
深入 Claude Code:AI Agent 系统设计空间论文阅读
摘要
本文解读论文 Dive into Claude Code: The Design Space of Today’s and Future AI Agent Systems。论文通过源码分析 Claude Code 的系统架构,并与 OpenClaw 对比,提出生产级 AI Agent 系统的核心设计问题、架构取舍和未来方向。
深入 Claude Code:AI Agent 系统设计空间论文阅读
写在前面
这篇论文研究的对象不是一个新的模型,也不是一个新的 Benchmark,而是一个生产级编码智能体系统:Claude Code。
论文的核心问题是:一个能够读取文件、修改代码、执行命令、调用外部服务并持续迭代的 AI Agent,应该如何组织推理、工具、安全、上下文、扩展机制、子代理和会话状态。
论文题目为 Dive into Claude Code: The Design Space of Today’s and Future AI Agent Systems,作者通过分析 Claude Code 公开 TypeScript 源码,并与开源系统 OpenClaw 对比,试图回答生产级 AI Agent 系统的设计空间问题。
本文按照“问题、方法、架构、结果、启发”的顺序解读这篇论文。
论文一句话概括
Claude Code 的核心不是复杂的规划器,而是一个简单的模型-工具循环;真正复杂的部分在循环外围,包括权限控制、上下文压缩、扩展机制、子代理隔离和会话持久化。
换言之,论文认为 Claude Code 的关键设计不是“让模型被更多规则管住”,而是“让模型在一个确定性工程外壳中自由判断”。
论文要解决什么问题
传统代码补全工具主要回答“下一行代码是什么”。Agentic coding 工具则需要回答更复杂的问题:
模型是否可以直接执行命令;
工具调用前是否需要用户批准;
长上下文如何压缩;
插件、MCP、技能和钩子如何共同工作;
子代理是否共享父代理上下文;
