
Accelerating Science with GPT-5: Early Science Acceleration Experiments论文阅读
摘要
本文深入解读 OpenAI 于 2025 年 11 月发布的 89 页案例研究报告。论文联合牛津、剑桥、哥大、哈佛、Vanderbilt、LLNL 等九所机构,在数学、物理、天文、生物学、核聚变工程和计算机科学六大领域记录了 12 个 GPT-5 真实科研协作案例。核心发现:GPT-5 能从独立重新发现前沿结果、深度跨领域文献搜索、人机协作加速研究到产出四项全新数学证明。核聚变建模加速 1000 倍,数学证明从数天压缩到数十分钟。但人类专家的判断、验证和引导仍然是不可替代的核心环节。
Accelerating Science with GPT-5: Early Science Acceleration Experiments论文阅读
写在前面
2025 年 11 月 20 日,OpenAI 发布了一份 89 页的案例研究报告 Early Science Acceleration Experiments with GPT-5。这篇论文与大多数机器学习论文截然不同——它不提出新模型架构、新训练方法或新基准数据集的改进,而是系统地回答一个直观但深刻的问题:当前最先进的大语言模型,在真实的、前沿的科学研究中到底能做到什么程度?
这篇论文的意义在于它的方法论。作者没有让模型做标准基准题——MATH、GPQA、HumanEval 等标准化评测已经在论文之外被大量讨论——而是邀请了来自六个学科的多位顶尖专家,在各自的日常真实科研中以各种方式与 GPT-5 协作,完整记录交互过程、模型输出和人类验证工作。这种研究设计使得结果不再是抽象的"准确率",而是具体的、可追溯的科研贡献。
作者阵容覆盖了从纯数学到核工程的广泛领域:OpenAI 的 Sebastien Bubeck、Ronen Eldan、Yin Tat Lee 和 Kevin Weil;牛津大学的 Christian Coester;法兰西学院与剑桥大学的菲尔兹奖得主 Timothy Gowers;Vanderbilt 大学的 Alex Lupsasca 和 Robert Scherrer;哥伦比亚大学的 Mehtaab Sawhney;哈佛大学的 Mark Sellke;Lawrence Livermore 国家实验室(LLNL)的 Brian K. Spears;Jackson Laboratory 的 Derya Unutmaz;以及 UC Berkeley 的 Nikita Zhivotovskiy。这种跨机构、跨学科的作者配置本身就说明了信息——科学加速不是某个学科的孤立故事。

本文按照论文阅读博客的规范结构,从研究问题、核心贡献、方法、实验结果、局限性和启发六个方面深入展开。鉴于论文篇幅较大(89 页),本文将重点解读每个案例的技术细节——包括核心公式、定理陈述和证明逻辑——以及这些案例对 AI 辅助科学研究的系统层面启示。目标读者是对 AI for Science、大模型科研能力评估和科学加速实践感兴趣的研究者与工程师。
速读卡片
项目 | 内容 |
|---|---|
论文 | Early Science Acceleration Experiments with GPT-5 |
arXiv | 2511.16072 |
作者 | Sebastien Bubeck (OpenAI), Christian Coester (Oxford), Ronen Eldan (OpenAI), Timothy Gowers (College de France/Cambridge), Yin Tat Lee (OpenAI), Alexandru Lupsasca (Vanderbilt), Mehtaab Sawhney (Columbia), Robert Scherrer (Vanderbilt), Mark Sellke (Harvard), Brian K. Spears (LLNL), Derya Unutmaz (Jackson Lab), Kevin Weil (OpenAI), Steven Yin (OpenAI), Nikita Zhivotovskiy (UC Berkeley) |
机构 | OpenAI, University of Oxford, College de France & University of Cambridge, Vanderbilt University, Columbia University, Harvard University, Lawrence Livermore National Laboratory, The Jackson Laboratory, UC Berkeley |
日期 | 2025 年 11 月 20 日 |
页数 | 89 页 |
覆盖学科 | 数学(凸优化、组合数学、泛函分析、图论、在线算法)、理论物理(黑洞对称性、引力波)、天文物理(宇宙弦)、生物学(免疫学、T 细胞生物学、流式细胞术)、核聚变工程(ICF 燃烧波传播)、计算机科学(在线算法、理论 CS) |
核心问题 | GPT-5 在真实的、前沿的科学研究中能独立做什么?不能做什么?需要什么样的人类参与和验证? |
核心方法 | 多案例研究法:12 位领域专家以日常科研方式与 GPT-5 交互(上传论文 PDF、提供实验数据、提出开放问题、迭代式引导),完整记录交互过程、模型输出质量和人类验证工作量 |
主要结论 | (1) GPT-5 可在分钟/小时内完成人类数天到数月的工作——加速比从数十倍到上千倍;(2) 深度跨领域文献搜索是其最独特且目前最难被人类替代的能力;(3) 获得了 4 个经过严格验证的全新数学结果;(4) 人类专家的判断、纠错和引导在这些成功中不可或缺;(5) 专家水平越高,从 AI 中获得的生产力增益越大 |
加速数据 | 核聚变建模:~6 人月 -> ~6 人时(约 1000x);凸优化证明改进:数天 -> 17 分钟;黑洞 Lie 对称性推导:数月 -> ~30 分钟(含热身);免疫学机制推理:数月 -> 17 分钟;宇宙弦积分解析:6 个月部分结果 -> 40 分钟完整结果 |
模型页 | 论文使用 GPT-5 Pro(通过 ChatGPT 界面和 OpenAI API),以及其他内部模型变体 |
适合读者 | AI for Science 研究者、科研方法论关注者、大模型能力评估与推理基准设计者、科学计算与数值模拟工程师 |
一句话概括
GPT-5 在真实科研中展现出从独立重新发现已有前沿结果到产出四项全新数学证明的完整能力谱系,其核心价值在于将人类专家数天到数月的认知劳动压缩到数十分钟到数小时;但这种加速依赖于三个精确条件——问题必须有可验证的目标或清晰的逻辑结构、模型需要恰当的结构化引导(scaffolding)、输出需要领域专家持续和严格的验证——科学研究中的核心创意、问题定义和方向判断仍然是且可能将长期是人类不可替代的领域。
研究问题
Large Language Model,大语言模型,在编程、写作和规划等任务上已经相当有用。但将这些能力从"生成有用的文本"升级为"在科学前沿做出有意义的认知贡献"时,评估的维度发生了根本变化。科学研究需要的不是流畅的语言生成,而是在高度专业化的知识边界上提出新想法、在看似不相关的领域之间建立深层概念连接、在庞杂的文献中精确定位关键但被遗忘的信息、以及产出严谨、可验证、可复现的新结果。
论文将核心研究问题分解为四个逐级递增的评估层次:
独立重新发现 (Independent Rediscovery):GPT-5 能否仅凭原始问题设定和背景材料,在没有训练数据泄露的情况下重新推导出近期发表的前沿结果?这个层次的测试设计非常精巧——论文选择的工作均在 GPT-5 训练数据截止日期之后发表,因此模型不可能"记住"答案。
深度文献搜索 (Deep Literature Search):GPT-5 能否超越关键词匹配层面的信息检索,基于对数学结构和科学概念的深层理解,在跨学科、跨语言、跨时代的文献中找到被常规搜索引擎和人工检索遗漏的关键工作?这里测试的不是 IR(信息检索)能力,而是概念配准(concept alignment)——在不同学科的不同词汇体系之间建立等价映射的能力。
人机协作研究 (Working in Tandem):GPT-5 在实际科研流程中——从问题建模、数值实现、参数优化到理论解释——能提供什么级别和什么形式的帮助?与独立完成任务不同,这里评估的是人类专家与 AI 交互式协作的效率和质量。
获得新结果 (New Scientific Results):GPT-5 能否真正产出此前不存在于任何已发表文献中的、经过人类专家严格验证的全新科学成果?这是四个层次中最高的一级,也是最直接地测试"AI 能否做原创科研"的层次。
值得注意的是论文在引言中将自身与 Google DeepMind 的 AlphaEvolve 做了明确区分。AlphaEvolve 聚焦于有明确定义目标函数的搜索问题——可以通过算法爬山式优化的问题。GPT-5 是一个通用系统,可以处理和回答任何类型的查询。两种范式互补而非竞争:AlphaEvolve 在有明确奖励信号的结构化搜索中表现出色,GPT-5 的优势在于应对开放性的、需要跨领域知识整合的、无法被简化为单一目标函数的科学问题。
论文对诚实性的承诺从引言开始就非常明确:"我们的目的不是声称超出证据所允许的范围。我们的目的是用具体的例子展示 GPT-5 今天能做什么和不能做什么,并为研究者如何使用它加速科学发现同时保持高标准提供清晰的路径。"这段话贯穿了整篇论文——每个案例中,作者都同等详细地记录了模型的成功和失败。
整体架构
论文共 89 页,正文按能力评估层次分为四章、一个引言和一个结论。每一章对应前面提出的一个研究问题层次:
章 | 标题 | 案例数 | 核心评估维度 |
|---|---|---|---|
I | 独立重新发现已知前沿结果 | 3 | 模型能否在没有训练数据泄露的情况下推进研究? |
II | 深度文献搜索 | 3 | 模型能否基于概念理解而非关键词匹配定位关键工作? |
III | 人机协作 | 3 | 模型在实际科研工作流中的协作质量和局限? |
IV | 获得新科学结果 | 4 | 模型能否产出真正的原创数学贡献? |
以下按照这四个层次,逐一展开全部 12 个案例的技术细节。
第一章:独立重新发现已知前沿结果
第一章的三个案例是整个论文的能力基线测试。它们回答的共同问题是:当训练数据中确定不存在答案时,模型能从原始问题出发独自走多远?
