dify 更偏平台化应用开发,适合先把业务流程跑通,再逐步沉淀为可复用应用。
这篇文章按工程实践整理,重点写四件事:本地部署、应用类型选择、典型工作流案例、API 调用。古诗词文生图这类创意工作流只做简要说明,因为它和前面 Coze 的文生图流程重复较多;这里优先展开更适合工程复用的联网搜索、智能客服和文档分析。
一、Dify 应用类型
Dify 提供五类应用。不同类型对应不同任务,不建议一开始都用 Agent。
应用类型 | 适用场景 | 特点 |
|---|---|---|
聊天助手 | 对话式问答、客服、知识助手 | 基于 LLM 的多轮交互 |
文本生成应用 | 翻译、分类、改写、总结 | 单次输入生成单次输出 |
Agent | 需要任务分解、推理和工具调用 | 自主性更强,但不如流程稳定 |
Chatflow | 多轮对话中的复杂流程 | 支持记忆、Answer 节点和动态编排 |
Workflow | 自动化、批处理、单轮复杂任务 | 单向生成结果,适合稳定流程 |
我的理解是:如果任务是问答,优先聊天助手;如果任务是固定输入输出,优先 Workflow;如果需要多轮交互和分类分流,优先 Chatflow;如果任务不确定、需要模型自主调用工具,再考虑 Agent。
二、本地化部署
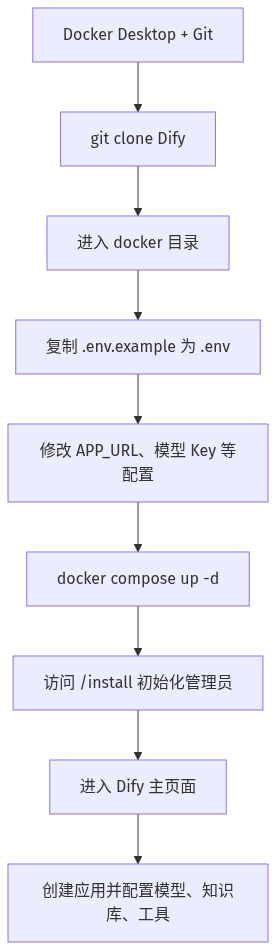
Dify 本地部署主要有两种方式:Docker Compose 部署和源码部署。一般优先选 Docker Compose。它把 Web、API、数据库、队列、向量库等组件封装成容器,环境隔离更稳定,也更适合个人或团队快速搭建。
2.1 前置环境
部署前需要准备:
组件 | 作用 |
|---|---|
Docker Desktop | 运行 Dify 各个容器服务 |
Docker Compose | 通过 YAML 文件编排多容器应用 |
Git | 克隆 Dify 代码仓库 |