会话如何恢复、分叉和审计;
自动化能力增强后,人的理解能力是否会下降。
这些问题已经超出模型能力本身,进入系统架构层面。论文的贡献在于把 Claude Code 还原成一组明确的架构选择,并说明这些选择背后的价值取向和工程约束。
核心创新点与贡献
论文的主要贡献可以概括为四点。
第一,论文提出了一个面向生产级编码 Agent 的设计空间。这个设计空间包括推理位置、执行循环、安全边界、扩展机制、上下文管理、子代理委派和会话持久化。
第二,论文从 Claude Code 源码中提炼出五类人类价值和十三条设计原则。五类价值包括人类决策权、安全与隐私、可靠执行、能力放大和上下文适应性。这些价值被进一步映射到具体架构选择。
第三,论文给出了 Claude Code 的系统级架构拆解。作者将其抽象为七个高层组件和五层子系统结构,使读者可以从系统工程角度理解 Claude Code。
第四,论文将 Claude Code 与 OpenClaw 进行对比,说明相同的设计问题在不同部署场景下会产生不同答案。Claude Code 是面向代码仓库和终端会话的 harness;OpenClaw 是面向多渠道个人助手的网关控制平面。
研究方法
论文采用的是源码分析和架构对比方法,而不是实验训练方法。
作者的证据分为三个层次:
Tier A:产品文档证据,来自 Anthropic 官方文档和工程文章;
Tier B:源码验证证据,来自 Claude Code v2.1.88 的公开 TypeScript 源码;
Tier C:重构推断证据,来自社区分析、OpenClaw 对比和代码结构推断。
其中,最重要的是 Tier B。论文通过源码文件、函数和模块边界来说明 Claude Code 的真实实现,而不是仅依赖产品介绍。
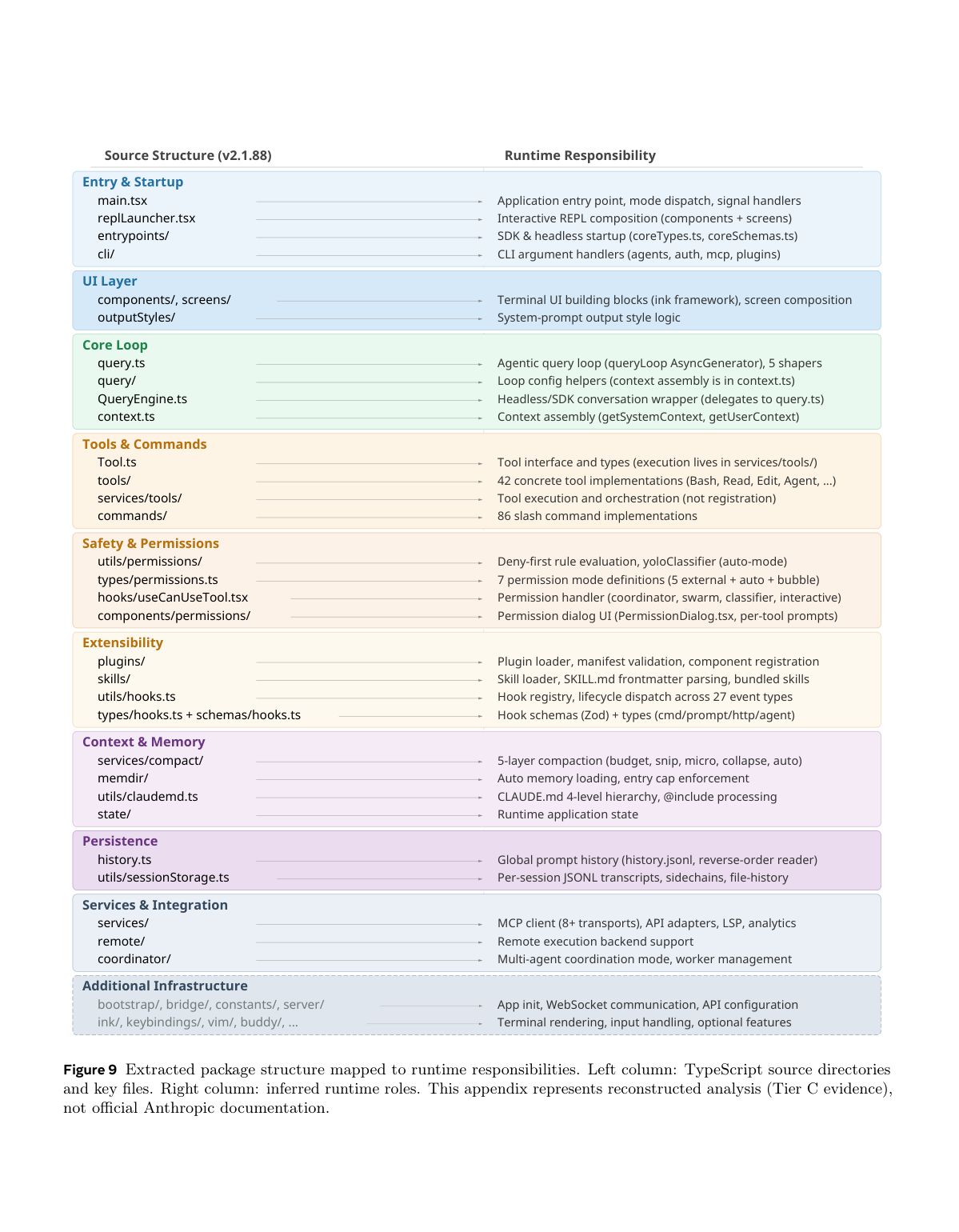
论文附录中说明,分析对象约包含 1884 个文件和 51.2 万行 TypeScript 代码。OpenClaw 用作校准对象,不作为 Claude Code 的真实实现依据。
