
RAG多模态数据处理与NotebookLM知识助手实践
摘要
本文记录一个多模态 RAG 知识助手的实现过程。项目以迪士尼客服知识库为例,完成 Word/PDF/图片/视频的统一处理,使用多模态 Embedding 和 FAISS 构建索引,并通过 Query 检索、媒体意图识别和 LLM 生成完成问答闭环。
RAG 多模态数据处理与 NotebookLM 知识助手实践
写在前面
RAG 解决的是知识边界问题。大模型本身可以生成流畅回答,但它不知道业务资料的最新版本,也无法保证答案一定来自指定材料。RAG 的作用是把外部知识库接入模型推理过程,让回答有依据、可追溯、可更新。
这次项目做的是一个多模态知识助手。示例业务是迪士尼客服,知识库包含 Word 文档、PDF、活动图片和视频链接。系统需要回答文本问题,也需要在用户询问海报或视频时返回对应媒体资料。
这类项目的关键不是调用某个大模型 API,而是把不同格式的数据变成统一、可检索、可回溯的知识对象。
项目做了什么
项目完成了一个原生多模态 RAG 流程。输入端处理文档、图片和视频,索引端用统一多模态 Embedding 生成向量,检索端用 FAISS 做相似度搜索,生成端用大模型组织最终回答。
最终系统支持三类问题。
问题类型 | 示例 | 系统行为 |
|---|---|---|
文本问答 | 迪士尼门票退款流程是什么 | 检索 Top-K 文本,生成结构化回答 |
图片查询 | 最近万圣节活动海报是什么 | 检索文本,同时匹配相关图片 |
视频查询 | 我的汽车被剐蹭了,能看到视频吗 | 检索文本,同时匹配相关视频链接 |
项目输出不是一个简单聊天机器人,而是一个可复现的 RAG 工程链路。核心文件包括向量索引 disney_index.faiss 和元数据 disney_metadata.json。
方法设计
整体架构如下。
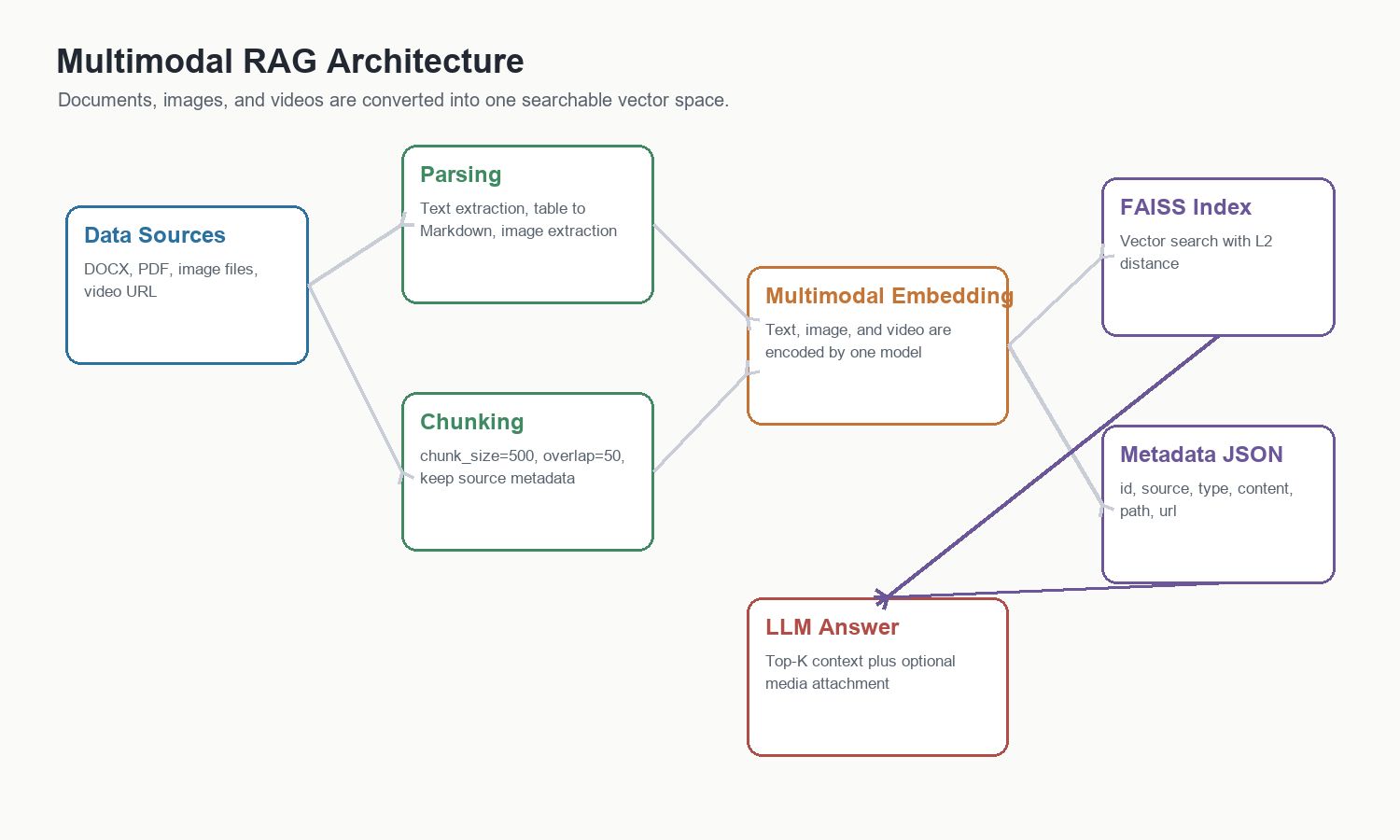
这个系统分为五个部分。
模块 | 作用 |
|---|---|
数据源 | Word、PDF、图片文件、视频 URL |
解析与切片 | 提取文本、表格、图片,按策略切成 chunk |
多模态向量化 | 文本、图片、视频用同一个模型进入统一向量空间 |
索引与元数据 | FAISS 存向量,JSON 存来源、类型、路径和内容 |
生成回答 | Top-K 文本构造上下文,图片或视频作为附件补充 |
这里没有使用 LangChain。原因很简单:这个项目重点是理解 RAG 底层链路。文档怎么处理,向量怎么生成,索引怎么保存,媒体结果怎么筛选,都需要直接看清楚。
数据层:解析文档和媒体
数据层先把原始材料转成统一内容块。这里不做复杂推理,只做结构化处理。
Word 文档分两类处理。普通段落提取为文本 chunk,表格转为 Markdown 表格。表格不能直接压成一段纯文本,否则表头和行列关系会丢失。
