
SkillRouter: Skill Routing for LLM Agents at Scale 论文阅读
摘要
本文解读论文 SkillRouter: Skill Routing for LLM Agents at Scale。论文研究大规模 skill registry 下的技能路由问题,指出完整 skill body 是关键检索信号,并提出一个 1.2B 全文 retrieve-and-rerank 路由系统,在准确率、延迟和端到端任务成功率之间取得较好平衡。
SkillRouter: Skill Routing for LLM Agents at Scale
写在前面
这篇论文研究的是 LLM Agent 中一个容易被低估的问题:当系统有几万甚至几十万个可复用 skill 时,Agent 应该如何找到当前任务真正需要的 skill。
论文题目为 SkillRouter: Skill Routing for LLM Agents at Scale。作者来自阿里巴巴,论文目前为 under review 预印本。
这篇论文的背景与 Claude Code、Codex、OpenClaw 等 Agent 系统直接相关。它们都在使用 skill 作为能力扩展单元:一个 skill 通常包含名称、描述、执行步骤、工具说明和实现约束。问题是,skill 越多,越不能把所有 skill 全部塞进模型上下文。
因此,系统必须先做 skill routing:给定用户任务,从大规模 skill 池中找出最相关的一小组 skill,再交给下游 Agent 使用。
论文一句话概括
SkillRouter 证明,在大规模且高度重叠的 skill 池中,只看 skill 名称和描述会显著降低路由准确率;完整 skill body 是关键路由信号。基于这一发现,论文提出一个 1.2B 的全文检索与重排序系统,在约 80K skill 池上达到 74.0% Hit@1,并且比 16B 基线推理更快。
论文要解决什么问题
在真实 Agent 系统中,skill registry 会快速膨胀。一个组织可能积累大量文档处理、代码生成、数据分析、图像处理、部署运维和科研辅助 skill。许多 skill 在名称和描述上相似,但功能边界并不相同。
例如,用户说“从本地教学视频中提取章节时间戳”,表面关键词是 video,但真正需要的可能是 speech-to-text,而不是视频剪辑工具。