论文还给出了 Claude Code 源码包结构与运行时职责的映射。该图有助于理解作者为什么能够从源码层面还原系统架构。
Claude Code 的总体架构
论文首先将 Claude Code 抽象为七个高层组件:用户、接口、Agent 循环、权限系统、工具、状态与持久化、执行环境。
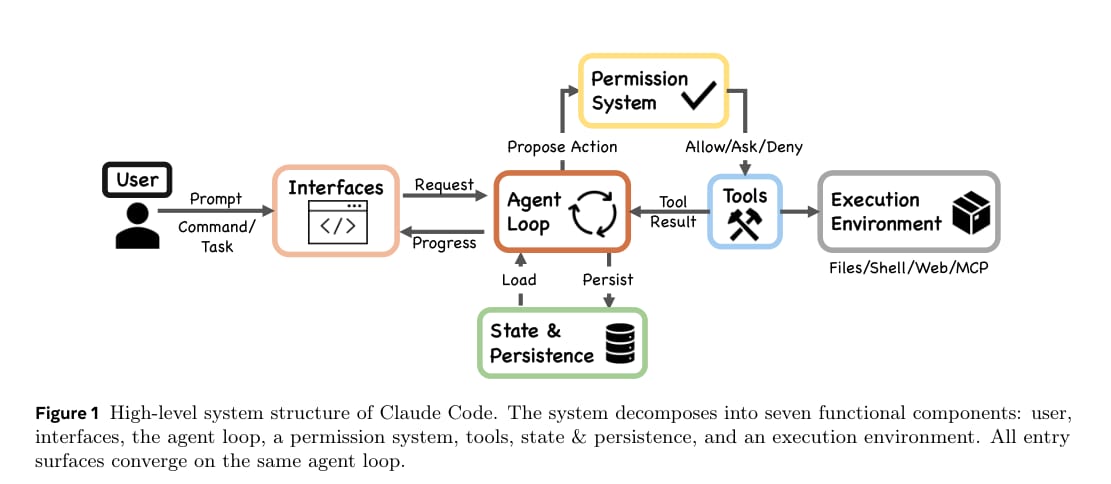
这张图说明了 Claude Code 的基本数据流:用户通过 CLI、SDK 或 IDE 等入口提交任务;任务进入 Agent 循环;模型提出工具调用;权限系统决定允许、询问或拒绝;工具在执行环境中运行,并将结果返回给循环。
这里最重要的结论是:所有入口最终汇聚到同一个 Agent 循环。交互式终端、无头 CLI、SDK 和 IDE 集成都只是不同的表层入口,核心执行路径保持一致。
核心循环:简单 while-loop,复杂外围系统
论文反复强调,Claude Code 的核心 Agent 循环并不复杂。它本质上是:
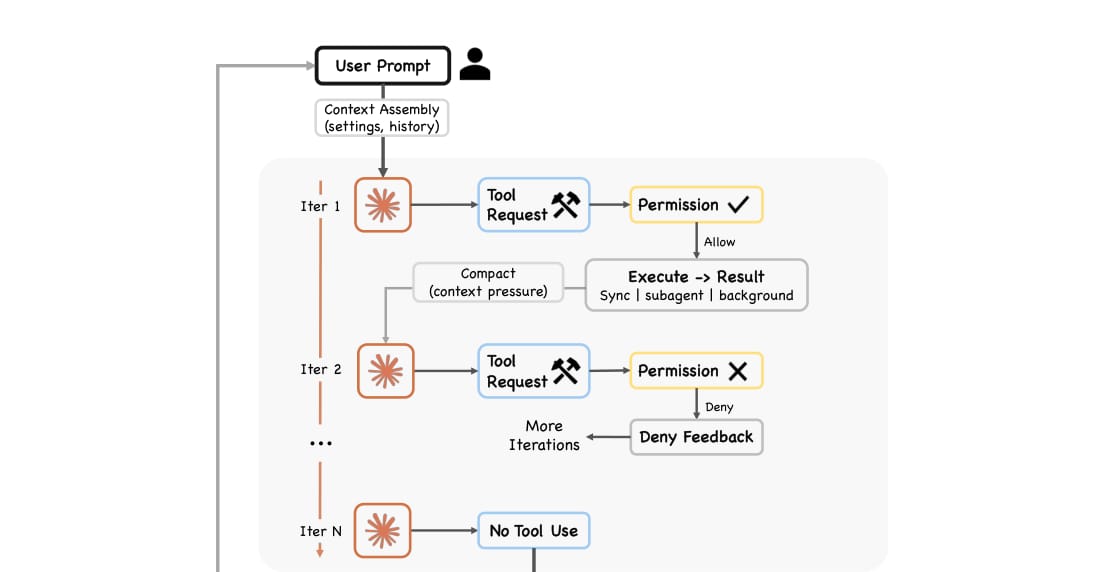
这个循环的关键不在于手写复杂规划,而在于模型每轮根据上下文决定是否继续调用工具。如果模型不再产生工具调用,则循环结束并返回最终答复。
论文给出的判断很重要:Claude Code 只有很少一部分代码直接属于 AI 决策逻辑,绝大多数代码是运行时基础设施。论文引用的社区估计认为,约 1.6% 的代码是决策逻辑,其余 98.4% 是操作性 harness。
这意味着生产级 Agent 的工程重点不是堆叠更多规划器,而是构建稳定的工具执行、安全控制、上下文管理和恢复机制。
五层子系统结构
在七个高层组件之外,论文进一步给出五层架构:表层、核心层、安全与动作层、状态层、后端层。
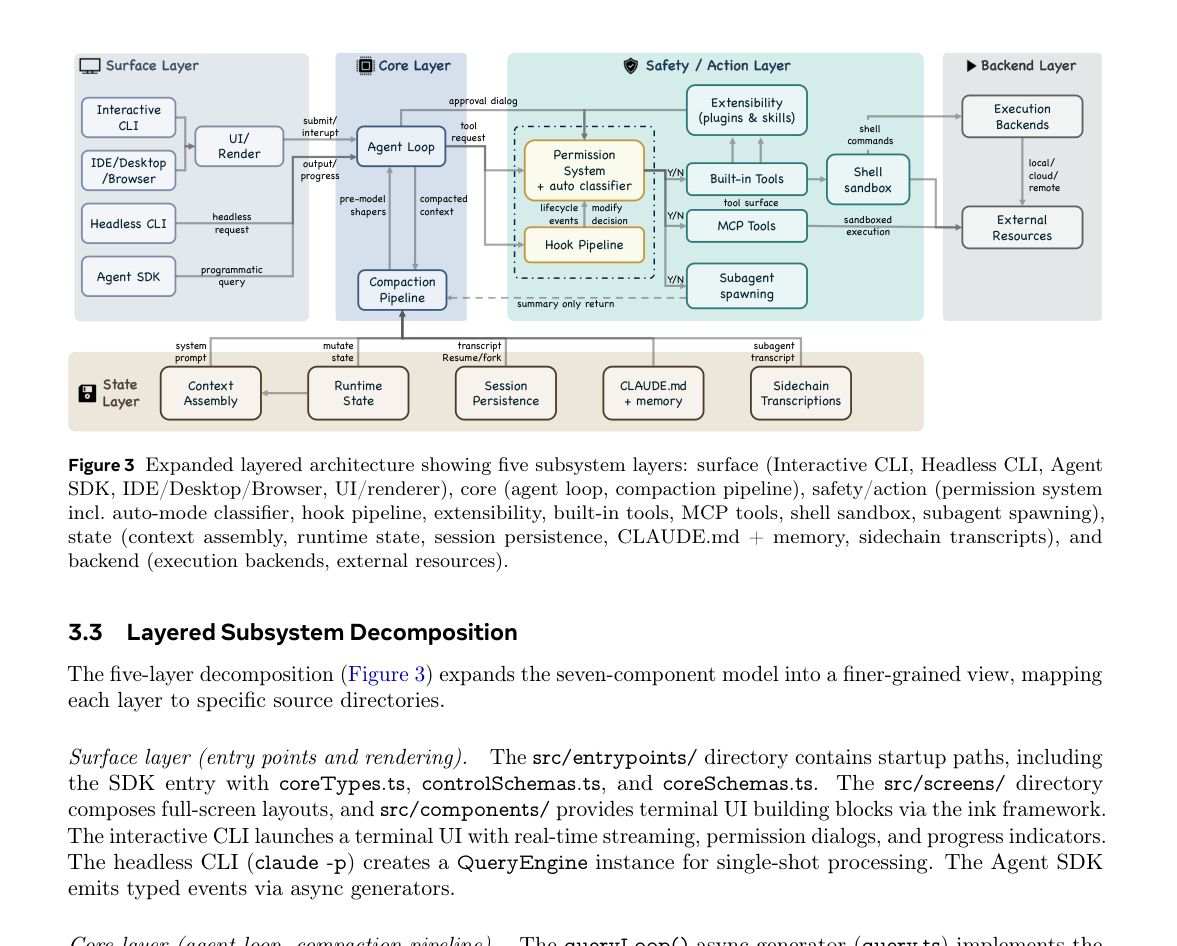
这五层可以这样理解:
表层:交互式 CLI、无头 CLI、Agent SDK、IDE 或浏览器入口;
核心层:Agent 循环和上下文压缩管线;