PDF 按页处理。每页提取文本,同时提取嵌入图片。图片保存到本地目录,元数据记录来源文件、页码和图片路径。
图片直接作为图像对象入库。视频在课程示例中以 URL 形式处理;如果是本地视频,可以先抽取关键帧,再对多帧向量取平均。这个方案不完美,但足够完成原型验证。
切片层:控制召回粒度
本项目使用固定长度切片。
固定长度切片适合快速验证。它实现简单,长度稳定,批量处理成本低。缺点是可能切断语义,所以加了 50 字符重叠,减少边界信息丢失。
更完整的切片策略如下。
策略 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
固定长度切片 | 简单稳定 | 可能切断语义 | 原型、批量处理 |
句子边界切片 | 语义完整 | 长度不均匀 | 自然语言问答 |
LLM 语义切片 | 分块质量高 | 成本高、速度慢 | 小规模高质量知识库 |
层次切片 | 保留文档结构 | 依赖标题格式 | 手册、制度、API 文档 |
滑动窗口切片 | 上下文连续 | 冗余多 | 长文档召回 |
这里的经验是:不要一开始就追求复杂切片。先用固定长度跑通,再用真实问题集评估召回错误。如果错误来自语义断裂,再升级到层次切片或语义切片。
向量化层:统一多模态空间
文本、图片、视频要能一起检索,前提是它们进入同一个向量空间。本项目使用 tongyi-embedding-vision-plus 作为多模态 Embedding 模型。PPT 示例中的向量维度为 1152。
文本直接编码。图片先读成 Base64,再提交给模型。视频使用 URL 输入,或者抽帧后得到多个向量,再做平均。
这样做以后,文本问题可以和图片、视频计算语义距离。比如用户问万圣节海报,系统可以在同一个索引中找到图片类型的结果。
索引层:FAISS 加元数据
FAISS 只负责存向量和做相似度检索。业务信息必须放到元数据里。
索引构建完成后,系统保存两个文件。
运行结果如下。

这次构建结果比较小,但链路完整。系统处理了 4 个 Word 文档、2 张图片和 1 个视频,最终得到 9 个文本 chunk、2 个图片对象和 1 个视频对象。向量维度为 1152。
查询层:先统一检索,再按意图筛选
Query 处理流程如下。

系统先把用户问题编码成向量,再对 FAISS 中所有向量做检索。检索结果中可能同时包含文本、图片和视频。文本结果默认取 Top-K 进入 Prompt,媒体结果需要经过意图判断。
媒体意图先用关键词实现。
如果问题包含图片意图,就从检索结果中筛选 type == image 且距离小于阈值的结果。如果问题包含视频意图,就筛选 type == video 的结果。文本不做意图过滤,因为文本始终负责回答 grounding。
这个策略不复杂,但它解决了一个关键问题:媒体结果不能无条件进入回答。否则用户问门票退款,系统可能附带一个无关活动海报。
