
DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence论文阅读
摘要
本文解读 DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence。论文的核心不是单纯扩大参数规模,而是通过混合压缩注意力、mHC 残差连接、Muon 优化器和配套系统工程,把百万 Token 上下文从能力展示推进到可训练、可推理、可部署的模型设计问题。
DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence论文阅读
写在前面
DeepSeek-V4 讨论的问题:推理模型需要更长的思考链,智能体任务需要更长的历史轨迹,多文档分析需要更大的上下文窗口,但标准注意力机制在超长序列下会被计算量和 Key-Value Cache,键值缓存,拖住。
这篇论文的主线不是提出一个单点技巧,而是把百万 Token 上下文拆成一个系统问题:模型结构要压缩注意力,训练过程要稳定,推理系统要管理异构 KV 缓存,后训练还要让模型在不同推理预算下可控工作。后文按照这一条线展开。
本文重点回答七个问题:DeepSeek-V4 要解决什么瓶颈;它的核心结构怎么设计;Compressed Sparse Attention,压缩稀疏注意力,和 Heavily Compressed Attention,高压缩注意力,分别解决什么问题;Manifold-Constrained Hyper-Connections,流形约束超连接,为什么重要;Muon 优化器和系统工程如何支撑训练;实验结果说明了什么;这些设计对长上下文、RAG 和 Agent 系统有什么启发。
速读卡片
项目 | 内容 |
|---|---|
论文 | DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence |
作者 | DeepSeek-AI |
年份 | 2026 |
模型 | DeepSeek-V4-Pro 与 DeepSeek-V4-Flash |
规模 | Pro 为 1.6T 参数、49B 激活参数;Flash 为 284B 参数、13B 激活参数 |
上下文 | 原生支持 1M Token 上下文 |
核心方法 | 混合 CSA/HCA 注意力、mHC 残差连接、Muon 优化器、FP4 量化感知训练、异构 KV Cache 管理 |
主要结论 | 在 1M Token 场景下,V4-Pro 相比 DeepSeek-V3.2 只需要 27% 单 Token 推理 FLOPs 和 10% KV Cache;V4-Flash 分别为 10% 和 7% |