Docker 的作用是把应用和依赖打包在容器中,减少本地环境差异。Docker Compose 的作用是用一个配置文件定义多个服务,再用一条命令启动整个系统。
2.2 克隆代码并配置环境
.env 是部署的核心配置文件。常见需要关注的配置包括:
配置项 | 说明 |
|---|---|
| Dify 的访问地址,本地通常是 |
数据库配置 | 默认可以使用 Docker 内置数据库,也可以接外部数据库 |
模型供应商 Key | OpenAI、Anthropic、Qwen 等模型供应商 API Key |
向量库配置 | 与知识库检索相关 |
本地测试时,可以先使用默认配置跑通。真正部署到服务器时,再检查端口、域名、HTTPS、数据库持久化和模型密钥管理。
2.3 启动服务
在 dify/docker 目录执行:
-d 表示后台运行。启动后等待几分钟,浏览器访问:
首次访问需要初始化管理员账户。初始化完成后,访问:
即可进入 Dify 主页面。
2.4 更新与重启
更新 Dify:
重启服务:
如果更新后出现异常,应先查看容器状态和日志,而不是直接删除数据卷。
三、Chatflow 与 Workflow
Dify 中最容易混淆的是 Chatflow 和 Workflow。
Chatflow 面向多轮对话。它支持上下文记忆,适合智能客服、语义搜索、AI 助教、引导式任务等场景。它的重点是用户交互过程,可以在流程中间使用 Answer 节点输出内容。
Workflow 面向单轮任务或自动化任务。它适合批处理、内容生成、搜索总结、文档分析等场景。它的重点是稳定执行,从输入走到输出,不强调多轮对话记忆。
对比项 | Chatflow | Workflow |
|---|---|---|
交互方式 | 多轮对话 | 单轮输入输出 |
是否强调记忆 | 是 | 否 |
典型节点 | Answer、问题分类器、知识检索、LLM | 开始、LLM、工具、代码、结束 |
适合场景 | 客服、助教、交互式问答 | 搜索总结、文档处理、批量生成 |