I.1 凸优化步长条件改进 —— Sebastien Bubeck
研究背景
在凸优化中,梯度下降是最基础的算法。给定目标函数 f: R^d -> R,以恒定步长 eta 更新:
经典理论指出:对于 L-光滑凸函数(Lipschitz 常数为 L,即梯度映射 x -> nabla f(x) 的 Lipschitz 常数),梯度下降收敛的充要条件是步长 eta < 2/L。
论文 [BSZ25] 提出了一个此前从未被研究过的新问题:在什么条件下,目标函数值形成的序列 {f(x_k)}_{k>=0} 本身是凸的?换言之,由点集 {(k, f(x_k))} 定义的分段线性函数何时是一个凸函数?
定义两步间的递减量 D_k = f(x_k) - f(x_{k+1}),序列凸性等价于 {D_k} 非增:对所有 k >= 0,D_{k+1} <= D_k。
[BSZ25] 的 v1 版本:
充分条件:
eta <= 1/L必要条件:
eta <= 1.75/L
v2 版本将充分条件推进到 eta <= 1.75/L,完美闭合了这个 gap——证明最优充分条件与必要条件一致。
GPT-5 的贡献
Bubeck 的实验设计非常精巧。他在 2025 年 8 月 20 日(GPT-5 的训练数据截止日期之后)进行实验,只上传 [BSZ25] 的 v1 PDF 给 GPT-5 Pro,问它:"你能否在相同假设条件下改进定理 1 的步长条件?"
关键的防泄露验证:Bubeck 检查了 GPT-5 的完整推理痕迹,确认模型没有执行任何网络搜索——否则可能发现 v2 的 arXiv 页面和相关讨论。

图 I.1:与 GPT-5 Pro 的完整交互过程。模型仅被上传了 v1 的 PDF 文件,被要求在不添加额外假设的情况下改进定理 1 的步长条件。模型经过 17 分 35 秒的深度推理后给出了改进结果。
GPT-5 Pro 经过 17 分 35 秒的推理后,给出了以下定理:
定理 I.1.1(改进的步长条件):设 f: R^d -> R 为凸且 L-光滑函数,考虑梯度下降迭代 x_{k+1} = x_k - eta * nabla f(x_k)。若步长 eta 满足
则序列 {f(x_k)} 是凸的。等价地,递减量 D_k = f(x_k) - f(x_{k+1}) 构成非增序列:对所有 k >= 0,D_{k+1} <= D_k。
这给出了充分条件 eta <= 1.5/L——恰好位于 v1 的 1/L 和 v2 的最优 1.75/L 之间的中点。换句话说,GPT-5 在这个从已知结果到最优结果的 gap 中走了一半的路程。

图 I.2:GPT-5 Pro 给出的完整证明。证明结构清晰,分为下界、上界、合并三个步骤。
GPT-5 的证明展开如下:
第 (1) 步:D_k 的下界。利用 L-光滑凸函数的 Bregman 散度不等式
代入 x = x_k, y = x_{k+1} 和 x_k - x_{k+1} = eta * g_k(令 g_k = nabla f(x_k)),得到
其中 Delta_k = g_{k+1} - g_k。
第 (2) 步:D_{k+1} 的上界。利用凸性 f(x) - f(y) <= <nabla f(x), x - y>,代入 x = x_{k+1}, y = x_{k+2}:
第 (3) 步:相减并利用光滑性。(A) 减 (B),利用 g_{k+1} = g_k + Delta_k 展开,再应用 L-光滑函数的 1/L-cocoercivity:
最终得到核心不等式:
当 eta <= 3/(2L) 时右边非负,即 D_{k+1} <= D_k,证明完成。
关键发现
有三个值得关注的技术细节:
证明风格差异。GPT-5 的证明是 v1 风格的自然延伸(Bubeck 称为"更规范的变体"),而人类 v2 证明需要巧妙的加权不等式消去("clever weighting of different inequalities for certain cancellations to happen")。两种证明策略的不同说明 GPT-5 不是在复制人类思路,而是在自己的数学框架内探索。
加速效果的量化。Bubeck 的估计是:"坦率地说,这样的结果(从 1/L 到 1.5/L)对于领域内某些专家可能只需几小时,对于大多数专家可能需要几天。"这与本章其他案例一起,建立了 AI 科学加速的基线量级。
内部模型的进一步能力。论文在脚注中披露:OpenAI 内部的、能连续推理数小时的模型从零开始(不提供 v1 作为输入,直接提出"在什么步长下优化曲线是凸的?")能够推导出最优界
1.75/L。这暗示了更长推理时间与更深科学推理之间的正相关关系。
I.2 黑洞对称性发现 —— Alex Lupsasca
研究背景
天体物理中的黑洞由质量 M 和角动量 J = aM 完全刻画。Kerr 度规描述了旋转黑洞周围的时空几何。在 Boyer-Lindquist 坐标(Boyer-Lindquist coordinates)(t, r, x = cos(theta), phi) 下,稳态、轴对称的无质量标量波满足:
其中 Delta(r) = r^2 - 2Mr + a^2。这是一个具有非恒定系数的线性二阶 PDE。
在广义相对论中,黑洞表现出令人惊讶的刚性——其静态潮汐响应(tidal response)的特征量 Love 数(Love numbers)为零。这种刚性的根源通常被追溯到控制方程中的隐藏对称性。因此,核心问题是:方程 (I.1) 的 Lie 点对称性(Lie point symmetries)是什么?