模型页 | |
适合读者 | 关注长上下文模型、MoE 架构、Agent 系统、RAG 工程和大模型训练系统的读者 |
一句话概括
DeepSeek-V4 用混合压缩注意力降低百万 Token 上下文的计算和存储成本,再用 mHC、Muon、量化和系统工程维持训练稳定性与推理效率,使长上下文能力不再只是扩展窗口长度,而是成为模型架构和系统协同设计的结果。
研究问题
Large Language Model,大语言模型,过去几年主要沿着参数规模、数据规模和后训练能力扩展。推理模型出现后,Test-Time Scaling,测试时扩展,进一步把计算转移到推理阶段,通过更长的思考过程提升复杂任务表现。但这会带来一个矛盾:模型越需要长程推理,注意力计算和 KV Cache 越容易成为瓶颈。
标准 Transformer 注意力的序列复杂度接近平方级。即使模型本身有足够参数,1M Token 的上下文仍然会让单次生成的显存、带宽和延迟快速上升。传统解决方法通常包括稀疏注意力、滑动窗口、检索增强或上下文压缩,但这些方法各自存在损失全局信息、工程复杂或任务适配不足的问题。
DeepSeek-V4 的问题设定可以概括为三点。第一,如何让百万 Token 上下文在训练和推理中都可承受。第二,如何在强压缩后仍保留足够的全局信息和局部细节。第三,如何让模型在非思考、高强度思考和最大思考模式之间切换,从而服务不同成本和准确率需求。
核心贡献
论文的贡献可以按模型、注意力、训练、系统和后训练五个层次理解。
模型层面,DeepSeek-V4 给出两个 Mixture-of-Experts,混合专家模型。DeepSeek-V4-Pro 更强调能力上限,总参数达到 1.6T,每个 Token 激活 49B 参数;DeepSeek-V4-Flash 更强调性价比,总参数 284B,每个 Token 激活 13B 参数。两者都原生支持 1M Token 上下文。
注意力层面,论文提出混合 CSA/HCA 架构。CSA 先沿序列维度压缩 KV Cache,再用稀疏选择降低注意力计算;HCA 使用更强压缩,把更长跨度的 KV 信息合并为少量条目,并保留密集注意力。两者交错使用,使模型同时具备较好的细节保持和长程覆盖能力。
结构层面,论文引入 mHC,用来增强传统残差连接。普通残差连接主要做相邻层之间的信息传递,mHC 进一步约束残差映射所在的流形,目标是在深层网络中稳定信号传播,同时保留表达能力。
优化层面,论文在大部分模块上使用 Muon 优化器,在嵌入层、预测头、RMSNorm 等部分继续使用 AdamW。Muon 的目标是改善收敛速度和训练稳定性,尤其适合这种结构复杂、规模很大的模型。