论文用一个例子说明了这种混淆。

这个例子展示了三类候选:真实需要的 ground truth skill、普通干扰项和困难干扰项。困难干扰项看起来主题相关,但功能上不能完成任务。
这正是 skill routing 的难点:系统不能只匹配表面主题,而要理解任务需要的具体能力。
核心创新点与贡献
论文的贡献主要有三点。
第一,论文构建了一个接近真实部署场景的技能路由评估设置。核心基准包含约 80K 个候选 skill 和 75 个专家验证查询,并进一步区分 Easy 和 Hard 两个难度层级。Hard 层级加入了 780 个由 LLM 生成的功能相近但错误的干扰 skill。
第二,论文验证了一个关键结论:完整 skill body 对路由非常重要。移除 skill body 后,BM25、dense encoder 和 retrieve-and-rerank pipeline 的 Hit@1 都出现 31 到 44 个百分点下降。
第三,论文提出 SkillRouter。它不是新模型架构,而是一个面向大规模 skill 池的全文 retrieve-and-rerank recipe,包括全文检索、困难负样本挖掘、假负样本过滤和 listwise reranking。
这篇论文的价值不在于提出复杂新网络,而在于指出 Agent skill 系统中的一个关键工程瓶颈,并给出可复用的系统方案。
研究问题:为什么只看名称和描述不够
当前很多 Agent 框架采用 progressive disclosure:先只暴露 skill 名称和描述,完整 skill body 在真正使用时才加载。这种设计可以节省上下文,但也隐含一个假设:名称和描述足以完成 skill 选择。
论文系统检验了这个假设,结论是否定的。
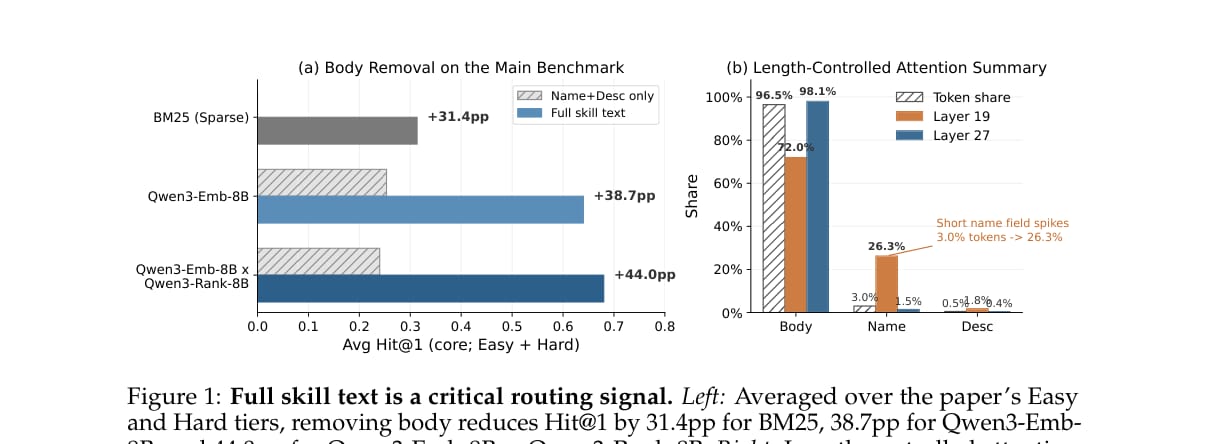
左图是核心结果:在 Easy 和 Hard 平均结果上,移除 body 后性能显著下降。
BM25 从 31.4% Hit@1 降到 0.0%;
Qwen3-Emb-8B 从 64.0% 降到 25.3%;
Qwen3-Emb-8B × Qwen3-Rank-8B 从 68.0% 降到 24.0%。