安全与动作层:权限系统、Hook、插件、技能、MCP 工具、内置工具、子代理和沙箱;
状态层:上下文组装、运行时状态、会话持久化、
CLAUDE.md和 memory;后端层:Shell、文件系统、远程执行、MCP 服务和外部资源。
该结构的意义在于,它把 Agent 系统从“模型调用工具”的简单图景,扩展成一个完整的软件系统。模型只是其中一个组件,系统可靠性主要取决于外围工程层。
权限系统:默认拒绝,而不是默认信任
Claude Code 的权限系统体现了论文中最重要的安全设计原则:deny-first with human escalation。
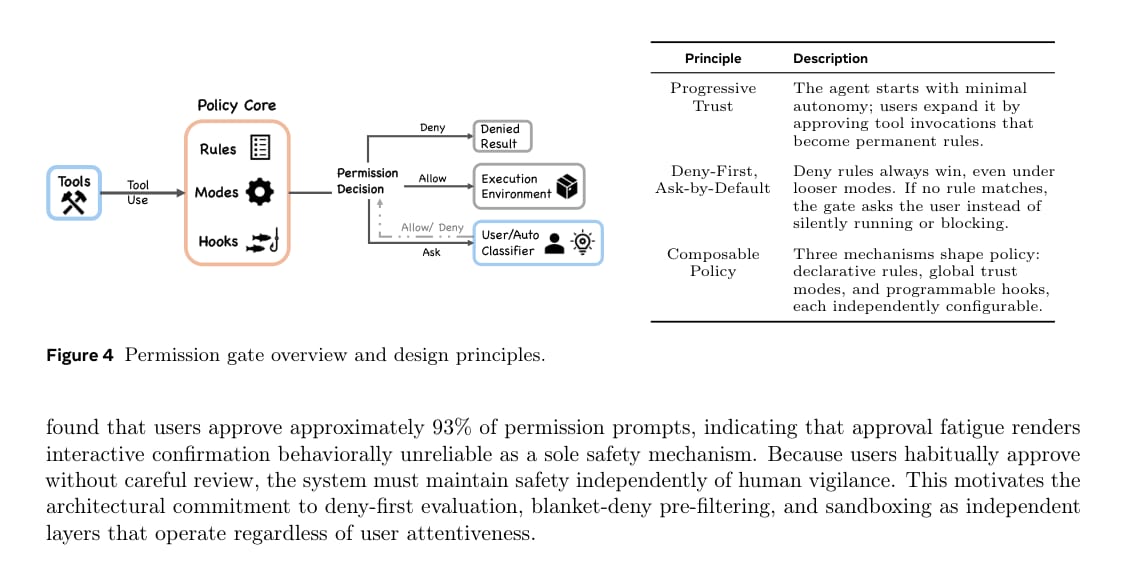
权限系统并不是单一开关,而是由规则、模式、Hook、执行环境和自动分类器共同组成。论文指出,Claude Code 的权限决策包含允许、拒绝和询问三类结果。拒绝规则优先级最高,即使存在允许规则也不能覆盖拒绝规则。
论文还讨论了一个现实问题:用户对权限弹窗会产生疲劳。文中引用 Anthropic 分析指出,用户大约会批准 93% 的权限请求。因此,安全不能完全依赖用户每次认真审查,而必须由系统层面的拒绝规则、分类器、沙箱和 Hook 共同承担。
这给 Agent 系统设计带来一个直接启发:交互式确认不是安全机制的全部,它只能作为安全链路中的一环。
扩展机制:MCP、插件、技能和 Hook 各有位置
Claude Code 不是只提供一种扩展方式,而是同时提供 MCP、plugins、skills 和 hooks。

论文将这些机制按上下文成本区分:
Hook 基本不消耗模型上下文,可以在工具调用前后执行确定性逻辑;
Skill 以
SKILL.md形式向模型提供任务相关能力说明,消耗较低上下文;Plugin 更偏向组件和功能注册;
MCP 提供外部工具和服务接入,但会增加工具描述和调用面的上下文成本。
这个分析很有价值。它说明扩展机制不能只看“能不能接入工具”,还要看接入方式对上下文窗口、安全边界和可调试性的影响。
上下文与记忆:上下文窗口是稀缺资源
