
从Text-to-SQL到数据智能实践
摘要
本文以 Text-to-SQL 的工程落地为主线,先说明自然语言查询如何转为 SQL,再通过保险场景 SQL Copilot 展开完整案例,最后讨论 LangChain SQL Agent 的适用边界、Vanna 的 RAG 增强价值,以及从 SQL 查询走向数据智能分析的路径。
从Text-to-SQL到数据智能实践
写在前面
Text-to-SQL 解决的是一个很具体的问题:业务人员用自然语言提问,系统自动生成 SQL,从数据库中查出结果。它看起来像一个“自然语言转 SQL”的生成任务,但在实际工程中,它更像一个数据应用链路:问题理解、表结构匹配、SQL 生成、SQL 执行、结果解释和错误修正。
这篇文章按一条主线展开:先说明 Text-to-SQL 的基本流程;再用 LangChain SQL Agent 搭一个基础版本;随后以保险场景 SQL Copilot 作为重点案例,展示自然语言问题如何映射到多表 SQL;接着分析基础方案暴露出的字段错配、值域错配和上下文不足问题;最后说明为什么需要 Vanna 这类 RAG 增强方案,以及如何进一步从 SQL 查询走向数据智能分析。
全文结构如下。
模块 | 解决的问题 | 和后文的关系 |
|---|---|---|
Text-to-SQL 基本流程 | 自然语言如何变成 SQL | 建立整体框架 |
LangChain SQL Agent | 如何快速搭建基础查询 Agent | 作为基础方案 |
保险场景 SQL Copilot | 多表业务查询如何落地 | 作为重点案例 |
基础方案的问题 | 为什么只靠 Schema 和模型还不够 | 引出 RAG 增强 |
Vanna RAG 增强 | 如何用 DDL、文档、示例 SQL 提升稳定性 | 解决上下文不足 |
数据智能扩展 | SQL 查询之后还能做什么 | 从查数走向分析 |
一句话概括