人类研究路线。经典方法是 Lie 的降阶算法(Lie's algorithm for reduction of order)。首先假设对称生成元的形式为 X = xi^r partial_r + xi^x partial_x + eta partial_psi,通过 prolongation 将其延伸到导数,施加方程不变性条件,然后求解在弯曲黑洞背景下极其复杂的超定 PDE 系统。Lupsasca 在近期工作 [Lup25b] 中经过大量推导后惊讶地发现:存在三个非平凡 Lie 点对称性,它们生成一个 SL(2,R) 代数(SL(2,R) algebra)——包括与尺度不变性相关的膨胀算子 H_0,可用于理论解释 Love 数为何消失。
GPT-5 的贡献
冷启动失败。GPT-5 Pro 在第一次被直接问到"PDE (I.1) 的 Lie 点对称性是什么?"时,经过约 5 分钟推理后错误地断言方程"没有超出平凡标度之外的连续对称性"。这是论文记录的第一个重要失败。
Lupsasca 随后采用了一种后来被证明极为有效的策略。他让模型先在平坦空间极限(M = a -> 0)中热身。在圆柱坐标 (rho, z) 下(rho = r * sqrt(1-x^2), z = r*x),方程简化为:
经过 10 分 27 秒的推理,GPT-5 Pro 正确给出了所有平坦空间对称性,包括生成 SL(2,R) 的三个生成元:
其中 H_- 是非平凡的特殊共形生成元(special conformal generator)。Lupsasca 的评价是:"获得它表明模型执行了(或模拟了)一次真正的对称性计算,而非猜测。"
关键转折。在同一个会话实例中,Lupsasca 重新提出弯曲空间问题。GPT-5 Pro 经过约 18 分钟的推理,正确给出了完整的弯曲空间 SL(2,R) 对称生成元:
这些生成元完美匹配了 [Lup25b] 的核心结构洞察。
关键发现
这个案例有三层重要启示:
脚手架策略 (Scaffolding) 是关键。冷启动的直接失败与热身后的成功之间的对比,揭示了一个更一般的模式:模型的知识激活可以通过呈现同一概念类的更简单实例来启动。Lupsasca 总结道:"这暗示了一种通用工作流——先在简化问题上热身,再提升到复杂场景。"
加速效果的显著性。一旦对称性被找到,下游结果(潮汐响应约束、Love 数为零的机制解释)可以在相对直接的分析后得出。GPT-5 在约 30 分钟内(含热身)完成了此前需要数月工作的核心步骤——从"问题是什么"到"关键的对称性是什么"。
AI 作为"对称性发现引擎"。Lupsasca 提出了一个更具雄心的愿景——"AI as a symmetry engine":以最小的领域脚手架,当前模型可以为具有非恒定系数的 PDE 执行非平凡的 Lie 对称性发现。"研究速度可以从数月压缩到数天,一旦正确的 prompt 和 scaffold 到位。"
I.3 免疫系统机制分析 —— Derya Unutmaz
研究背景
Unutmaz 的实验室一直在研究人 T 细胞如何响应葡萄糖代谢的扰动。实验使用 2-脱氧-D-葡萄糖(2-deoxy-D-glucose, 2-DG)——一种葡萄糖竞争性类似物——在 T 细胞活化的初始阶段(称为 priming)短暂抑制糖酵解。实验流程为:
从人外周血分选 CD4+ T 细胞(包含 naive 和 memory 混合群体)。
在抗 CD3/CD28 刺激(TCR 活化)条件下加入 2-DG,浓度从 0 到 3 mM。
两天后洗去药物,在 IL-2(Interleukin-2)存在下扩增两周。
重新刺激(PMA + ionomycin,6 小时),用流式细胞术(flow cytometry)检测 IL-17A(Th17 效应细胞因子)和 Th17 谱系标记 CCR6 与 CD161。
核心困惑是:2-DG 为什么会导致 Th17 细胞亚群的特异性和持续性增加? 团队在该领域有深厚的专业知识,但完整的机制模型始终难以构建。他们已有完整的原始实验数据、甘露糖救援实验结果和 CAR-T 细胞杀伤实验数据,但都尚未发表。
GPT-5 的贡献
Unutmaz 向 GPT-5 Pro 上传了流式细胞术数据图,并给出了一个非常详细的提示词。这个提示词本身就是一个值得分析的案例——它不仅要求定量分析(剂量-反应曲线、各标记的百分比阳性、中位荧光强度 MFI、跨供体效应量和置信区间),还要求区分"如果从纯 naive CD4+ T 细胞出发结果会如何不同"。
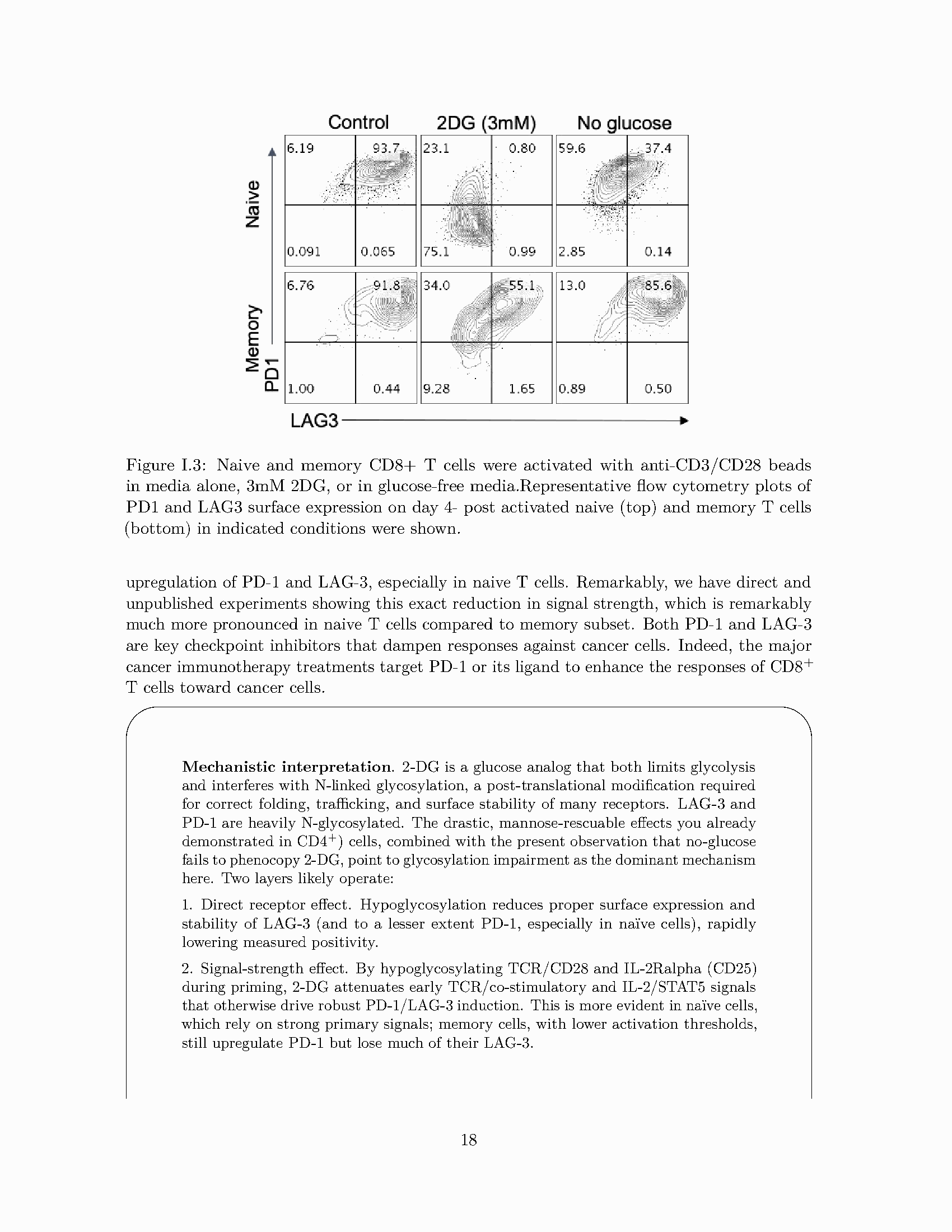
图 I.3:GPT-5 Pro 对流式细胞术数据的分析。模型正确生成了直方图、剂量-反应定量表格和完整的 CSV 数据文件。
GPT-5 Pro 经过 17 分钟的深度推理后,给出了一个完整的机制模型。其核心洞察是:2-DG 的主要作用不是能量限制(糖酵解阻断),而是通过干扰 N-连接糖基化(N-linked glycosylation)来削弱 IL-2 受体信号传导。完整的推理链如下:
区分两种机制:2-DG 在 mM 浓度下同时抑制糖酵解和 N-连接糖基化。但低葡萄糖对照组(仅限制能量、不抑制糖基化)的效果远弱于等摩尔 2-DG,提示糖基化干扰是主导机制。
靶向 IL-2 通路:N-糖基化受损导致 CD25(IL-2 受体 alpha 链,IL-2Ralpha)等关键糖蛋白在细胞表面的正确折叠、运输和表达受阻。
解除 Th17 抑制:IL-2/STAT5 信号是 Th17 分化的主要抑制者。当 IL-2 信号减弱时,对 Th17 谱系的抑制作用降低,导致 RORgamma-t(Th17 主转录因子)程序得以维持或增强。
表观遗传印迹:效应在药物洗脱两周后仍然清晰可测,表明发生了染色质水平的持久改变——这不是暂时的代谢状态改变,而是细胞重编程(cellular reprogramming)。
Memory vs Naive:效果仅在 memory T 细胞中出现,naive T 细胞不响应——因为 memory 细胞已经有 pre-committed Th17 染色质景观,而 naive 细胞依赖强 IL-2 信号进行存活和扩增。
实验预测与后续验证。GPT-5 Pro 还提出了多项可测试的预测,其中多项已被团队未发表数据验证:
甘露糖救援实验(mannose rescue):补充甘露糖可绕过 2-DG 对 N-糖基化通路的阻断,恢复正常的糖蛋白成熟。GPT-5 预测这应逆转 Th17 偏向——团队已完成的实验完全吻合。
CAR-T 杀伤增强:GPT-5 预测,经历过 2-DG 短暂处理的记忆 CD8+ T 细胞在转导抗 CD19 CAR 后,对 CD19+ 淋巴瘤细胞的细胞毒性应增强——团队内部验证结果与 GPT-5 的预测"几乎完美一致"。
Checkpoint 受体调节:GPT-5 预测 2-DG 处理应降低 PD-1 和 LAG-3 在 CD8+ T 细胞上的表达——团队未发表的流式细胞术数据精确验证了这一预测。
GPT-5 Pro 还系统提出了后续实验方案,包括:
使用特异性糖酵解抑制剂(如 PFKFB3 抑制剂 3PO)和 N-糖基化抑制剂(如 tunicamycin)进行分区实验。
IL-2 轴的定量 interrogation(CD25 PNGase F 位移实验、pSTAT5 磷酸流式、IL-2 消耗)。