论文把上下文窗口视为 Claude Code 的核心资源约束。即使模型支持很长上下文,生产系统仍然需要精细管理。
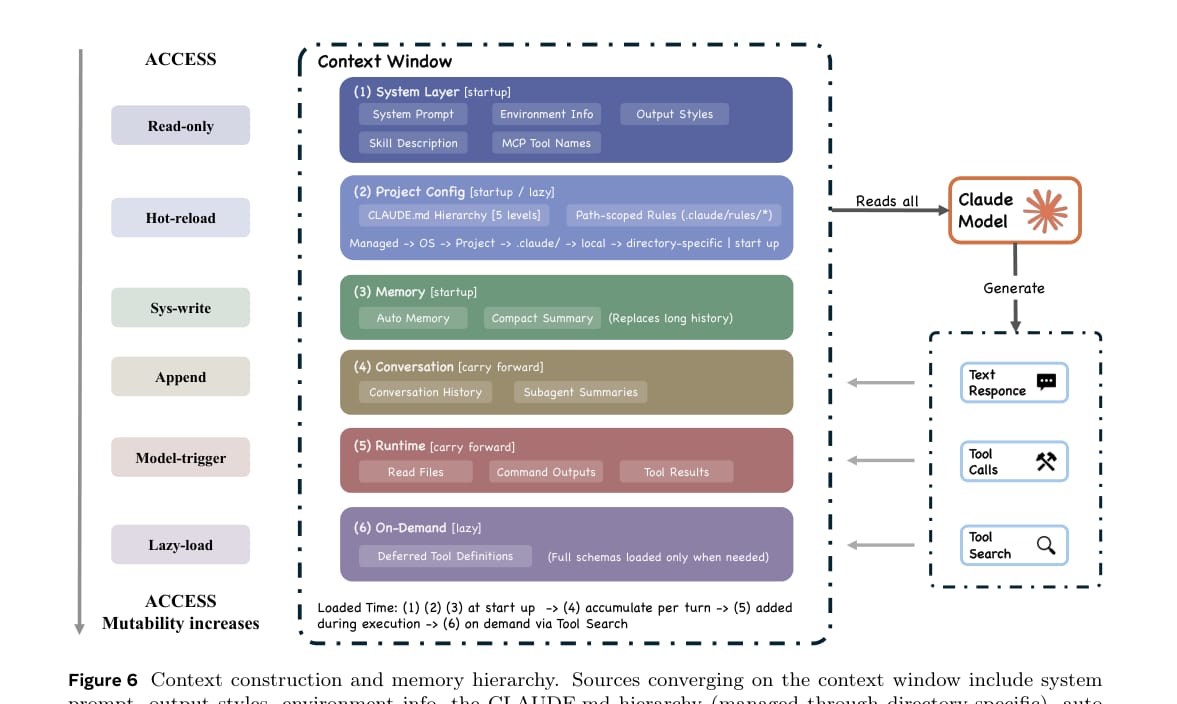
Claude Code 的上下文管理包括两个方面。
第一,系统会加载多层 CLAUDE.md、用户上下文、项目状态和工具描述。这些内容共同构成模型调用前的上下文。
第二,系统使用五层压缩管线管理上下文压力,包括预算缩减、snip、microcompact、context collapse 和 auto-compact。越靠后的压缩越重,代价也越高。
论文的判断是:上下文管理不是简单截断历史,而是一个渐进式压缩系统。它试图在保留任务连续性的同时,避免上下文窗口被历史消息、工具输出和子代理探索结果耗尽。
子代理:隔离上下文,而不是共享所有信息
Claude Code 的子代理机制用于任务委派。父代理可以派生 Explore、Plan、general-purpose 或自定义子代理。
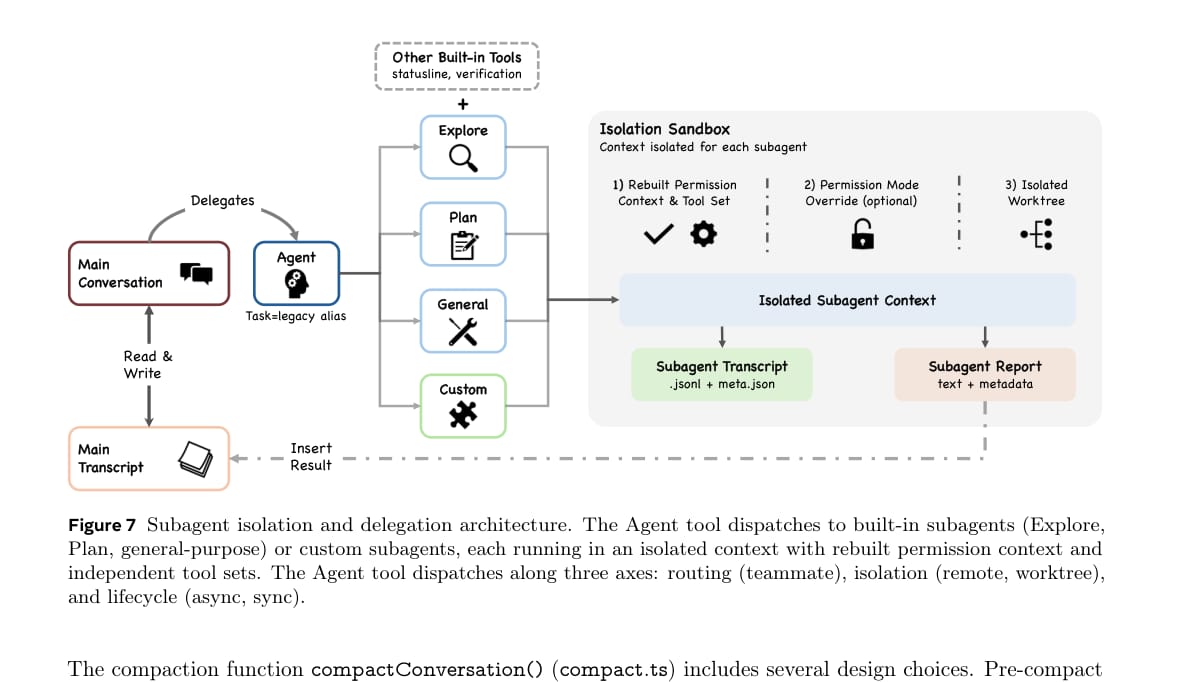
论文强调,子代理并不是简单共享父代理上下文。它们拥有独立上下文窗口、受限工具集和单独的 sidechain transcript。子代理完成任务后,通常只把总结结果返回给父代理。
这种设计有两个好处。第一,探索过程不会污染父代理上下文。第二,子代理权限和工具边界可以更清晰。
但它也有代价。由于子代理之间缺少全局视野,多个代理可能重复实现相同逻辑,或者产生局部正确但全局不一致的修改。
会话持久化:可审计优先于可查询
Claude Code 使用近似 append-only 的 JSONL transcript 保存会话。
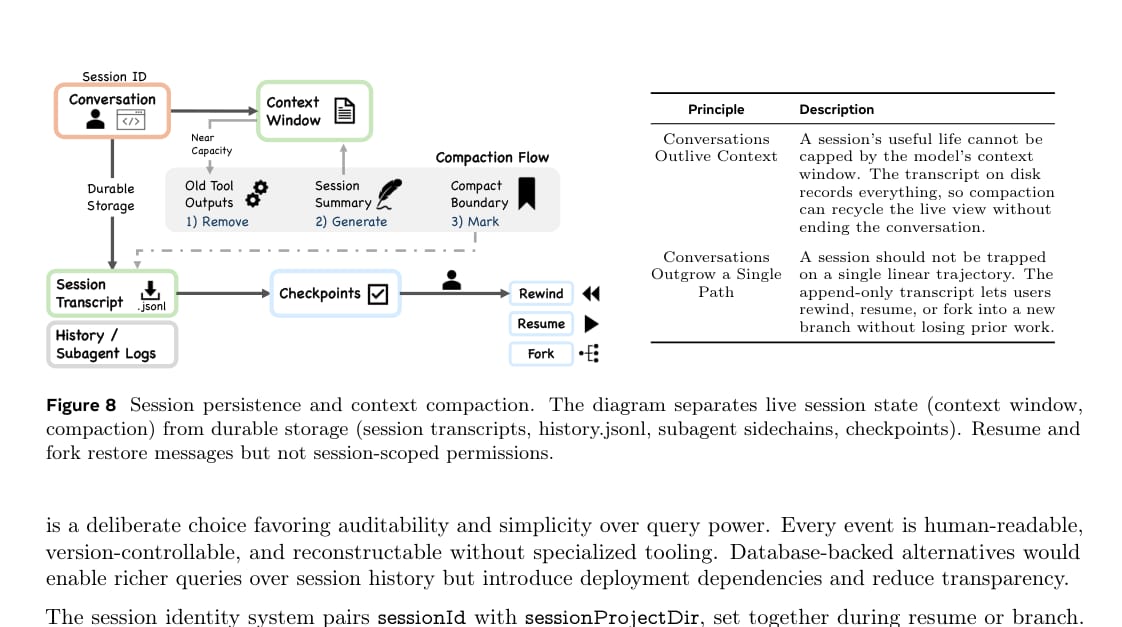
论文指出,会话可以恢复、分叉和回放,但 session-scoped permissions 不会自动恢复。也就是说,即使用户恢复一个旧会话,也需要重新授予权限。