Text-to-SQL 不是单次模型调用,而是“业务问题 + 数据库 Schema + 领域上下文 + SQL 校验 + 执行反馈”的闭环。LangChain 可以快速搭建基础查询链路,Vanna 通过 RAG 补充领域上下文,而数据智能需要在 SQL 查询之后继续做统计、建模和解释。
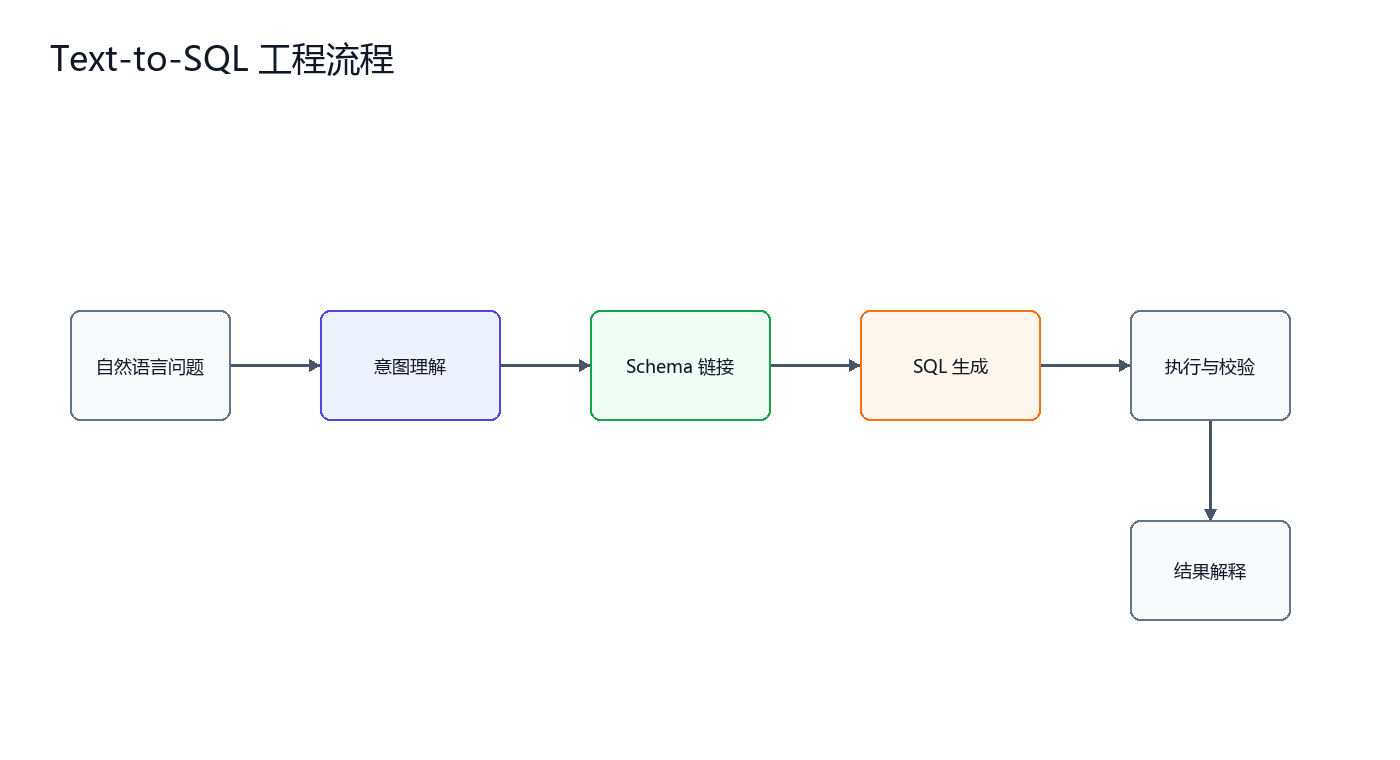
1. Text-to-SQL 的基本流程
业务人员的问题通常不是数据库语言。例如“查询所有未支付保费的保单号和客户姓名”,这句话里有三个关键信息:查询对象是保单,过滤条件是未支付保费,输出字段是保单号和客户姓名。
模型要把它转成 SQL,需要完成五步。
步骤 | 说明 | 常见错误 |
|---|---|---|
意图理解 | 判断用户真正想查什么 | 把统计问题误判成明细查询 |
Schema 链接 | 找到相关表和字段 | 找错表、字段不存在 |
SQL 生成 | 写出查询语句 | Join 条件错误、SQL 不完整 |
执行校验 | 在数据库中执行或预检查 | 枚举值不匹配、权限不安全 |
结果解释 | 把结果转成业务语言 | 解释过度、遗漏口径 |
Text-to-SQL 的难点主要在第二步。自然语言中的“未支付保费”并不直接告诉模型字段名,真实字段可能是 PremiumPaymentStatus;“客户姓名”也不一定在保单表中,可能需要从 CustomerInfo 表关联获取。
2. 基础方案:用 LangChain SQL Agent 快速搭建查询链路
如果只是想快速验证 Text-to-SQL,可以先用 LangChain 的 SQLDatabaseToolkit 和 create_sql_agent。这个方案会让 Agent 读取数据库 Schema,根据用户问题生成 SQL,并调用数据库工具执行查询。
调用方式很直接。
这个基础方案的优点是搭建快,适合验证数据库能否通过自然语言查询。它的局限也很明显:Agent 知道表结构,但不一定知道业务口径;知道字段名,但不一定知道字段值域;能尝试生成 SQL,但不一定能稳定生成正确 SQL。