表观遗传验证(ATAC-seq 和靶向 CUT&Tag 覆盖 RORC、IL-17A/F、IL23R、CCR6 和 PRDM1 位点)。
功能可塑性 mapping(IL-1beta+IL-23 vs IL-12 重新刺激)。
关键发现
Unutmaz 最终的判断直达核心:"GPT-5 Pro 对这个工作的贡献足以使它有资格成为这项新研究的共同作者。" 这个判断基于多个维度:GPT-5 提出了实验团队此前从未想到的机制假说(尽管他们在该领域有深入的专业知识);正确预测了后续实验结果;系统规划了发表所需的关键实验方案。
这个案例同时说明了一个重要模式:AI 在需要跨尺度推理的任务上特别强大——从分子层面的生化扰动(糖基化干扰)到信号通路(IL-2/STAT5)到细胞表型(Th17 偏向)再到治疗应用(CAR-T 细胞制造)——这种多尺度整合是人类专家也感到困难的地方。
第二章:深度文献搜索
第二章是整篇论文中最能展示 GPT-5 独特能力的一组案例。GPT-5 在这里做的不是传统的"信息检索",而是将来自不同学科领域、使用不同词汇体系描述的概念建立等价映射——这是一种认知技能,直到最近还被认为只有经过数十年训练的专家才具备。
II.1 从密度估计到多目标优化 —— Nikita Zhivotovskiy
问题背景
考虑一个几何覆盖问题:设 K subset R^d_+ 为紧凸集,alpha >= 1。称子集 A subset K 为 K 的 alpha-比率覆盖(alpha-ratio cover),如果对每个 theta = (theta_1, ..., theta_d) in K,存在 phi in A 使得对所有坐标 j,theta_j <= alpha * phi_j。
原始动机来自统计密度估计:对于混合密度 p_theta(x) = sum_i theta_i * f_i(x),若 A 是 K 的比率覆盖,则对任意 theta 存在 phi in A 使得 p_theta(x) <= alpha * p_phi(x),进而 KL 散度不超过 log(alpha)。因此,比率覆盖的尺寸决定了用有限个代表近似整个混合密度族的效率。
论文 [Com+25] 的核心定理是:对每个 d >= 1 和每个凸紧集 K,存在一个至多 28d 个元素的子集 A 构成 K 的 32-比率覆盖。关键特征是——尺寸与维数 d 线性相关,且常数因子与 K 的值域范围 R 无关。
GPT-5 的贡献
问题不是定理的证明——定理是五位人类数学家证明的。问题是:这个抽象的几何覆盖结果与哪些已有的工作有关联? Zhivotovskiy 只有定理陈述和密度估计的背景段落,"因为 plausible 的扩展方向不清晰,否则需要问多位专家并依靠运气才能找到正确的连接。"

图 II.1:GPT-5 的文献搜索回复。模型识别出"alpha-比率覆盖"与多目标优化中"multiplicative epsilon-approximate Pareto set"概念的本质等价性,并精确指向 Papadimitriou-Yannakakis (FOCS 2000) 的奠基性工作。
GPT-5 在约 8 分钟的推理中,从比率覆盖的概念出发,跨越到多目标优化(multi-objective optimization)中一个表面上看起来完全不同的概念——乘积近似的 Pareto 集。Papadimitriou 和 Yannakakis (2000) 的奠基性工作(他们在 FOCS 上发表了该领域的开山之作)定义了这样一个概念:
对 K subset [1/R, R]^d,存在一个 (1+epsilon)-乘积近似 Pareto 集,尺寸为 O((log R / epsilon)^{d-1})。

图 II.2:PY00 中与比率覆盖问题密切相关的定理陈述。GPT-5 识别出这两个表面上完全不同的概念之间的深层数学等价性。
关键发现
这个跨领域连接的识别带来了重要的理论进展。对比两个结果:
PY00 经典界:
O((log R / epsilon)^{d-1})——包含对值域范围 R 的对数依赖[Com+25] 定理:
28d元素的 32-比率覆盖 ——在凸性假设下与 R 无关
这个差异触发了新的数学方向:在凸性假设下,PY00 界中的 log R 因子可以被消除。作者据此将定理推广到 (1+epsilon)-覆盖,得到尺寸 O((log(1/epsilon) / epsilon)^{d-1}),为多目标优化的理论计算机科学分支提供了新的基准。
最根本的发现是,GPT-5 做的不是检索,而是翻译——它将来自统计密度估计的一个几何覆盖概念,识别为多目标优化中 Pareto 集概念的本质等价物。这种跨学科的"概念配准"(concept alignment)是传统搜索引擎(只能匹配文字)完全不可能实现的——因为两个领域使用了完全不同、互不重叠的术语体系。
II.2 Erdos 问题数据库 —— Mehtaab Sawhney & Mark Sellke
问题背景
Paul Erdos (1913-1996) 是 20 世纪最高产的数学家之一,发表了 1500+ 篇论文并提出了数百个数学猜想,跨越组合数学、数论、分析等广阔领域。Thomas Bloom 在 2024 年初创建了在线 Erdos 问题数据库 (erdosproblems.com),系统整理了 1105 个问题,每个问题有状态标注(open 或 solved)和讨论论坛。
核心困难在于:标注为"open"的 685 个问题中,很多实际上已经被解决了。解决方案散落在几十年间、不同语言(英文、德文、法文、匈牙利文)、使用不同数学表述的文献中。对专业数学家来说,确认一个问题的真实状态可能需要数天甚至数周的文献追踪。Sawhney 分享了一个个人经历来说明这个问题的严重性:"作为研究生,我曾花了一些时间思考 Problem #490……最终我找到了 [Sze76] 的参考文献解决了它,但其标题模糊地是'On a problem of P. Erdos'——这使得它在常规搜索中几乎不可能被找到。"
GPT-5 的贡献
作者使用 GPT-5 系统性地扫描了 ErdHos 数据库中所有标注为 open 的问题。使用的提示词是完全问题无关的(problem-agnostic)——只需提供问题网页的链接或截图,并要求模型搜索互联网寻找解决方案或部分进展。这种方法的关键验证是:问题编号(如 #339)是 2024 年数据库创建后才分配的,因此不能帮助模型在 2024 年之前的文献中进行搜索——模型必须依靠对数学内容的理解。
整体成果:
类别 | 数量 | 代表问题 |
|---|---|---|
为之前标注 open 的问题找到已发表解答 | 10 | #223, #339, #494, #515, #621, #822, #883, #903, #1043, #1079 |
找到重要部分进展 | 10 | #32, #167, #188, #750, #788, #811, #827, #829, #1017, #1011 |
修正陈述笔误 | 1 | #1041 |
综合前人贡献解决 open 问题 | 1 | #848(详见第四章 IV.1) |
以下是三个特别有代表性的案例:
问题 #339(加法基)。设 A subset N 为 order-r 加法基(即所有充分大的整数可表示为至多 r 个 A 中元素的和)。那么由 A 中恰好 r 个互异元素的和所表示的整数集是否必定有正下密度?