这个设计体现了安全优先原则。恢复权限会提升便利性,但也可能把旧环境中的信任决策带入新上下文。Claude Code 选择重新授权,以避免过期权限隐式延续。
同时,append-only transcript 也有明确取舍。它便于人工查看、版本控制和审计,但不如数据库适合复杂查询。例如,跨会话检索“所有修改过某文件的工具调用”需要额外重构。
与 OpenClaw 的架构对比
论文没有把 Claude Code 当作唯一答案,而是将其与 OpenClaw 对比。这个对比用于说明:相同的 Agent 设计问题,在不同部署场景下会产生不同架构。

Claude Code 是仓库绑定的 CLI/IDE 编码 harness,核心是单个 Agent 循环。OpenClaw 是持久运行的 WebSocket 网关,面向 WhatsApp、Telegram、Slack、Discord 等多渠道个人助手场景。
二者的差异主要体现在六个维度:
Claude Code 强调每次工具调用的权限判断;OpenClaw 强调网关入口的身份和访问控制;
Claude Code 的 Agent 循环是系统中心;OpenClaw 的 Agent 运行时嵌入网关控制平面;
Claude Code 的扩展机制服务于单个上下文窗口;OpenClaw 的插件扩展整个网关能力面;
Claude Code 重视渐进式上下文压缩;OpenClaw 更重视结构化长期记忆;
Claude Code 的多 Agent 更像任务委派;OpenClaw 可以路由多个相互独立的 Agent 实例。
论文由此得出一个重要结论:Agent 系统设计不是平面分类,而是分层组合。OpenClaw 可以通过 ACP 接入 Claude Code,因此网关级系统和任务级 harness 可以组合,而不是互斥。
论文的关键结果
这篇论文的结果不是模型指标,而是架构分析结论。最重要的结果有五个。
第一,Claude Code 的设计点可以概括为“模型局部自治 + 确定性工程 harness”。模型负责判断下一步做什么,harness 负责权限、工具、上下文、恢复和持久化。