因此,LangChain SQL Agent 更适合作为第一层原型,而不是最终生产方案。它回答了“能不能查”的问题,但还没有解决“查得是否稳定、口径是否正确”的问题。
3. case:保险场景 SQL Copilot
保险场景比单表查询更接近真实业务。它包含客户、保单、理赔、产品、代理人、员工等多个实体。很多问题必须跨表查询,不能只靠单表字段匹配。
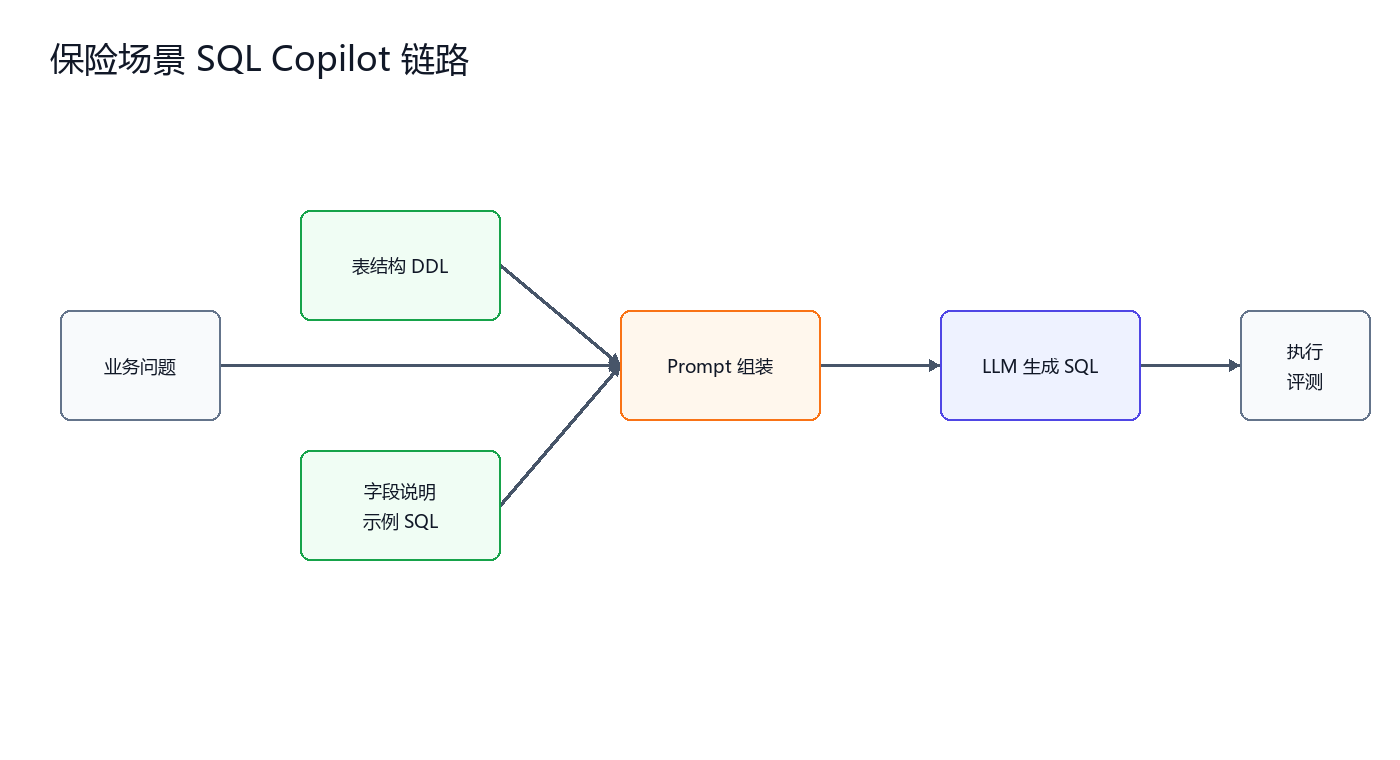
3.1 数据表和业务关系
案例中使用 7 张表。
表名 | 含义 | 关键字段 |
|---|---|---|
| 客户信息 |
|
| 保单信息 |
|
| 理赔信息 |
|
| 受益人信息 |
|
| 代理人信息 |
|
| 产品信息 |
|
| 员工信息 |
|
其中最常用的关系链路是:
这条链路决定了很多查询能否正确生成。例如“理赔金额大于 10000 元的客户姓名和联系电话”,问题里出现的是理赔和客户,但两者之间需要通过保单表关联。
3.2 Prompt 应该包含什么
如果只给模型一句自然语言问题,模型会凭经验猜表名和字段。更稳定的 Prompt 应该包含四部分:问题、DDL、字段说明、输出约束。
这段 Prompt 的作用不是让模型“更聪明”,而是减少它的自由发挥空间。DDL 告诉模型有哪些表和字段;字段说明告诉模型业务词和字段之间的关系;输出约束让结果更容易被程序解析。
3.3 示例一:未支付保费查询
自然语言问题如下。
这个问题至少涉及两张表。保费支付状态在 PolicyInfo 中,客户姓名在 CustomerInfo 中。正确 SQL 应该先筛选未支付保费的保单,再通过 CustomerID 关联客户。
这个例子说明,Text-to-SQL 的关键不是会写 SELECT,而是能找到正确字段和值域。这里的 Unpaid 很重要。如果模型生成中文值 未支付,SQL 语法可能没问题,但查询结果可能为空。
3.4 示例二:高额理赔查询
第二个问题更复杂。