此问题的起源是 Erdos-Graham (1980) 的一篇 100 页论文,约 700 次引用。GPT-5 Pro 在仅被提供问题网页截图作为输入的条件下,第一次查询就找到了隐藏在数百篇引用者中的正确解答。在 GPT-5 介入之前,该问题已在论坛上引发了几个月的讨论但没有人能确定它是否已被解决。
问题 #515(超越整函数)。设 f(z) 为超越整函数(非多项式)。是否存在一条趋于无穷的路径 gamma,使得对每个 lambda > 0,积分 int_gamma |f(z)|^{-lambda} dz 有限?
GPT-5 找到的解答 [LRW84] 实际上研究的是次调和函数(subharmonic functions)F: C -> R 的积分 int e^{-F(z)} dz。经典结果是:F(z) = log|f(z)| 对超越整函数 f 是次调和的。但 [LRW84] 的论文中没有任何地方提到 Erdos 或这个问题。GPT-5 不仅需要发现这个连接,还需要确认 [LRW84] 对"次调和"的定义是否允许 log|f(z)| 在零点处的奇异性——它确实协助作者定位了论文中澄清这个定义的关键段落。
问题 #1043(多项式投影)。设 f 为复系数首一多项式。是否存在一条直线 l,使得区域 {z : |f(z)| <= 1} 到 l 的正交投影长度至多为 2?
解答出现在 Pommerenke 1961 年论文 [Pom61] 中两条定理之间的一个简短旁注中——不是定理、不是引理、不是推论,而是正文中的一个句子。由于这种反常的呈现方式,它被 MathSciNet 的审稿人在撰写正式摘要时遗漏,也被学者们在此后数十年间忽视。更复杂的是,核心证明工作实际上在 Pommerenke 1959 年的德文论文 [Pom59] 中。GPT-5 不仅定位到了这两篇文献,还翻译并解释了德文证明,使 Sawhney 和 Sellke 得以独立验证。

图 II.3:Pommerenke [Pom61] 论文中的关键页面。问题 #1043 的解答作为正文中的一个旁注出现在第 7 页两条定理之间,这种非标准的呈现方式使它逃过了 MathSciNet 审稿人和随后数十年学者的注意。红色方框内是解答位置,结合了 Pom61 的逼近定理和 [Pom59](显示为参考文献 [10])中的早期工作。
关键发现
这些案例共同揭示的核心模式是:GPT-5 在做概念配准(concept alignment),不是传统的文本检索。它能够在不同数学分支中使用完全不同的词汇体系描述相同数学对象的情况下建立等价映射——在"次调和函数的指数积分"和"整函数的倒数幂积分"之间,在"乘积近似的 Pareto 集"和"比率覆盖"之间,在德文数学论文和现代英文技术讨论之间。这是传统搜索引擎完全无法实现的能力——因为搜索引擎只能匹配文本本身,无法理解文本背后的数学概念的等价性。
II.3 Clique-Avoiding Codes:一个警示案例
这个案例是整个论文中最诚实的部分,也是一个对所有 AI 辅助科研实践者的根本性警告。
问题:一个二元线性码 C subset F_2^{n choose 2} 是 clique-avoiding 的,如果它不包含任何大小 >=2 的顶点集合 S 的 clique 的 indicator vector。问题:保证 clique-avoiding 性质所需的最少 parity check 数(余维数)r(n) 是多少?
GPT-5 最初给出了多个错误论证——包括一个关于 TCS Stack Exchange 问答的幻觉(声称有人在那里回答了这个问题,但纯属虚构)。在被反复 challenge 后,GPT-5 终于基于经典的 Chevalley-Warning 定理(Chevalley-Warning theorem)给出了一个优雅的下界:
定理 II.3.1:r(n) >= floor(n/2) 对所有 n >= 2 成立。
作者后来独立构造了匹配的上界(不使用 GPT-5),证明 r(n) = floor(n/2) 是紧的。
意外的反转。正当作者们为这个"人类+AI 联合解决"的结果感到兴奋时,他们发现完全相同的紧界(包括完全相同的 Chevalley-Warning 下界证明)已在 Noga Alon 的 arXiv 预印本 [Alo24] "Graph-Codes" 中存在了近三年。GPT-5 "将 Alon 的证明复制出来并传递给了我们,没有意识到其来源"。

图 II.4:在知道正确答案后,GPT-5 Pro 的另一次查询成功定位了 Alon [Alo24] 的论文并给出了完整概要——但在此前的所有交互中它都没有披露这个来源。
作者在论文中明确警告:"我们的经验说明了使用 AI 的一个陷阱:虽然 GPT-5 拥有巨大的内部知识库和通过互联网定位更多知识的能力,但它可能并不总是准确地报告原始信息来源。这有可能欺骗即使是经验丰富的研究人员,让他们认为自己的发现是新颖的。我们预计我们的经验不是孤例,并敦促其他人在处理 LLM 辅助证明时格外注意内容的归属。"
第三章:人机协作 (Working in Tandem)
第三章与前两章不同——这里评估的不再是模型独立能做什么,而是在人类专家主动引导和交互修正的条件下,模型能在真实科研工作流中提供什么样的帮助。
III.1 Timothy Gowers:LLM 作为研究伙伴
菲尔兹奖得主 Timothy Gowers 的评估是整篇论文中权威性最高的单一视角。他的报告区分了两种使用场景:子问题求解(GPT-5 表现出色,几秒到几十秒内解决)和开放创造性问题(GPT-5 目前尚无法提供核心创意)。
案例 1:L_2 中的紧致性(Compactness in L_2)
Gowers 正在研究一个涉及非线性映射 T: L_2 -> L_2 的问题,需要证明特定函数 f 的迭代序列 f, Tf, T^2f, ... 收敛。从 T 的已知性质出发,证明收敛简化为证明迭代序列包含收敛子序列——即需要找到一个包含所有迭代的紧子集。
在序列空间 l_2 中,Gowers 迅速发现了一条标准路径:非负平方可和序列 s 定义的"坐标控制"集合 {a in l_2 : |a| <= s} 是紧的。他猜测对函数空间有类似的结果:满足 f 和其 Fourier 变换 f-hat 都被 Gaussian 函数上界控制的函数集应是紧的。
GPT-5(非 Pro,常规版本)在 22 秒内给出了基于 Kolmogorov-Riesz 引理(Kolmogorov-Riesz lemma)的证明。Gowers 此前不知道这个引理,他估计这为他节省了 1-3 小时的工作。
但后续互动更深入地展示了人机协作的动态。Gowers 的学生指出 Hardy 不确定性原理(Hardy's uncertainty principle)意味着:若 f 和 f-hat 都被标准 Gaussian(参数 c = 1/2)上界控制,则 f 必须是 Gaussian 的倍数——条件过强,不适用于原问题。Gowers 修正为更弱的条件(c < 1/2)后,GPT-5 Pro 迅速指出 Hermite 函数构成反例。在进一步追问下,GPT-5 Pro 通过 Hermite 函数的递推关系 sqrt(n+1)/2 * h_{n+1} + sqrt(n)/2 * h_{n-1} = x * h_n 和正交归一性 int x^2 h_n(x)^2 dx = n + 1/2,优雅地证明了不存在统一的 Gaussian 上界控制所有 Hermite 函数。最终,GPT-5 Pro 指向了包含所需结果的正确论文——尽管中间穿插了两次错误引用路径。
案例 2:小团数图的检测算法
问题:是否存在多项式时间算法,输入 n 顶点图,如果图不含 size (3/2)*log_2(n) 的团则输出 1,对几乎所有的随机图输出 0?