右图是注意力分析。虽然 body 占 skill token 的 96.5%,但模型并不是简单按字段长度分配注意力。中间层会明显关注短 name 字段,最终层又回到 body。这说明 body 提供的是实质性功能信息,而不是单纯因为文本更长。
这个发现是全文 SkillRouter 的基础。
方法:SkillRouter 的两阶段路由流程
SkillRouter 使用标准但有效的两阶段检索架构。
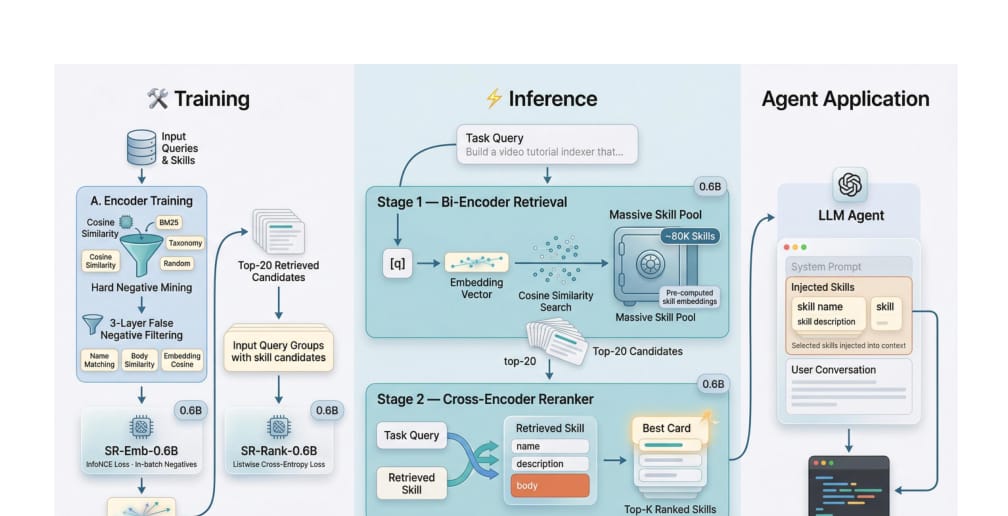
第一阶段是 bi-encoder retrieval。系统将用户 query 和完整 skill text 编码为向量,从约 80K skill 池中召回 top-20 候选。
第二阶段是 cross-encoder reranking。系统把 query 和每个候选 skill 的完整文本拼接输入 reranker,对 top-20 候选重新排序。
论文的主配置是:
SR-Emb-0.6B:基于Qwen3-Emb-0.6B微调的检索器;SR-Rank-0.6B:基于Qwen3-Rank-0.6B微调的重排序器;总参数量约 1.2B。
训练数据方面,作者从约 80K skill 池中分层采样 skill,并用 GPT-4o-mini 根据 skill 元数据和 body 生成 37,979 个合成 query-skill 对。基准中的标注 skill 被排除在训练监督之外,以减少记忆测试集的风险。
训练关键:困难负样本、假负样本过滤和 listwise loss
SkillRouter 的有效性不只来自“用全文”,还来自适合 skill 池特点的训练方式。
第一,论文使用困难负样本挖掘。每个 query 配 10 个负样本,包括语义近邻、BM25 词面匹配、同类目干扰项和跨类目随机负样本。这样可以让模型学习区分功能相近但不等价的 skill。
第二,论文进行假负样本过滤。大规模社区 skill 池中常有多个不同作者实现相同能力。如果把这些功能等价 skill 当成负样本,会破坏对比学习信号。论文使用名称去重、body trigram Jaccard 相似度和 embedding 相似度三层过滤,移除约 10% 的 mined negatives。
第三,reranker 使用 listwise cross-entropy,而不是 pointwise binary classification。原因是 top-20 候选通常都表面相关,reranker 需要比较候选之间的相对优劣,而不是独立判断每个候选是否相关。