这个问题涉及三张表:ClaimInfo 保存理赔金额,PolicyInfo 保存保单和客户关系,CustomerInfo 保存客户姓名和电话。
这个例子体现了多表查询的核心:自然语言中的“相关客户”不是字段名,而是关系推理。模型必须知道理赔记录通过保单连接到客户,才能写出正确 Join。
3.5 模型结果对比
材料中保留了 Qwen Coder 和 Qwen Turbo 对 10 个保险查询问题的 SQL 生成结果和耗时。结果显示,Qwen Turbo 平均耗时更低,但速度不能代表正确性。部分问题中,模型会出现字段错配、值域错配或 SQL 不完整。
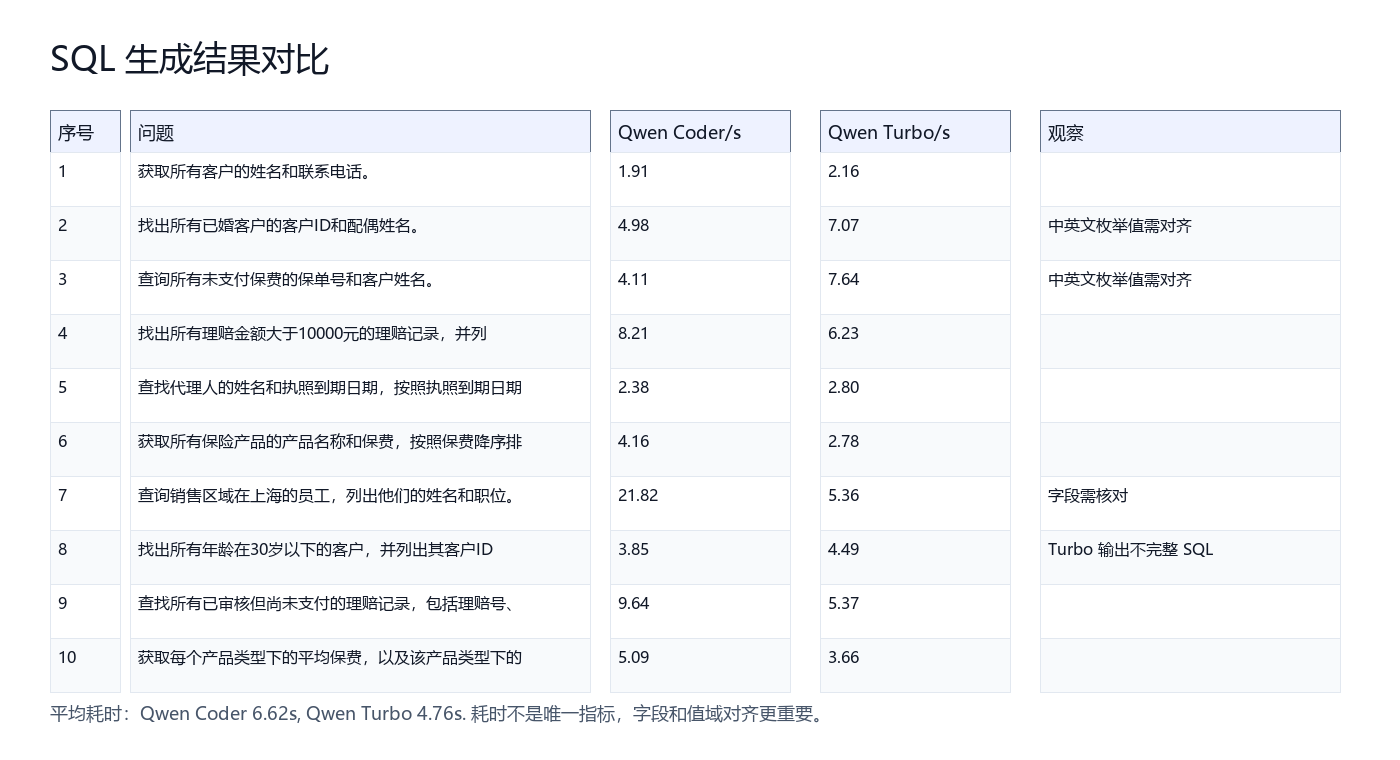
从结果中可以看到三类典型问题。
第一,字段错配。例如“销售区域在上海的员工”容易被模型映射到 SalesRegion,但员工表中更合理的字段是 Location。SalesRegion 出现在产品表中,这说明模型可能根据词面相似度选错字段。
第二,值域错配。例如数据库中未支付状态可能是 Unpaid,但模型可能生成 未支付。SQL 可以执行,但结果为空。
第三,SQL 不完整。例如年龄小于 30 岁的查询,模型可能只生成日期条件片段,而没有完整的 SELECT ... FROM ... WHERE ...。
这些问题说明:Text-to-SQL 的评测不能只看生成文本是否像 SQL,还要检查是否能执行、是否命中正确字段、是否符合业务口径。
4. 基础方案暴露的问题
到这里可以看出,LangChain SQL Agent 和手写 Prompt 都能完成基础 Text-to-SQL,但它们共同依赖一个前提:模型在当前上下文中能看到足够准确的信息。
实际问题是,上下文经常不够。
问题 | 表现 | 后果 |
|---|---|---|
表很多 | 模型选错表 | SQL 可执行但口径错误 |
字段相似 |
| 查询对象错误 |
枚举值不明确 |
| 查询结果为空 |
业务词不规范 | 用户说法和字段名差异大 | 无法正确 Schema 链接 |