输出方式 | 可中途回复 | 通常结束节点统一输出 |
简单判断:用户需要持续对话,用 Chatflow;用户提交一次任务等结果,用 Workflow。
四、案例一:LLM 联网搜索 Workflow
联网搜索用于处理时效性问题。比如用户问“黄金价格和哪些因素有关”,模型自身可能能回答一部分,但不能保证最新。更稳的方式是先提取关键词,再用搜索工具获取网页信息,最后由 LLM 总结。
这个 Workflow 的结构很简单。
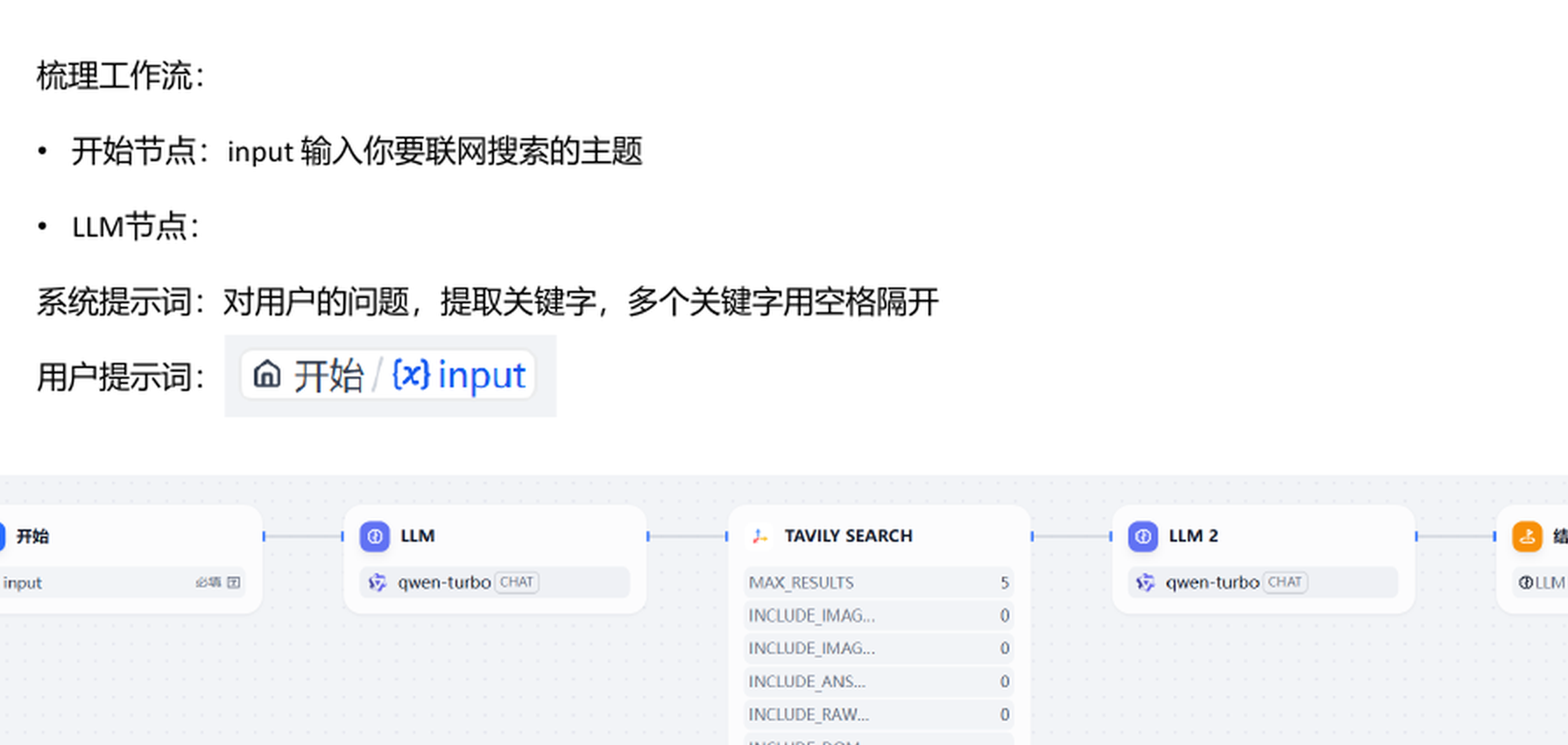
4.1 TavilySearch 配置
先申请 Tavily Search API Key,再在 Dify 工具中安装并授权 TavilySearch。这个工具适合网页搜索,支持多语言和高级筛选。
4.2 节点配置
开始节点设置一个输入变量:
第一个 LLM 节点负责提取关键词,不负责回答。
TavilySearch 节点使用前一个 LLM 节点输出的 text 作为查询变量。
第二个 LLM 节点负责总结搜索结果。
结束节点输出第二个 LLM 节点的 text。
这个案例的工程意义在于分工清楚:第一个模型做查询改写,搜索工具做信息获取,第二个模型做阅读总结。不要让一个节点同时承担搜索意图、联网、阅读和回答。
五、案例二:智能客服 Chatflow
智能客服更适合用 Chatflow,因为用户问题类型不同,并且有多轮对话需求。这里的场景是证券业务客服,用户问题分为三类:营销咨询、投诉处理、其他问题。
分类 | 处理方式 |
|---|---|
营销咨询、证券知识 | 检索证券知识库,回答产品介绍、交易规则等高频问题 |
投诉处理、产品使用不成功 | 提取用户信息,检索用户行为和标签数据,生成处理建议 |
其他问题 | 直接回复无法回答 |
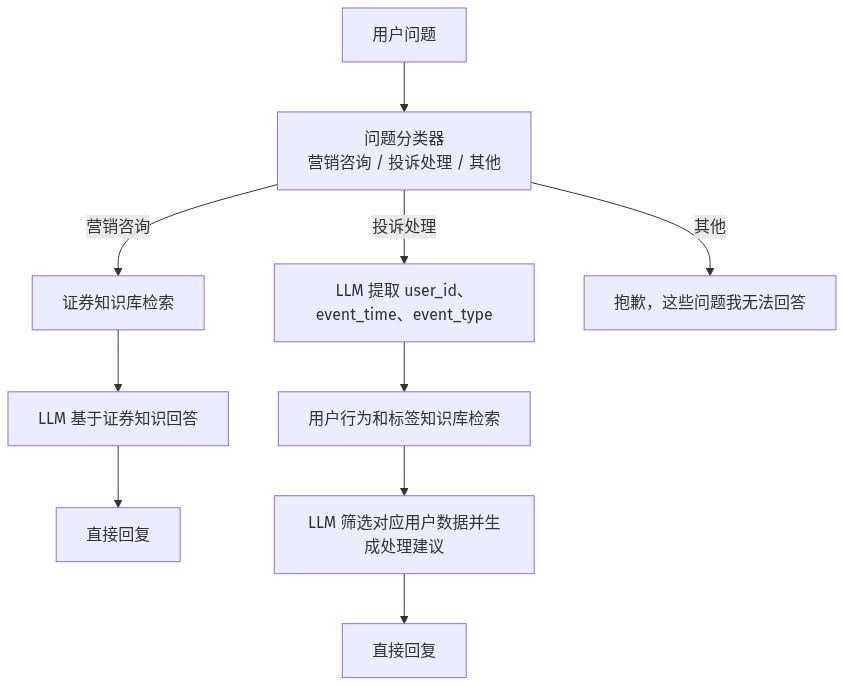
5.1 问题分类器
第一步使用问题分类器。模型可以选择质量较高的通用模型,例如 qwen-turbo-latest。分类设计要清晰,不要让多个分类重叠。