主实验结果:小模型通过任务化训练超过大基线
论文首先比较 encoder-only retrieval。
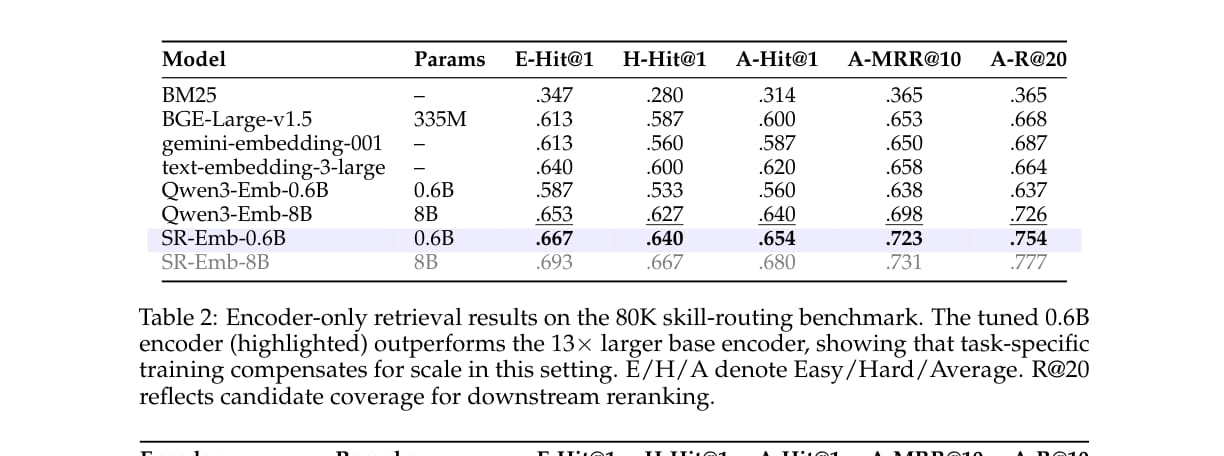
结果显示,SR-Emb-0.6B 达到 65.4% 平均 Hit@1,高于同规模 Qwen3-Emb-0.6B 的 56.0%,也略高于 13 倍参数量的 Qwen3-Emb-8B 的 64.0%。
这说明在这个任务中,任务化训练和困难负样本比单纯扩大模型规模更关键。
然后论文比较完整 retrieve-and-rerank pipeline。
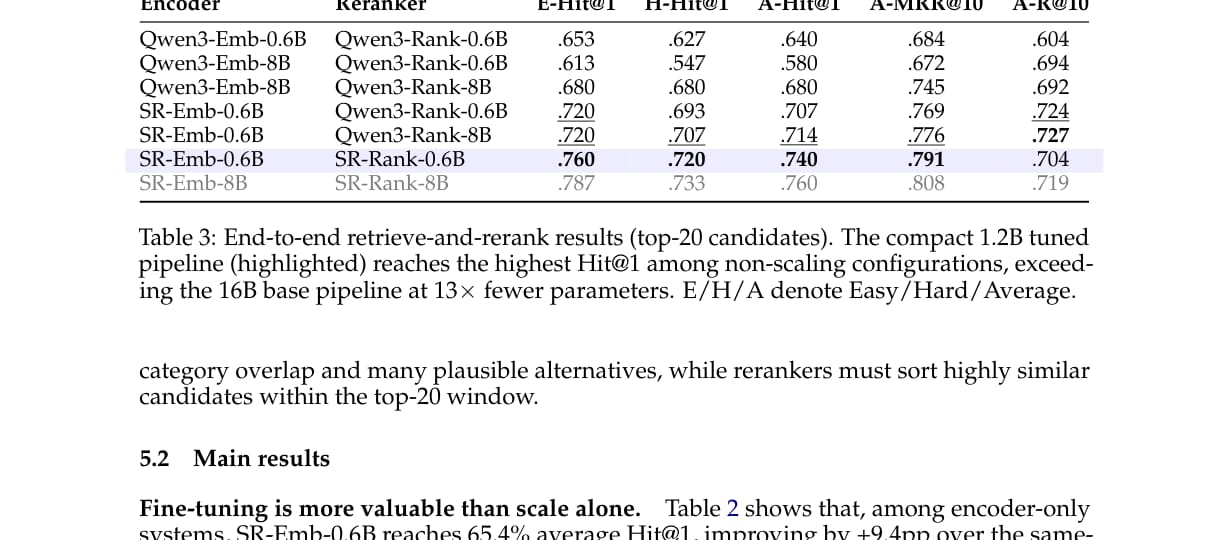
主配置 SR-Emb-0.6B × SR-Rank-0.6B 达到 74.0% 平均 Hit@1。相比之下,最强 16B 基线 Qwen3-Emb-8B × Qwen3-Rank-8B 为 68.0%。
这意味着 1.2B SkillRouter 在参数量少 13 倍的情况下,取得了更高 top-1 路由准确率。
需要注意的是,论文对自己的结论比较克制。它强调 SkillRouter 最强的是 top-1 routing,而不是所有指标都绝对领先。
单技能与多技能任务表现
SkillBench 中既有单技能任务,也有多技能任务。论文单独报告了这两类任务的表现。
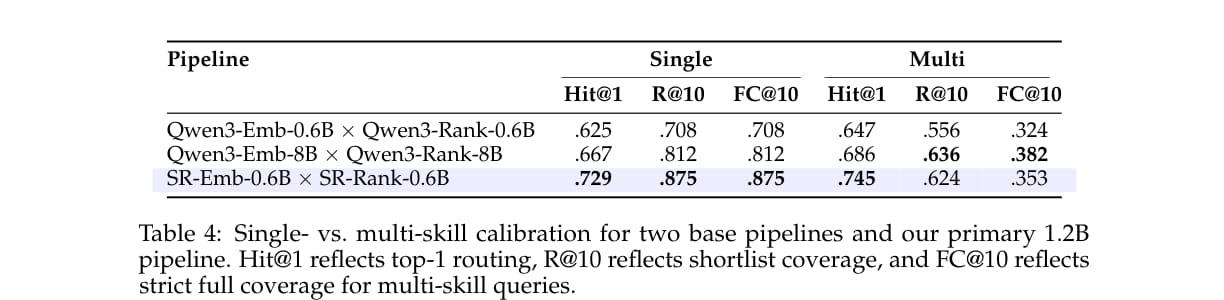
SkillRouter 在 single 和 multi 查询上都提升 Hit@1。对于多技能任务,它的 Hit@1 达到 74.5%,高于 16B 基线的 68.6%。
但在严格的 FC@10 指标上,16B 基线更高。FC@10 衡量的是多技能任务中完整 ground-truth skill set 是否全部出现在 top-10 中。SkillRouter 的 top-1 更强,但完整集合覆盖并非全面领先。
这一点很重要:如果下游 Agent 只看 top-1,SkillRouter 优势明显;如果任务需要完整技能集合,仍然需要更好的多技能覆盖机制。
消融实验:两个训练选择不可少