缺少示例 | 模型不知道常用 Join 路径 | 多表查询不稳定 |
所以,仅有数据库 Schema 不够。一个更可靠的系统需要把 DDL、字段解释、业务词典、历史高质量 SQL 示例一起纳入上下文。这就是后面 Vanna 这类 RAG 增强方案要解决的问题。
5. RAG 增强方案:Vanna 解决什么
Vanna 的价值不是替代 LangChain,而是补足基础方案的上下文不足。它把数据库 DDL、字段文档、业务说明、示例问题和示例 SQL 放入向量库。用户提问时,系统先检索相关上下文,再让模型生成 SQL。
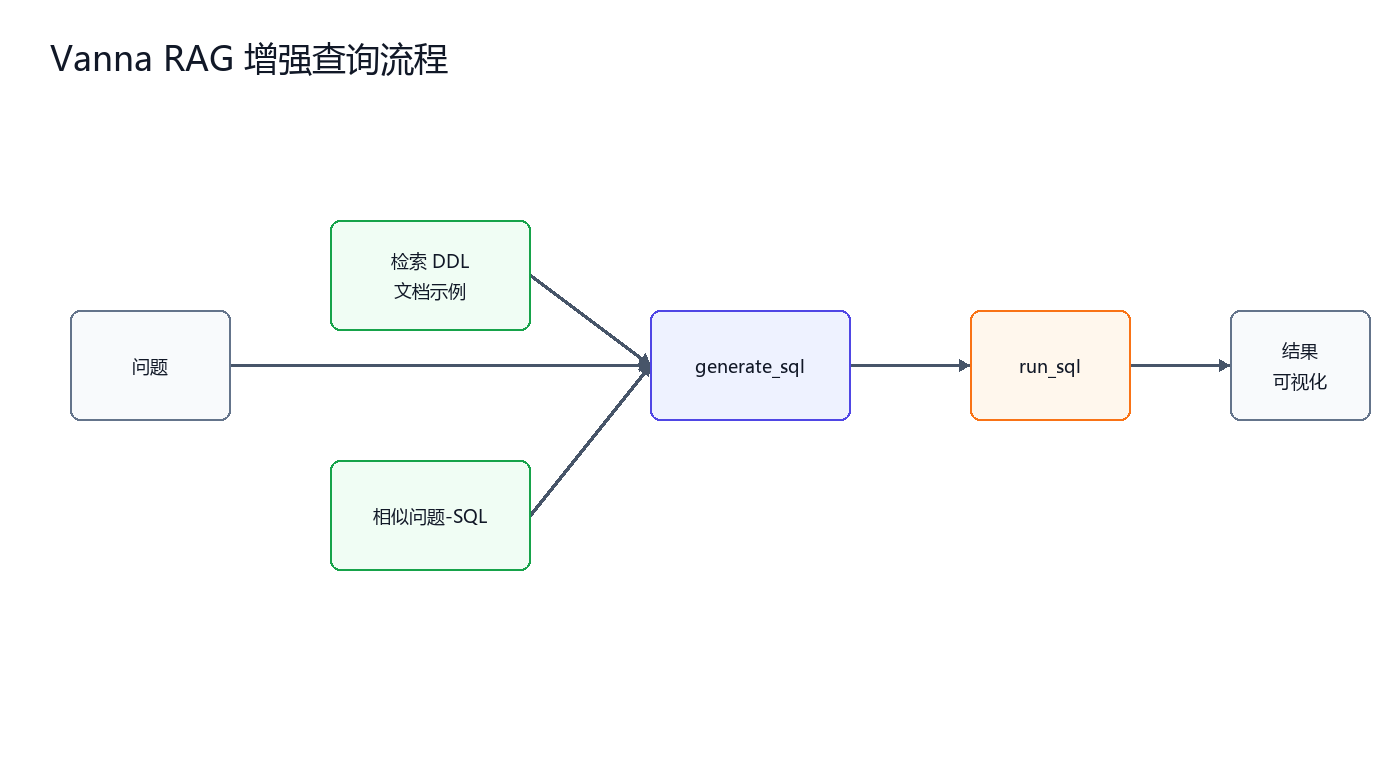
它解决的是前文暴露出的三个问题。
第一,表太多时,不把全部 Schema 一次性塞给模型,而是检索相关表结构。
第二,字段含义不直观时,通过字段说明和业务文档补充语义。
第三,多表 Join 不稳定时,通过相似问题和历史 SQL 示例提供参考路径。
一个最小 Vanna 应用可以这样组织。
训练阶段把表结构写入向量库。
如果有高质量示例,也应该一起训练。
这样,当用户提出相似问题时,系统不仅能检索到相关表,还能检索到可复用的 Join 路径和值域表达。相比基础 SQL Agent,Vanna 的核心提升在于“把正确经验沉淀下来”。
但 Vanna 也需要约束。训练数据必须准确,错误 SQL 一旦进入向量库,会被反复检索和放大;相似度阈值需要控制,否则可能检索到无关示例;最终 SQL 仍然需要权限、语法和业务校验。
6. 从 Text-to-SQL 到数据智能
Text-to-SQL 解决的是“查数”,数据智能解决的是“理解数据并形成判断”。两者是递进关系。
例如用户问:
这个问题不是单条 SQL 就能稳定解决。系统需要识别年卡用户、确定万圣节时间窗口、关联入园记录和餐饮订单,再计算人均消费。
如果问题变成:
这已经进入建模分析。系统需要从 SQL 查询得到数据集,再用 Python 做特征构造、回归分析或决策树分析,最后把统计结果解释成业务结论。