生成层:Prompt 只放必要上下文
最终 Prompt 由两部分构成。第一部分是 Top-K 文本片段,第二部分是媒体匹配结果。大模型只负责基于检索内容组织回答,不负责判断知识库中是否存在某个资料。
这里有一个边界:媒体匹配只是检索结果,不等于模型真正理解了图片或视频内容。如果要让模型分析图片本身,还需要把图片再次传给多模态大模型做内容理解。本项目主要验证跨模态检索和附件返回。
结果演示
第一个结果是索引创建。系统输出了文档长度、chunk 数量、图片和视频处理记录,并保存索引文件和元数据文件。这个结果说明数据层、向量层和持久化流程已经跑通。
第二个结果是图片查询。用户问题是最近万圣节的活动海报是什么。系统检索后识别到图片意图,匹配到 2-万圣节.jpeg,距离为 1.5501,相似度为 0.3921。

这个结果说明统一索引可以支持以文搜图。文本问题没有直接包含图片文件名,但能通过语义向量找到相关图片。
第三个结果是视频查询。用户问题是我的汽车被剐蹭了,你能看到视频么。系统识别到视频意图,匹配到汽车剐蹭视频,距离为 1.5424,相似度为 0.3933。

这个结果说明视频也可以作为知识库对象参与召回。需要注意的是,客服回答不能越权判断事故责任。比较稳妥的回答是提示用户联系游客服务中心、保留证据并走人工处理流程。
NotebookLM 的作用
NotebookLM 在这里不是工程实现的一部分,而是一个对照工具。它适合快速把一组资料变成可问答的 Notebook,并且能给出来源引用,非常适合日常学习使用。
它适合资料阅读、课程总结、制度问答、轻量知识助手。不适合做私有化部署、权限控制、业务系统集成和自定义检索策略。
维度 | NotebookLM | 原生 RAG |
|---|---|---|
上手成本 | 低 | 高 |
来源引用 | 内置 | 需要自己实现 |
检索策略 | 不可控 | 可控 |
多模态处理 | 产品内置能力 | 需要自己设计 |
系统集成 | 弱 | 强 |
适用场景 | 资料阅读和轻量问答 | 生产系统和业务闭环 |
结论
这个项目实际做了四件事。
第一,把 Word、PDF、图片和视频统一转成可检索对象。第二,用多模态 Embedding 把不同模态映射到同一向量空间。第三,用 FAISS 和元数据文件实现本地检索。第四,在查询阶段加入媒体意图识别,让文本回答和媒体附件分开处理。
当前版本已经跑通原型,但还不是生产级系统。后续需要补三类能力。
方向 | 需要补充的内容 |
|---|---|
评估 | 标准问题集、召回准确率、媒体匹配准确率 |
来源 | 每个回答附带来源文件、页码、chunk id |
工程 | 增量更新、索引版本管理、异常处理、权限控制 |
我的理解是,多模态 RAG 的难点不在模型,而在数据和验证。模型可以替换,索引可以替换,但数据结构、元数据、切片策略和评估集必须从一开始设计清楚。