论文通过消融实验说明,假负样本过滤和 listwise reranking 是关键。
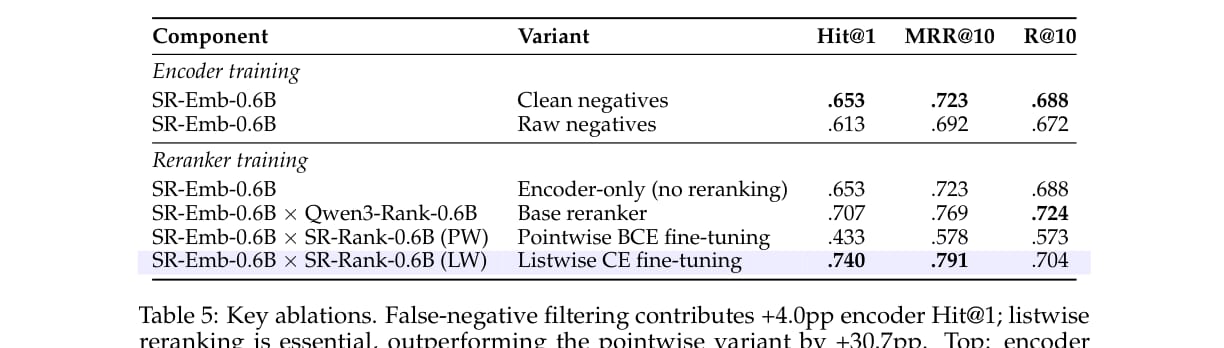
消融结果有两个重点:
假负样本过滤让 encoder Hit@1 从 61.3% 提升到 65.3%,贡献 4.0 个百分点;
listwise reranking 达到 74.0% Hit@1,而 pointwise BCE 只有 43.3%。
pointwise reranking 的失败尤其值得注意。在同质化候选池中,很多候选都“看起来相关”。如果模型只独立判断相关性,就容易给多个候选相近分数,最终排序不稳定。Listwise loss 更适合这种候选间精细竞争的场景。
端到端 Agent 评估:路由改进能否转化为任务成功
论文没有停留在检索指标,还做了端到端 Agent 执行评估。
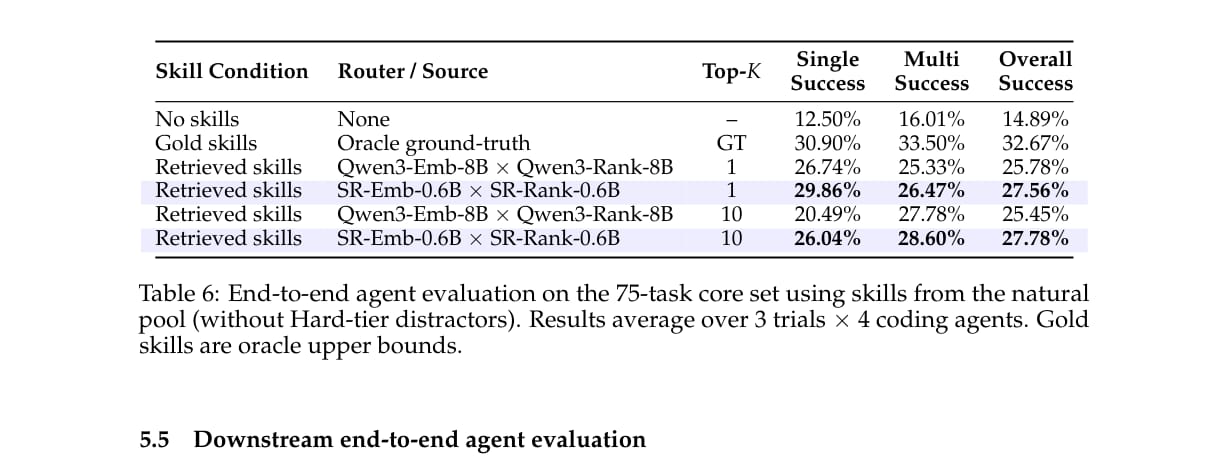
实验使用 4 个 coding agents:Kimi-K2.5、glm-5、Claude Sonnet 4.6 和 Claude Opus 4.6。每个任务运行在 Claude Code harness 中,超时时间为 1200 秒。
结果显示:
无 skill 时,总体成功率为 14.89%;
使用 oracle gold skills 时,总体成功率为 32.67%;
使用 16B 基线 top-1 检索 skill 时,总体成功率为 25.78%;
使用 SkillRouter top-1 时,总体成功率为 27.56%;
使用 SkillRouter top-10 时,总体成功率为 27.78%。
这说明更好的路由确实能提升下游 Agent 任务成功率,但提升幅度小于检索指标提升。这也符合直觉:正确 skill 只是成功执行的前提之一,Agent 本身是否能理解并使用 skill 仍然重要。
论文还指出,越强的 Agent 越能从更好的路由中受益。Claude Sonnet/Opus 4.6 的平均提升更明显,而较弱 Agent 可能即使拿到正确 skill,也不能充分利用。
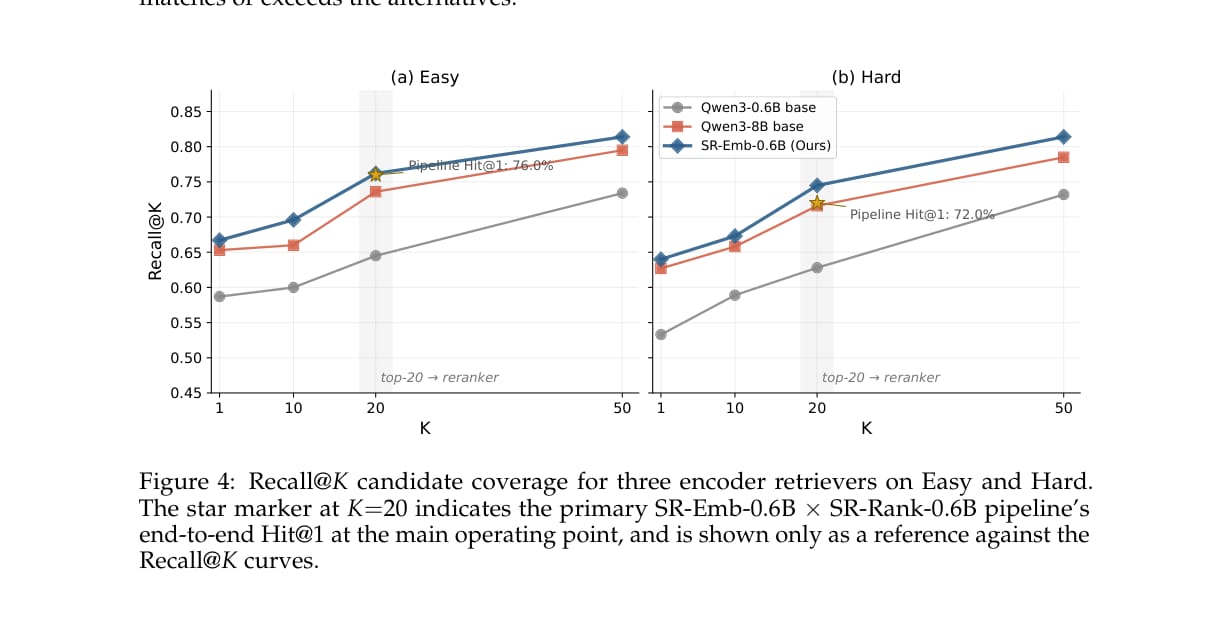
候选覆盖与效率
SkillRouter 选择 top-20 作为 reranking 候选规模。论文用 Recall@K 分析说明,K=20 已经能覆盖大部分可用候选,继续增大到 K=50 不一定提升最终 Hit@1,反而可能增加 reranker 排序难度。