因此,数据智能助手至少需要三类工具。
工具 | 作用 |
|---|---|
SQL 查询工具 | 获取结构化数据 |
Python 分析工具 | 做统计、建模、可视化 |
解释生成工具 | 把结果转成业务语言 |
Text-to-SQL 是入口。它让业务人员可以通过自然语言获得数据;数据智能是在此基础上继续做分析、归因和决策建议。
7. 工程结论
这条链路可以总结为三层。
第一层是基础 Text-to-SQL。适合表少、问题简单、查询口径明确的场景。LangChain SQL Agent 可以快速验证。
第二层是 RAG 增强 Text-to-SQL。适合表多、字段复杂、业务词和字段名不一致的场景。Vanna 通过 DDL、字段说明和示例 SQL 提升稳定性。
第三层是数据智能。适合需要分析、建模和解释的场景。它不只生成 SQL,还要调用 Python、统计模型和可视化工具。
真正可靠的 Text-to-SQL 系统,需要把以下能力放在一起:
能力 | 目的 |
|---|---|
Schema 管理 | 让模型知道有哪些表和字段 |
领域上下文 | 让模型理解业务词和字段含义 |
示例 SQL | 让模型复用正确 Join 路径 |
SQL 校验 | 防止幻觉字段、错误值域和危险查询 |
执行反馈 | 让系统根据报错或空结果修正 |
权限控制 | 防止越权查询和破坏性操作 |
小结
从 Text-to-SQL 到数据智能,是一个逐步增强的过程。LangChain SQL Agent 可以快速搭建基础查询能力;保险场景 SQL Copilot 说明多表业务查询需要字段解释、值域对齐和结果评测;Vanna 进一步用 RAG 把 DDL、文档和示例 SQL 沉淀为可检索上下文;数据智能则把查询结果继续用于分析、建模和解释。
核心结论是:模型能生成 SQL,但不能保证 SQL 一定正确。可靠的系统必须有 Schema、上下文、示例、校验和执行反馈。只有形成闭环,Text-to-SQL 才能从演示走向实际可用的数据智能工具。