5.2 营销咨询分支
营销咨询分支使用证券知识库。知识库需要提前上传证券产品介绍、交易规则、交易所规则等文档。查询变量直接使用开始节点中的用户问题。
知识检索后接 LLM 节点。系统提示词重点是让模型只基于上下文回答。
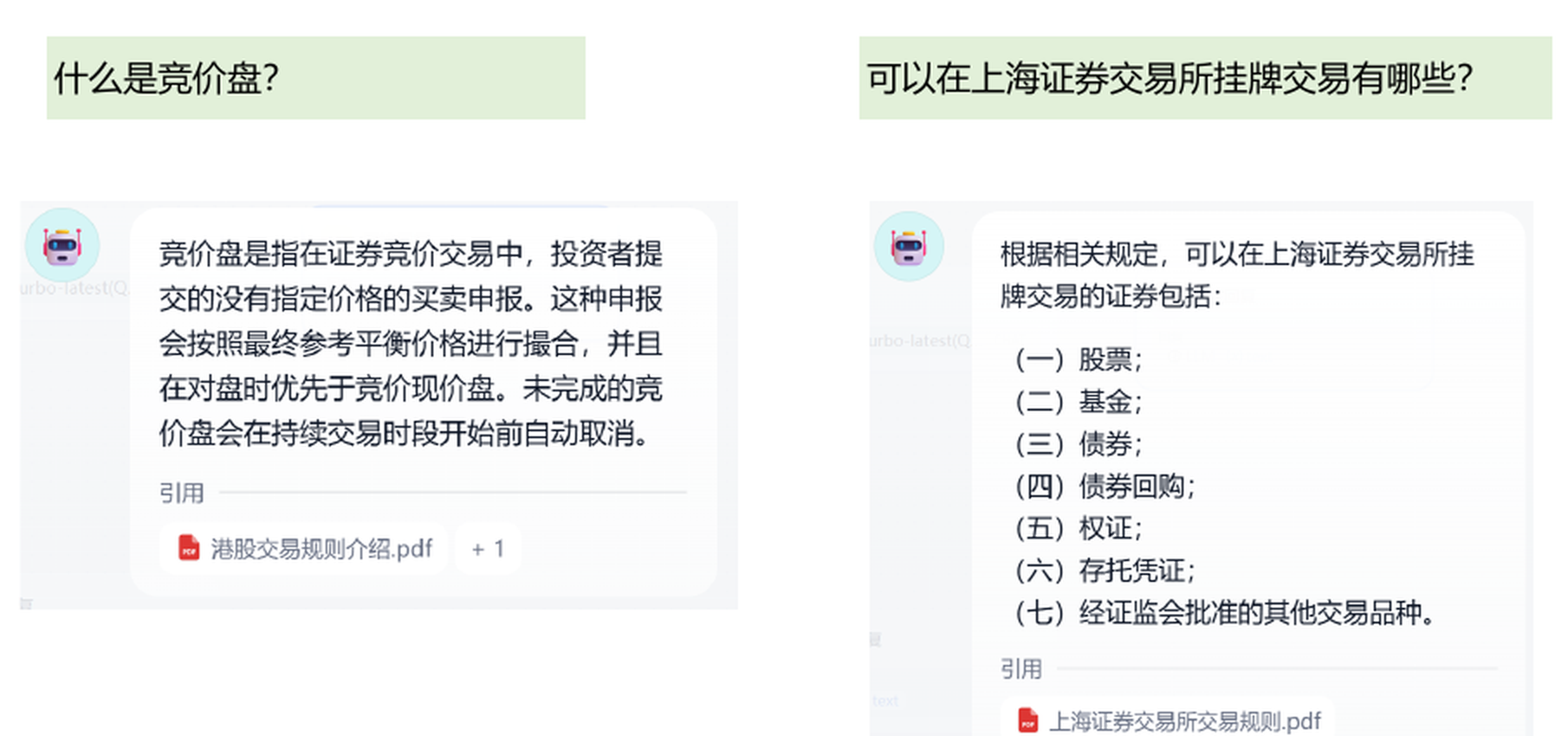
下面是证券知识库问答结果。问题是“什么是竞价盘”和“可以在上海证券交易所挂牌交易有哪些”。回答中能看到引用来源,说明检索链路有效。
5.3 投诉处理分支
投诉处理分支更复杂。用户可能会说:
这时需要先提取结构化信息。
提取节点提示词可以约束输出格式。
然后从用户行为数据和用户标签知识库中检索相关记录。由于数据来自 Excel,建议使用混合检索,并适当增加 TopK。原因是这类数据既需要精确命中 user_id,也可能需要语义匹配事件类型。
最后用 LLM 根据检索出来的数据生成投诉处理建议。这里要特别强调筛选用户 ID,避免把其他用户的数据混入回复。
5.4 知识库检索参数
智能客服的效果很大程度取决于知识库质量。几个参数需要提前考虑。
参数 | 作用 | 建议 |
|---|---|---|
分段标识 | 控制文档切片边界 | 结构不佳的文本建议预设强分隔符 |
最大长度 | 控制每个切片大小 | 问答型知识适合小而精 |
重叠比例 | 保留上下文 | 常见平衡点 10%-20% |
索引模式 | 影响语义理解质量 | 专业内容优先高质量模式 |
Embedding 模型 | 决定向量检索上限 | 选定后更换需要重建索引 |
Rerank | 提升排序相关性 | 提升精度但增加延迟 |
Score 阈值 | 控制召回过滤 | 不存在通用最佳值,需要实测 |
混合检索 | 结合语义和全文检索 | 适合术语、编号、用户 ID 等场景 |
智能客服不是简单接入知识库,而是分类、检索、结构化抽取和回复策略的组合。
六、案例三:智能文档分析助手