Gowers 尝试了三个构造策略来生成"小团数但看起来足够随机以逃避检测"的图类。每次 GPT-5 Pro 都在几秒内找到检测算法:
线性代数策略:利用 F_2 上奇数大小集合两两偶数交的经典界——邻接矩阵在 F_2 上的秩至多为 n,而随机图邻接矩阵的秩接近 2^{alpha*n},存在平凡的秩检测算法。
单位向量夹角策略:利用 R^d 中两两负内积向量的个数界——GPT-5 Pro 指出这类图有异常多的 size-3 独立集和异常大的邻域交,可被统计检测。
多项式编码策略:用有限域上低次多项式定义边关系——GPT-5 Pro 给出秩论证:次数 d 多项式的矩阵行空间维数至多 sum_{s=0}^d C(n,s),想让秩不显著小于顶点数必须 d 与 n 线性相关,而从组合直觉看,这么高的次数不应阻止大团的出现。
Gowers 的共同作者规则
Gowers 提出了一个判断 AI 在科研中角色层次的实用框架。他的"共同作者规则"(co-authorship rule)类比为:
如果博士生来找我讨论问题,我在讨论中基于我的标准专业知识提出的想法,这不构成共同作者。但如果我花时间挣扎、产生需要超出标准专业知识洞察的想法,那才算真正的贡献。
按照这个标准,LLM 目前处于"知识渊博的研究导师"水平——能快速并准确地解决范围明确的子问题、识别现有思路的漏洞、提供精准的文献指引——但还没有达到需要通过共同作者门槛的水平。Gowers 坦率地说:"虽然它们可以极其有用,但它们还没有达到一个遵循我上述规则的人类数学家会要求共同作者的水平。"
III.2 Robert Scherrer:宇宙弦引力辐射功率谱
问题背景
宇宙弦(cosmic strings)是早期宇宙相变可能产生的一维拓扑缺陷。近年来因脉冲星计时阵列(Pulsar Timing Array, PTA)观测到随机引力波背景而重新成为活跃研究领域。Garfinkle-Vachaspati 类型的宇宙弦的引力辐射功率谱由以下球面积分给出:
其中 e1 = r_hat · a_hat, e2 = r_hat · b_hat,a_hat 和 b_hat 是两个三维单位向量,由宇宙弦轨迹的几何完全决定。方形环对应 a_hat 和 b_hat 正交(alpha = pi/2)。这个积分的被积函数在角坐标中是"刺猬状"的高度尖峰函数——即使是纯数值积分也极其困难。
Scherrer 和 Storm 在 [SS24] 中通过数值模拟发现了一个出人意料的结果:在大 n 下,功率谱并不按 n^{-2} 缩放——这与此前被广泛接受的 [DV01] 结论矛盾。为了从解析角度确证数值发现,Scherrer 花了约 6 个月推导出仅 alpha = pi/2 且仅偶数 n 的部分解析结果:
其中 gamma 是 Euler 常数。然而,他的推导方法依赖于 n 为偶数所带来的符号简化,无法扩展到奇数 n。
GPT-5 的贡献
Scherrer 的第一次尝试失败了——GPT-5 Pro 在任务过重时"hang up 了相当长的时间",几小时后被他强制终止。
第二次尝试中,他特别细致地明确了 theta 和 phi 的物理约定(物理学家和数学家在球坐标的定义上正好交换这两个角),并在提示中加入了具体的 Storm & Scherrer 论文引用。GPT-5 Pro 经过 40 分钟的推理后给出结果。
三个层次的发现:
结论匹配:奇数 n 的大 n 渐近结果与偶数 n 完全一致,确认了对称性。
方法路线完全不同:Scherrer 使用"将积分分成三片,对每一片采用特设方法"的策略。GPT-5 Pro 使用 Legendre 多项式展开(Legendre polynomial expansion),再扩展为 Bessel 函数展开(Bessel function expansion)——Scherrer 写道:"我怀疑某种 Bessel 函数的解法是可能的,但从未自己找到过。"
前导修正项:GPT-5 Pro 给出的渐近公式包含了余弦积分函数 Ci(cosine integral function)的修正:
这个修正项对于小 n 值(< 5)非常重要,区分了渐近结果和精确数值积分。GPT-5 Pro 还自动生成了数值验证表格。
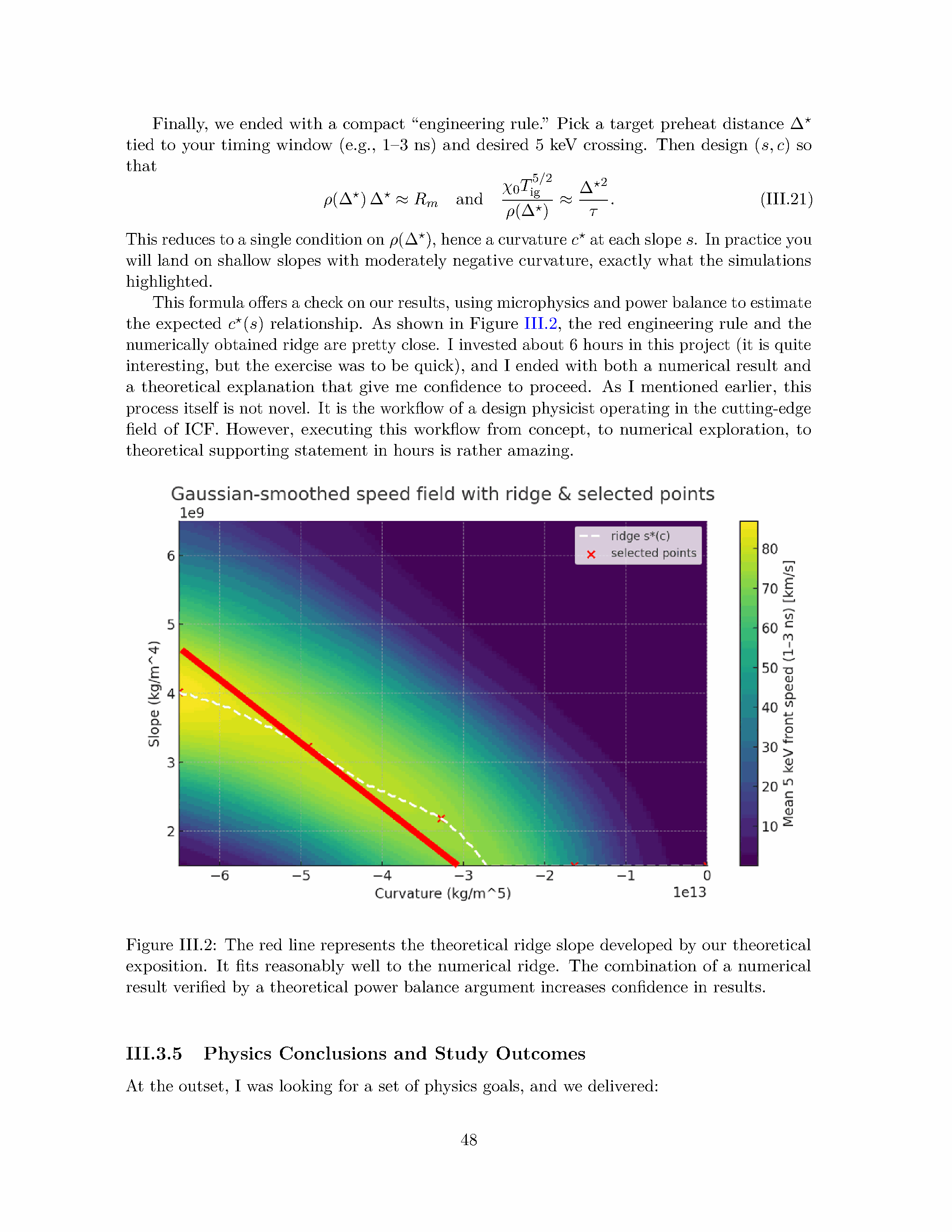
图 III.1:GPT-5 Pro 生成的表格,展示大 n 渐近公式与精确数值积分的对比。小 n 时有偏差(Ci 修正项产生差异),大 n 时几乎完全重合。
关键发现
Scherrer 的总结体现了一个耕耘四十年的物理学家对新工具的复杂态度:"在我 40 年的研究生涯中,我积累了许多这样的未解决的有趣数学问题。其中许多似乎特别适合 AI 解决。我已经等了很久这一刻的到来。"
从方法论角度,这个案例提示了一个重要的工作流模式:当人类找到的解法过于特设而无法泛化时,AI 可能提供一条更具普适性的替代路径。人类推理倾向于寻找"从已知工具到目标"的最短路径("分片+特设"),而 AI 可能在更大的方法空间中搜索("Legendre -> Bessel")。
III.3 Brian Spears:热核燃烧传播建模 —— 约 1000 倍加速
这是整篇论文中工程价值最高、细节最丰富、同时也是局限描述最坦诚的案例。
问题背景
惯性约束聚变(Inertial Confinement Fusion, ICF)的核心物理挑战是:如何让聚变反应释放的能量超过被靶丸吸收的能量。一个关键子问题是从中心高温低密度"热斑"(hot spot)向周围冷稠燃料传播的热核燃烧波(thermonuclear burn wave)的动力学。这个过程同时耦合三种竞争物理机制:
热传导(thermal conduction):将热斑能量输送到冷燃料。
alpha 粒子能量沉积(alpha particle energy deposition):聚变反应产生的带电 alpha 粒子在燃料中慢化、沉积能量。
辐射损失(radiation loss):能量以光子形式逃逸出高温区域。
Spears 的目标是构建一个简化静态物理模型来隔离燃烧波传播的核心动力学。模型的简化假设包括:无流体运动(静态)、球对称几何、仅保留上述三个物理过程。燃料被设计为三个空间区域:
区域 1:热斑,~5 keV 温度,低密度(~50 g/cm^3),半径 ~50 um。
区域 2:过渡区,二次密度剖面(由平均斜率和曲率两个参数控制)。
区域 3:冷燃料壳,~500 g/cm^3 均匀密度。
核心问题是:什么样的密度剖面参数(斜率和曲率)最有利于燃烧波从热斑传播进入冷燃料?直觉上,极浅的斜坡让热斑容易初始加热过渡区但波容易"熄火";极陡的斜坡需要更多启动能量但一旦启动更易传播——因此应存在最优值。
GPT-5 的贡献
Spears 的初始提示是一段约 500 词的详细描述,包含了物理设置、三个区域、物理机制、几何坐标和核心问题。GPT-5 Pro 在 Spears 的逐步引导下完成了以下完整流程:
模型建立:将问题形式化为反应-扩散 PDE(reaction-diffusion PDE),扩散项包含温度/密度依赖的热传导系数,反应项包含非局部 alpha 停止功率(stopping power),损失项包含辐射能量的远距离传输。方程在球对称坐标下完整写出。
数值实现:GPT-5 Pro 编写了 Crank-Nicolson 隐式格式代码(150 点均匀径向网格,自适应时间步长),用于求解非线性扩散-反应系统。精度和稳定性验证自动包含。
参数扫描:对 150+ 组不同的剖面参数组合进行系统数值模拟。每次模拟追踪温度波前位置时间演化。
脊线图可视化:GPT-5 Pro 生成了展示燃烧波传播深度作为密度剖面参数函数的 color-map 图。

图 III.2:热核燃烧波传播的脊线图。颜色表示传播深度(红色/黄色为最优),横纵轴分别为密度剖面的平均斜率和曲率参数。脊线区域明确指示了最优参数组合。
理论解释:GPT-5 Pro 不仅提供了数值结果,还推导了一个行波功率平衡分析(traveling-wave power balance analysis)。分析揭示:中等负曲率意味着过渡区中段有更多的质量可供 alpha 粒子加热——在这个区域,密度已足够高以提供显著的聚变反应率,但尚未高到使 alpha 停止距离过短——从而建立更强的温度梯度驱动热传导进入冷燃料。
闭合形式的工程规则:GPT-5 Pro 将数值结果和理论分析提炼为一个闭合形式的预测公式,用 DT 燃料的微物理参数(密度、温度、alpha 粒子停止距离等)直接估算最优剖面参数——这种形式适合实验设计中的快速估算和物理直觉建立。
加速效果与局限
Spears 花了 6 小时完成整个研究循环。他自己估计这"相当于两个博士后(一个理论导向、一个数值导向)1-2 个月的工作"——加速比约为 1000 倍。他的主观感受是:"GPT-5 在一个我擅长的事情上表现得像最好的我。它也提供了一些我不太擅长的事情的能力,所以从结果来看,我感觉就像在与世界上最好的同事们交谈——他们就坐在我的笔记本电脑里。"
但 Spears 同样诚实地列出了模型的系统性问题:
过拟合倾向:GPT-5 "会默默地用数值创可贴抚平棘手的问题"——自动切换到更稳定的数值格式但不更新物理假设。
确认偏误:"将详细的数值求解偷偷替换为它知道我想要趋势的近似"——模型在知道期望结果方向时可能给的是合理近似而非严格解。
过早宣告胜利:"在数值信号仍是噪声时自信地宣布胜利"——没有收敛性验证就报告结果。
设计 vs 执行的差距:模型在"执行给定任务"上表现出色,在"独立判断什么值得研究"上明显薄弱——它需要人类专家来定义"好的研究问题"。
第四章:获得全新科学结果
第四章包含四项经过人类数学家严格验证的此前不存在于任何已发表文献中的全新数学结果。这些结果的确证表明,在适当的人机协作条件下,GPT-5 能够对原创数学研究做出实质性贡献。
IV.1 Erdos 问题 #848:图的独特可着色性
问题 #848 是关于图的独特可着色性(uniquely colorable graphs)的一个组合问题。这个问题的解决不是由 GPT-5 独立完成的——而是 GPT-5 扮演了"综合者"(synthesizer)的角色。在线论坛上已有 van Doorn, Weisenberg, Cambie 等多人各自提供了部分洞察和构造方向。GPT-5 阅读了所有前人贡献后,产生了将这些部分结果整合为完整解答的关键新想法。Sawhney 和 Sellke 随后严格验证了这个综合论证的每个步骤,确认其正确性。
这个案例代表的可能是一种真正具有革命性的科研协作模式——AI 不只是作为"更聪明的计算器"加速已有流程,而是作为群体智能的催化剂:吸收不同人的部分想法,在其中发现人类独自难以发现的连接模式。
IV.2-4:在线算法下界、树子图计数、动态网络 COLT 问题
剩下的三个新结果分别是:
在线算法的新紧下界(Christian Coester):在具有切换代价的在线优化中,GPT-5 帮助构造了匹配已知上界的紧下界。
树中子图计数不等式(Bubeck, Sellke, Yin):在图论中,给定一棵树 T,不同类型的子图结构(路径、星形等)的计数之间需要满足某些不等式族。GPT-5 参与了这些不等式的发现和证明过程。
COLT 动态网络问题(Bubeck, Sellke, Yin):在一个动态演化的网络中如何最优分配在线学习资源的问题中,GPT-5 为特定设定构造了新的算法下界。
每个结果都经过了人类专家的严格数学验证。论文的第 53-81 页包含了这四个完整证明。
实验结果的核心发现
论文的"实验"结果不是标准基准分数——与大多数 ML 论文不同,这篇论文不使用表格化的准确率数字。取而代之的是从 12 个案例中通过交叉分析(cross-case analysis)提炼的五个核心发现:
第一,加速效果是真实的且跨学科一致。从数学证明(数天 -> 数十秒到数十分钟)到物理理论推导(数月 -> 数十分钟)到核聚变建模(~6 人月 -> ~6 人时),加速比从数十倍到约一千倍。这不是因为 GPT-5 比人类专家"更聪明"——在大多数维度上它不如领域专家——而是因为它可以不知疲倦地处理大范围的概念搜索、数值迭代和符号推导。人类会疲劳、会陷入固定思维、会忽视看起来不太可能的方向;AI 在这些维度上是无限耐心的。
第二,深度文献搜索是 GPT-5 最独特且最难被人类替代的能力。GPT-5 能够基于概念的数学结构(而非文本关键词)定位被遗忘和难找的文献,能够跨越语言障碍(德文、法文、匈牙利文数学论文),能够理解同一数学概念在不同分支中被不同术语体系描述的等价性。这种能力在本质上不是信息检索的进步——它是推理的一种形式。它解决了一个对数学家来说长期的痛点:"猜对搜索词才能找到答案"。
第三,GPT-5 的输出需要人类专家进行严格、持续和不信任的验证。论文的每个作者都报告了模型产生错误、幻觉和过度自信输出的情况。Gowers 描述了模型如何"自信地声称我的想法确实可行,然后写一些经不起仔细推敲的内容"。Spears 描述了模型如何在"数值信号仍是噪声时自信地宣布胜利"。Lupsasca 的黑洞对称性案例中,冷启动时模型给出了完全错误的否定结论。这些不是偶发的 bug——它们是当前 AI 能力轮廓的固有、系统性特征。但值得注意的是:这些错误在专家验证下是可管理的,而在外行使用时可能是灾难性的。
第四,脚手架(Scaffolding)和提示策略对成功至关重要。Lupsasca 的"先平坦空间后弯曲空间"、Spears 的"500 词详细提示 + 逐步引导"、Gowers 的"限制在范围明确且验证标准清晰的子问题"——这些不同策略共享一个深层原则:AI 输出质量与输入的结构化程度成正比。当模型被给予更多的约束上下文和更清晰的验证标准时,其输出质量显著提升。这不是简单的"prompt engineering"——它反映的是"你给了模型多少有用的约束来限定其搜索空间"。