第二,Claude Code 的安全不是单点机制,而是多层叠加。权限规则、权限模式、Hook、自动分类器、沙箱和会话权限不恢复共同构成防线。
第三,上下文管理是生产级 Agent 的核心问题。Claude Code 使用五层压缩管线,而不是简单截断历史。
第四,可扩展性和安全性存在结构性张力。MCP、插件、技能和 Hook 提供了能力扩展,同时也扩大了攻击面和复杂交互。
第五,能力增强并不自动等于长期收益。论文特别提出“长期人类能力保持”这一评估视角,指出当前架构对用户理解能力、代码库一致性和开发者成长的保护机制仍然有限。
论文用表格总结了不同价值之间的张力。
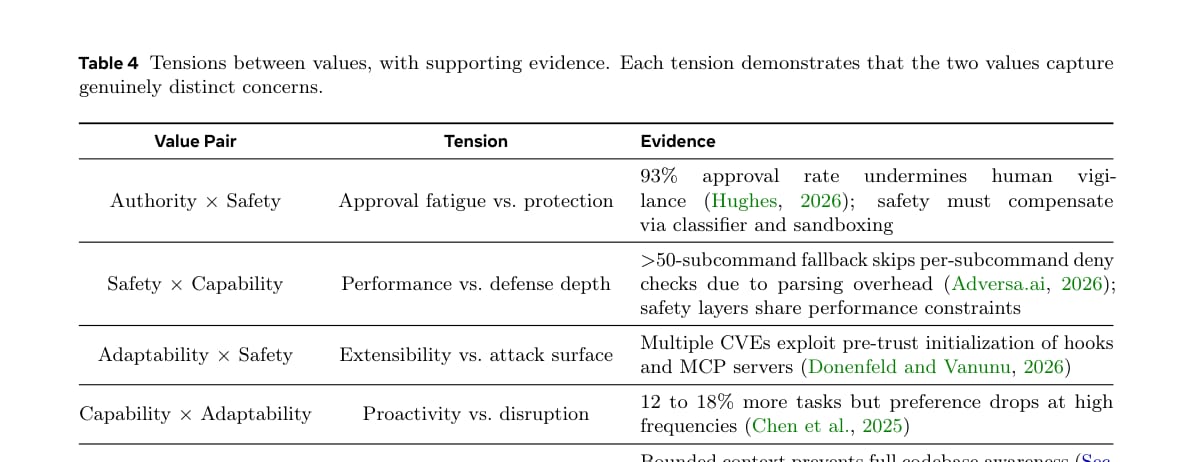
其中最值得注意的是“能力放大”和“可靠性”的冲突。Agent 可以提升短期速度,但受限上下文和子代理隔离可能导致重复实现、风格漂移和复杂度增加。
局限性
论文也明确说明了自身局限。
第一,分析对象是 Claude Code v2.1.88 的静态快照。由于特性开关和构建目标存在差异,其他版本可能有不同实现。
第二,源码能揭示结构、控制流和模块边界,但不能完全确认 Anthropic 的真实设计意图、生产环境开关或未发布行为。
第三,论文主要分析 Claude Code 一个系统。它能说明一个重要设计点,但不能代表所有编码 Agent。
第四,OpenClaw 只是对比对象,用于校准设计空间,而不是 Claude Code 的实现参照。
这些局限不削弱论文价值,反而说明它更接近软件架构案例研究,而不是普适定律。
未来工作
论文提出六个未来方向。
第一,解决静默失败和评估缺口。当前系统能记录工具调用和会话轨迹,但缺少足够强的离线评估与错误检测机制。
第二,发展跨会话持久记忆。未来 Agent 需要介于静态指令和单次会话 transcript 之间的长期记忆层。
第三,扩展 harness 边界。Agent 不只会在本地终端行动,也可能在云端、后台、多模态环境和多代理系统中行动。