效率方面,论文在真实 skill 池上测试了 80 个 query 的 GPU serving 表现。
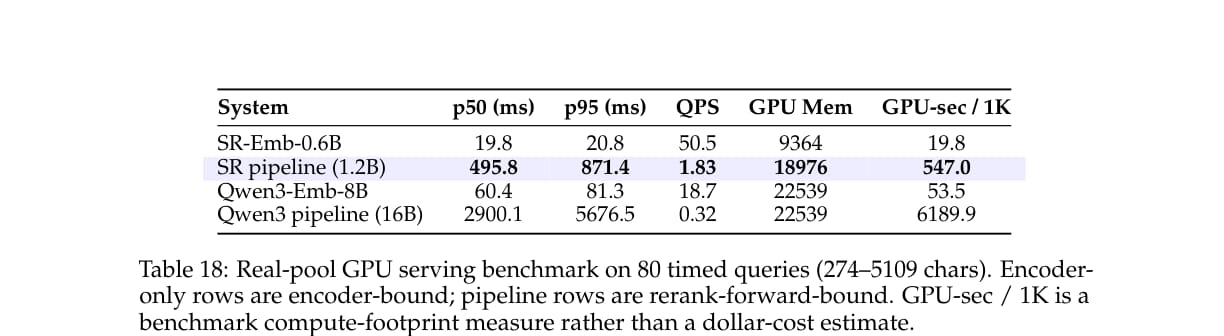
主配置 1.2B SkillRouter pipeline 的中位延迟为 495.8 ms,而 16B Qwen3 pipeline 为 2900.1 ms。论文据此报告 5.8 倍延迟优势,并且 GPU memory 使用更低。
这对实际系统很关键。Skill routing 是每次任务开始前的在线路径,如果路由器太慢,会直接影响 Agent 交互体验。
Reranker 到底修复了什么
论文进一步分解了 reranker 的贡献。
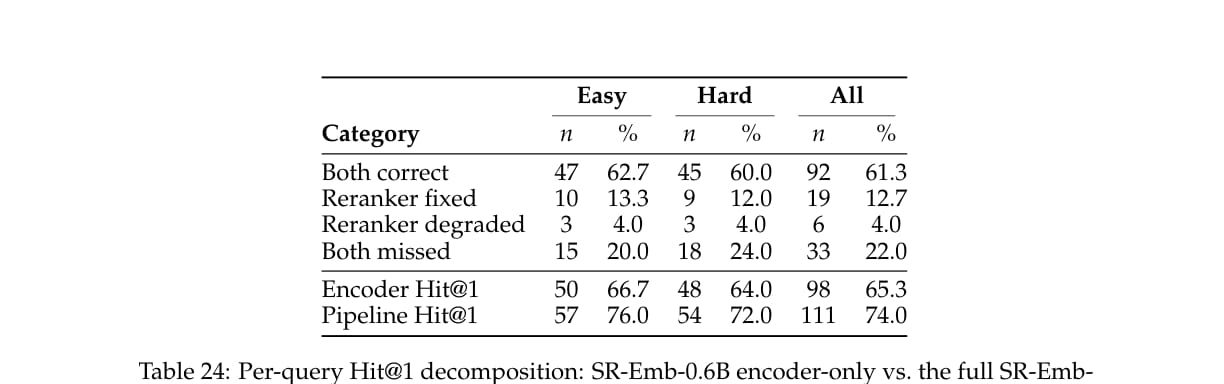
在 150 个 Easy + Hard 评估样本中:
encoder 和 pipeline 都正确:92 个;
reranker 修复 encoder top-1 错误:19 个;
reranker 反而降级:6 个;
二者都失败:33 个。
最终 pipeline Hit@1 从 encoder-only 的 65.3% 提升到 74.0%。
这说明 reranker 的价值主要在于:当正确 skill 已经进入 top-20,但不是第一名时,通过 cross-attention 读取完整 body,把它提升到第一。
剩余失败通常来自两类情况:正确 skill 未进入候选集,或者任务需要多跳前置推理。例如从“发票欺诈检测”推断到“需要 PDF 表格抽取”,这种链式需求不是简单语义检索容易解决的。
补充基准:结果是否只适用于核心 75 题
为了验证泛化性,论文构建了 SkillBench-Supp:一个包含 256 个单标签查询、77K skill 池的补充基准。
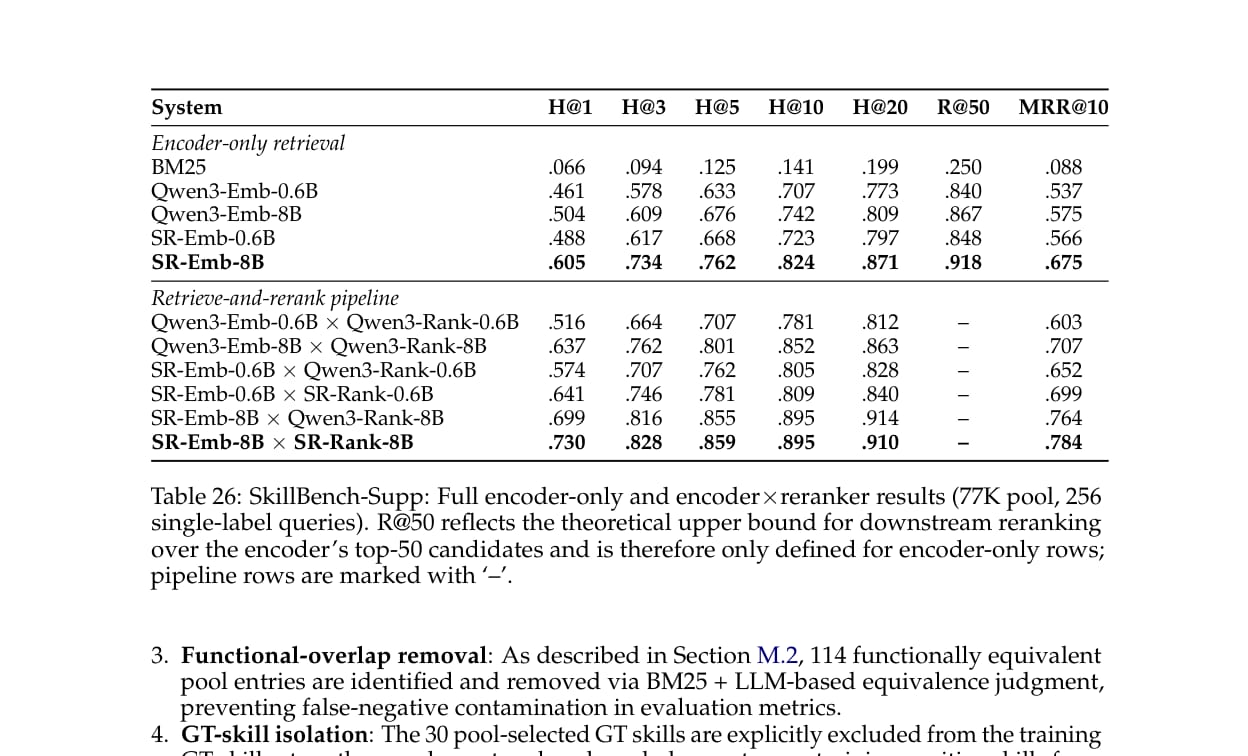
在该基准上,1.2B SkillRouter pipeline 的 Hit@1 为 64.1%,略高于 16B Qwen3 base pipeline 的 63.7%。8B SkillRouter 变体达到 73.0%。