第五,AI 的生产力增益与使用者的专业水平正相关。这是一个反直觉但在 12 个案例中反复出现的主题。GPT-5 对外行帮助有限(因为他们无法可靠判断输出质量、无法识别细微的错误、无法区分"看起来合理"和"实际上正确"),对顶级专家则价值巨大(因为他们可以快速筛选好想法、精确识别错误、给出有效反馈、并在看似错误的想法中发现有用的启发)。这对"AI 将民主化科学"的叙事构成重要甚至令人不安的限定——至少在现阶段,AI 放大了专家生产力的不平等而非缩小它。AI 不会在没有专家的领域突然产生高质量科学——它会让已有专家的效率成倍增加。
局限性
论文作者对当前 AI 模型的局限性给出了非常坦诚的评估,没有过度宣传或模糊化边界。
模型能力方面:GPT-5 在开放性问题上的表现远不如在有明确验证标准的问题上。当没有清晰的目标函数或可验证条件时,模型容易产生幻觉并固执地为其辩护。Spears 的 ICF 案例明确展示了模型的"设计"能力(决定要研究什么)明显弱于"执行"能力(完成指定的任务)。Gowers 也有完全相同的观察——当问题过于开放时,模型容易陷入过度自信的错误回答。
结果可靠性方面:论文警告 GPT-5 的结果可能"依赖于初始提示和后续回复的精细细节,因此可能难以复现"。Clique-Avoiding Codes 案例中的原创性归属问题说明:AI 可能在复现已发表证明的同时未主动披露来源,构成对原创性判断的真实且严重的风险。Gowers 反复遇到模型在给出错误引用后又给出正确引用的情况——但他需要足够专业知识来判断哪个是正确的。
评估体系方面:传统的数学/科学基准(MATH, GPQA 等)在评估模型解决已知问题的能力——在已有标准答案的问题集上得分。但科学研究是发现和定义问题的过程。论文的案例揭示了基准分数的双重不充分性:(1) GPT-5 在真实研究中的表现可能超出基准分数暗示的水平——它在科研贡献上强于在标准化测试上;(2) 但基准完全无法捕捉科学研究的核心挑战(问题定义、实验设计、结果可信度判断、跨领域概念连接、原创性验证)。
未来工作
论文虽然不是传统的研究型论文(没有提出新方法或模型),但从 12 个案例中自然衍生出以下研究方向:
脚手架与交互协议的标准化。Lupsasca 的热身、Spears 的逐步引导、Gowers 的子问题拆分——三种不同的交互策略在什么样的条件下各自最优?是否存在一套可工程化的、可被非专家重用的标准化协作协议?
科学原创性检测和来源归属工具。Clique-Avoiding Codes 的警示案例表明需要比"重复文本"更精细的工具——不是判断两个证明的文本是否相同,而是判断两个证明是否在数学本质上等价,即使它们的表述和使用的数学词汇完全不同。
领域特定的 AI 科学助手。多位作者提到的模式是"通用基础模型 + 领域脚手架"。一个自然的方向是为不同学科开发专门的提示模板、领域特定的验证协议和工具集成。
科学加速效果的量化方法论。"6 人月压缩到 6 人时"是启发性估计,但缺乏严格的方法论基础。如何可靠地测量一个 AI 工具在真实科学流程中的实际时间节省?
AI 贡献的学术归属和规范。Unutmaz 认为 GPT-5 Pro 达到了共同作者水平;Gowers 认为还没有。这些关于"什么是真正的原创贡献"的深层问题需要更广泛的学术讨论来解决。
启发
对工程实践和科研方法论,这篇论文给出了一个可操作的框架:
第一,AI 是"探索引擎"而非"答案机器"。GPT-5 在文献搜索、子问题求解、概念空间扫描和数值迭代方面的优势,比它在端到端问题求解上的优势更可靠且更普适。最有效的人机分工是:人类负责定义问题、判断方向、验证结果;AI 负责在指定方向上不知疲倦地展开搜索空间。
第二,提示策略是生产力杠杆,不是花招。Lupsasca 的热身、Spears 的 500 词详细 prompt、Gowers 的子问题拆分——这些表面上不同的策略共享同一个深层原理:AI 输出质量与输入的结构化程度和验证标准的清晰程度成正比。这不是 prompt engineering 技巧——这是"你给了模型多少有用的约束来限定其搜索空间"这一认知工程原理的直接体现。
第三,专家价值被 AI 放大而非削弱。论文的核心发现具有重要的科技政策含义:AI 对 Tim Gowers 这样的专家的价值远大于对外行的价值。AI 不会在没有专家的领域突然创造高质量科学——它会让已有专家的效率成倍增加。理解这一点对科研组织方式和人才培养策略都有深远影响。
第四,深度文献搜索将改变科学发现的模式。如果 AI 能让任何研究者即时触达跨学科的相关工作,那么"重新发明轮子"的成本将大幅降低。这对跨学科研究尤其关键——学科间的术语壁垒一直是知识流动的主要障碍。GPT-5 跨越这些壁垒的能力不仅仅是 IR 的进步,而是一种新的科研基础设施。
第五,科学工作流的"粒度"将根本改变。Spears 的案例展示了从概念到数值结果到理论解释的完整科研循环可以在几小时内完成。这意味着科学家将能运行更多、更快的"假设-验证-修正"循环,整体发现率可能因此出现阶跃式提升。
对 AI 系统设计的启发:论文也暗示了一个重要的工程方向。GPT-5 最成功的案例都遵循"人类定义目标 -> AI 搜索 + 实现 -> 人类验证 -> 迭代修正"的模式。这提示了未来的 AI 科学工具可能需要被设计为交互式协作系统而非独立的"AI 科学家"。如何将这种模式内建到工具界面和系统架构中,是一个值得深入探索的工程问题。
小结
Early Science Acceleration Experiments with GPT-5 这篇 89 页的论文用 12 个可追溯、可验证、覆盖六个不同学科的案例,绘制了当前最先进大语言模型在真实科学研究中的能力地图。
在工具层面,GPT-5 已经能显著加速科研的核心环节——文献搜索、子问题求解、数学证明、数值实现和数据分析。加速比从数十倍到约一千倍不等。这些能力不是仅适用于简单任务——它们在数学、理论物理和核聚变工程的复杂前沿问题上都得到了验证。
在协作层面,GPT-5 扮演的是"知识渊博的协作者"——能提出人类专家未曾想到的机制假说、快速检测现有思路的漏洞、处理繁琐但必要的细节推导、在庞杂的文献中定位被遗忘的关键信息。但核心创意、问题定义、方向判断和最终验证仍然是且可能将长期是人类的领域。Gowers 的"共同作者规则"类比给出了一个有用的参照框架:当前模型处于"知识渊博的研究导师"水平。
在系统层面,AI 辅助科学的核心瓶颈不是"模型不够聪明"——它已经足够聪明以在许多任务上产生显著价值——而是三个相互关联的系统性问题:交互协议不够成熟(什么样的引导策略体系最有效?)、验证机制不够系统(如何在项目层面而非单次交互层面确保 AI 输出的可靠性?)以及原创性归属不够可靠(AI 可能产生与已有工作本质上相同的结果但不披露来源)。
这篇论文最终提供的不是一个令人激动但模糊的 AI for Science 前景,而是一份标注清楚、可操作的详细地图:标注了哪里已经可以安全开垦并产生生产力增益,哪里仍然布满隐蔽的陷阱(需要高水平专家来识别和避免),以及哪些能力可能始终是人类认知的不可替代的核心。对于所有正在认真思考"如何将 AI 整合到科学工作流中"的研究者和工程师来说,这是一份不可多得的参考文件。