文档分析助手适合处理复杂 PDF。普通 PDF 解析对多栏排版、图表、公式和科研论文不够稳定,因此这里引入 MinerU 作为文档解析工具。
场景是:用户上传一篇论文 PDF,并提问“论文的实验结果怎么样”。流程如下。
6.1 输入变量设计
开始节点设置两个变量:
变量 | 类型 | 说明 |
|---|---|---|
| 单文件,文档类型 | 用户上传的 PDF |
| 文本 | 用户要问的问题 |
6.2 MinerU 工具
MinerU 负责 PDF 解析。可以把 MinerU 的核心能力封装为 Dify 工具,通过 API 暴露给工作流。工具输入是 uploaded_pdf,输出是解析后的 text。
6.3 LLM 回答节点
系统提示词可以保持简单,但必须要求基于解析文本回答。
用户提示词引用用户问题:
结束节点输出 LLM 的 text。
下面是文档分析助手的输出结果。可以看到,系统围绕 InternVideo2.5 的实验表现进行总结,包括短视频、长视频基准和视觉能力提升。

这个案例的核心不是“让模型读 PDF”,而是把 PDF 解析和 LLM 回答拆开。解析工具负责把复杂版式变成可用文本,LLM 负责基于文本回答问题。这样比直接把 PDF 丢给模型更稳定。
七、Dify API 调用
Dify 应用发布后,可以通过 API 接入其他系统。常见有三类端点。
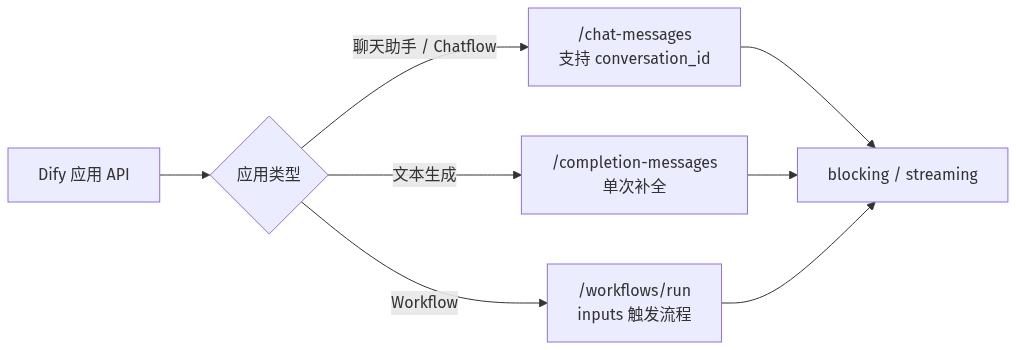
应用类型 | API 端点 | 说明 |
|---|---|---|
聊天应用 |
| 支持多轮对话,可传 |
文本生成应用 |
| 单次完成任务,不维持对话状态 |
工作流应用 |
| 通过 |
7.1 客户端封装
为了在其他项目中复用,可以封装一个简单客户端。
客户端只负责三件事:保存 Dify 服务地址,保存 API Key,统一构建请求头。
7.2 聊天应用调用
聊天应用使用 /chat-messages。用户输入通过 query 字段传递,conversation_id 用于维持上下文。