这说明核心结论并非只适用于 75 个核心查询,但优势幅度会随基准构造变化。论文也因此没有把结论泛化为“所有 skill routing 场景都必须全文路由”,而是限定在“大规模、重叠度高的 skill registry”中。
论文结论
论文的结论可以概括为四点。
第一,在约 80K skill 的大规模池中,完整 skill body 是关键路由信号。只看名称和描述会造成显著性能下降。
第二,SkillRouter 的两阶段全文路由系统能以较小参数量取得强 top-1 routing 结果。1.2B 主配置达到 74.0% Hit@1,超过 16B 基线的 68.0%。
第三,训练细节对同质化 skill 池非常重要。假负样本过滤和 listwise reranking 是性能提升的关键组成。
第四,检索提升可以传导到端到端 Agent 成功率,但不是线性关系。Agent 是否能正确使用 skill,仍然取决于模型能力、任务复杂度和执行环境。
局限性
论文的局限主要有三点。
第一,基准来自有限数据源。结论主要适用于大规模、高重叠 skill 池;如果 skill 数量较少、名称描述质量较高,metadata-only routing 可能足够。
第二,端到端评估只覆盖 4 个 coding agents,并且使用单一执行预算。不同 harness、不同超时设置和不同任务类型可能产生不同结果。
第三,SkillRouter 对多跳前置推理仍然有限。它擅长在候选 skill 中识别功能匹配,但对“任务 A 需要先完成中间步骤 B,再需要 skill C”这类链式需求仍然不足。
此外,论文中的 FC@10 和端到端 top-10 success 衡量的不是同一件事。前者关注完整 gold skill set 覆盖,后者关注 bounded skill package 是否足以让 Agent 完成任务。
未来工作
这篇论文没有展开很长的未来工作,但从结果可以推出几个方向。
第一,多技能任务需要更强的集合路由。当前 SkillRouter 的 top-1 表现强,但多技能完整覆盖仍有提升空间。
第二,skill routing 需要结合任务分解。对于多跳需求,系统可能需要先推理任务链,再检索每个子步骤对应的 skill。
第三,skill body 的结构化表示值得进一步研究。当前方法把 name、description 和 body 展平为文本,未来可以显式建模工具、输入输出、约束、依赖和示例。