第四,支持更长时间尺度的任务。从单轮、单会话扩展到跨天、跨周甚至科研项目级任务,需要新的协调和记忆机制。
第五,应对治理和合规要求。随着 Agent 自主性增强,日志、透明性、审计和人工监督会成为架构的一部分。
第六,将长期人类能力保持作为一等设计问题。未来系统不能只优化短期任务完成率,还要考虑用户是否仍然理解代码、掌握系统、保持判断能力。
对 AI Agent 系统设计的启发
这篇论文对个人构建 Agent 系统有几个直接启发。
第一,不要把 Agent 系统理解成“模型 + 工具列表”。真正决定体验和可靠性的,是工具调用前后的工程系统。
第二,安全策略要分层设计。单靠用户确认、单靠沙箱或单靠模型判断都不充分,必须组合规则、权限、隔离、审计和恢复机制。
第三,上下文管理应尽早设计。随着工具调用、日志、图片、代码和多轮讨论增加,上下文窗口很快会成为瓶颈。
第四,扩展机制需要区分成本。Hook 适合确定性控制,Skill 适合低成本能力说明,MCP 适合外部工具接入,但会带来更高上下文和安全成本。
第五,子代理不能只追求并行。子代理需要边界、汇总协议和一致性检查,否则容易产生局部正确但全局割裂的结果。
第六,Agent 产品不能只看任务完成。对编码场景而言,代码库一致性、可审计性、可恢复性和人的理解能力同样重要。
小结
这篇论文最重要的观点是:生产级 AI Agent 的核心竞争力不只来自模型能力,而来自围绕模型构建的确定性工程 harness。
Claude Code 的架构选择可以概括为:让模型保持较高局部自治,同时用权限系统、上下文压缩、扩展机制、子代理隔离和会话持久化限制风险并提高可靠性。
这对 Agent 开发者具有直接参考价值。构建一个可用 Agent,重点不是先设计复杂规划图,而是先回答几个基础问题:工具如何执行,权限如何控制,上下文如何压缩,状态如何恢复,扩展如何接入,错误如何被发现。
论文最后的判断也值得保留:未来 Agent 系统最关键的问题可能不是继续增加自主性,而是如何在增强能力的同时,保持人的理解、判断和长期成长。
相关文章
暂无相关文章