7.3 文本生成应用调用
文本生成应用使用 /completion-messages。它适合翻译、分类、摘要等一次性任务。
7.4 工作流应用调用
Workflow 使用 /workflows/run。输入参数必须通过 inputs 传递,并且字段名要和工作流开始节点中的变量一致。
下面是工作流 API 调用示例。左侧是调用代码,右侧是对“黄金价格和哪些因素有关”的工作流总结结果。

如果需要写一个通用客户端,可以按聊天、完成、工作流的顺序自动尝试端点,根据错误信息判断应用类型。这样一个客户端就能兼容多种 Dify 应用。
八、方法选择
Dify 的核心不是单个节点,而是选择合适的应用形态和编排方式。
需求 | 推荐方案 | 原因 |
|---|---|---|
简单问答 | 聊天助手 + 知识库 | 配置成本低 |
单次内容生成 | 文本生成应用 | 输入输出明确 |
联网搜索总结 | Workflow + 搜索工具 + LLM | 流程稳定,易复用 |
智能客服 | Chatflow + 分类器 + 知识库 | 多轮对话和分支处理更自然 |
复杂文档问答 | Workflow + MinerU + LLM | 解析和回答解耦 |
外部系统集成 | API 调用 | 可嵌入自有项目 |
我的经验是,能用 Workflow 明确表达的任务,不要一开始就做成 Agent。Agent 的自主性更强,但调试成本也更高。业务流程明确时,显式节点比模型自由决策更可靠。
小结
Dify 适合把 LLM 应用从“提示词演示”推进到“可运行流程”。本地部署解决平台可控性,Workflow 解决稳定单轮任务,Chatflow 解决多轮交互,知识库解决私有知识,API 解决系统集成。
后续做 Dify 项目时,我会优先按这个顺序推进:先明确应用类型,再设计输入输出,再选择工具和知识库,最后再写提示词。流程能画清楚,系统才容易调试;数据边界能定义清楚,模型回答才不容易跑偏。