第四,路由结果需要与 Agent 执行反馈闭环。端到端成功率提升有限,说明路由器和执行 Agent 之间还可以通过失败轨迹、工具调用结果和验证信号共同优化。
第五,实际部署还需要考虑缓存、增量索引和权限过滤。企业级 skill registry 中,不同用户可见的 skill 集合不同,路由器必须与权限系统结合。
对 Agent 系统设计的启发
这篇论文对构建 Agent skill 系统有直接启发。
第一,skill 不能只写好名称和一句描述。真正决定可路由性的,往往是 body 中的具体步骤、工具边界、输入输出和适用条件。
第二,progressive disclosure 不能等同于 metadata-only retrieval。下游 Agent 可以只看到名称和描述,但上游路由器最好能读取完整 skill 文本。
第三,大规模 skill registry 需要专门的路由层。把 skill 全部塞进上下文不可行,靠模型从长列表中选择也不稳定。
第四,skill 池越大,假负样本问题越严重。不同作者可能实现功能相近的 skill,训练时必须处理等价能力,否则检索器会被错误监督误导。
第五,路由器应该按系统目标优化。如果目标是给 Agent 提供一个最可能有用的 skill,Hit@1 很重要;如果目标是为复杂任务提供完整能力包,Recall@K 和 FC@K 更重要。
第六,路由质量和 Agent 能力相互制约。强 Agent 更能利用正确 skill,弱 Agent 即使拿到正确 skill,也可能无法转化为任务成功。
小结
SkillRouter 这篇论文的核心价值在于,把 Agent 系统中的 skill routing 从“附属检索问题”提升为一个独立的系统瓶颈。
论文证明,在大规模且高度重叠的 skill 池中,完整 skill body 不是可有可无的补充信息,而是决定路由质量的关键证据。基于这一点,SkillRouter 用较小模型、全文检索、假负样本过滤和 listwise reranking,取得了优于大规模基线的 top-1 路由效果。
对实际 Agent 项目而言,这篇论文提醒我们:skill 生态越丰富,系统越需要一个可靠的路由层。否则,Agent 并不是“没有能力”,而是经常在任务开始前就拿错了能力。