系统层面,论文做了大量工程配套,包括 MoE 融合 Kernel、TileLang 内核开发、可复现的确定性算子、Muon 的混合 ZeRO 训练策略、异构 KV Cache 布局、前缀复用和 FP4 Quantization-Aware Training,量化感知训练。这些内容说明,百万 Token 上下文不是单靠模型结构就能实现的。
方法
整体架构
DeepSeek-V4 仍然保留 Transformer 主体和 DeepSeekMoE,同时继承 Multi-Token Prediction,多 Token 预测,模块。新增部分主要集中在三处:注意力层使用 CSA/HCA 混合结构,残差路径使用 mHC,训练中使用 Muon 优化器。
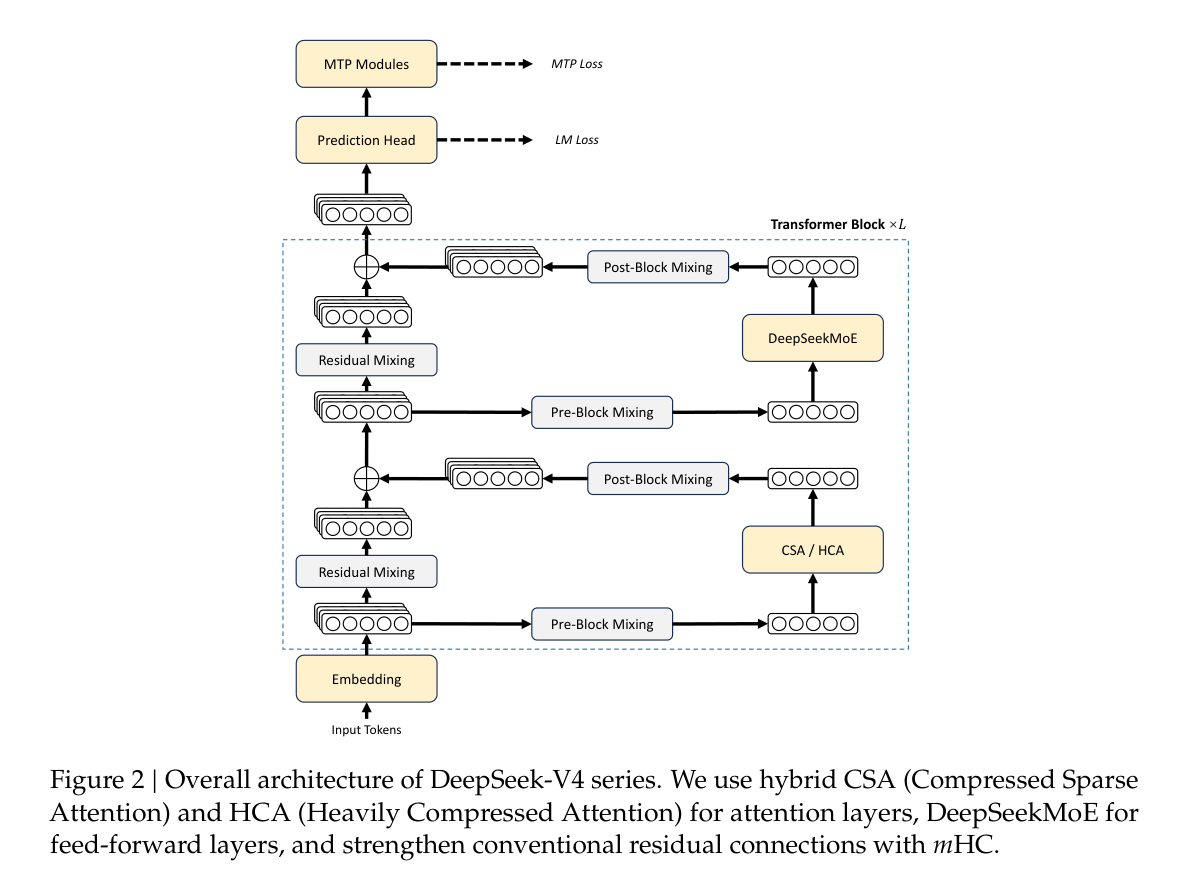
图 2 展示了 DeepSeek-V4 的整体结构。右侧是常规 Transformer Block 中的注意力层和 DeepSeekMoE 前馈层,左侧是 mHC 带来的跨层混合路径。这里的关键不是把模块堆得更多,而是在信息流上增加可控混合,使深层网络在复杂训练中更稳定。
CSA:压缩后再稀疏选择
Compressed Sparse Attention,压缩稀疏注意力,解决的是长上下文下注意力计算过大的问题。它先把每 m 个 Token 的 KV Cache 压缩为一个条目,再通过轻量 Indexer,索引器,选择 Top-k 个压缩条目参与注意力计算。为了避免只看压缩后的粗粒度信息,CSA 还保留一小段 Sliding Window Attention,滑动窗口注意力,用于捕获局部依赖。
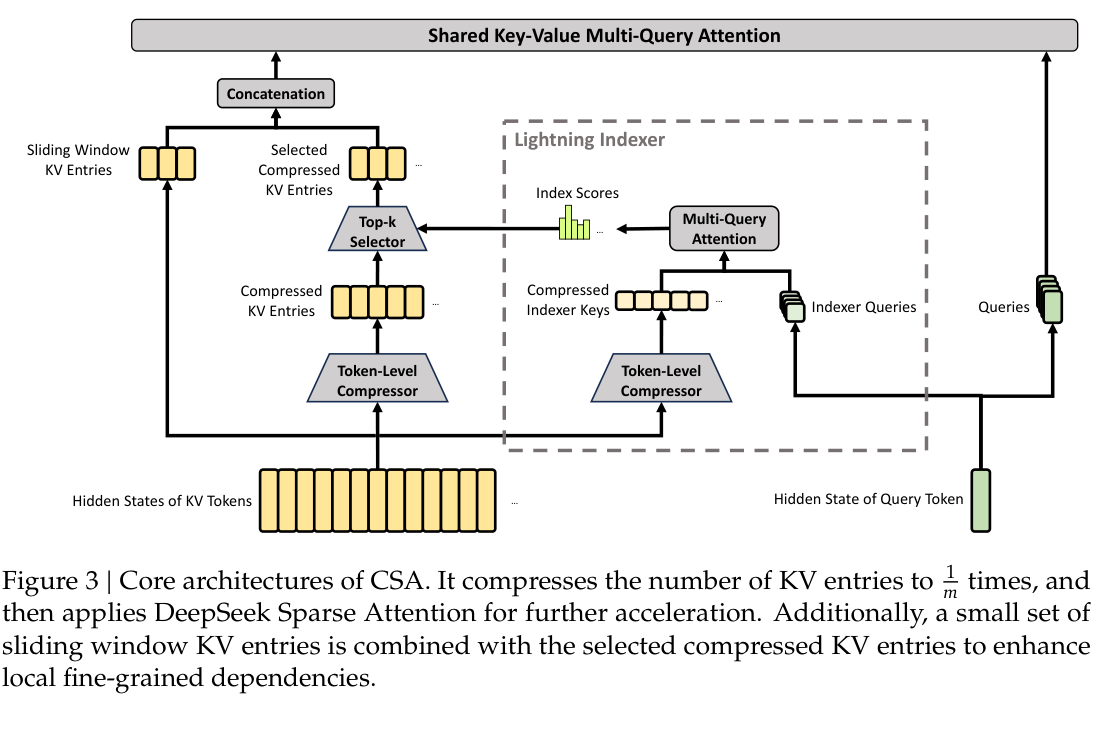
CSA 的核心逻辑可以概括为三个步骤。第一,将连续 Token 的 KV 信息压缩,减少缓存长度。第二,用 Indexer 在压缩后的 KV 条目中选择最相关部分。第三,将选中的压缩 KV 与滑动窗口 KV 拼接,再执行共享 Key-Value Multi-Query Attention,多查询注意力。
这种设计的优势在于,它不是简单丢弃远距离上下文,而是通过压缩和检索式选择保留全局信息。代价也很明确:模型需要学习压缩表示和选择机制,训练与推理实现都会更复杂。
HCA:更强压缩换取更低成本
Heavily Compressed Attention,高压缩注意力,采用更大的压缩率。论文中 HCA 将每 m' 个 Token 的 KV Cache 合并为一个条目,其中 m' 远大于 CSA 的 m。与 CSA 不同,HCA 不再做稀疏选择,而是在高度压缩后的 KV 条目上执行密集注意力。
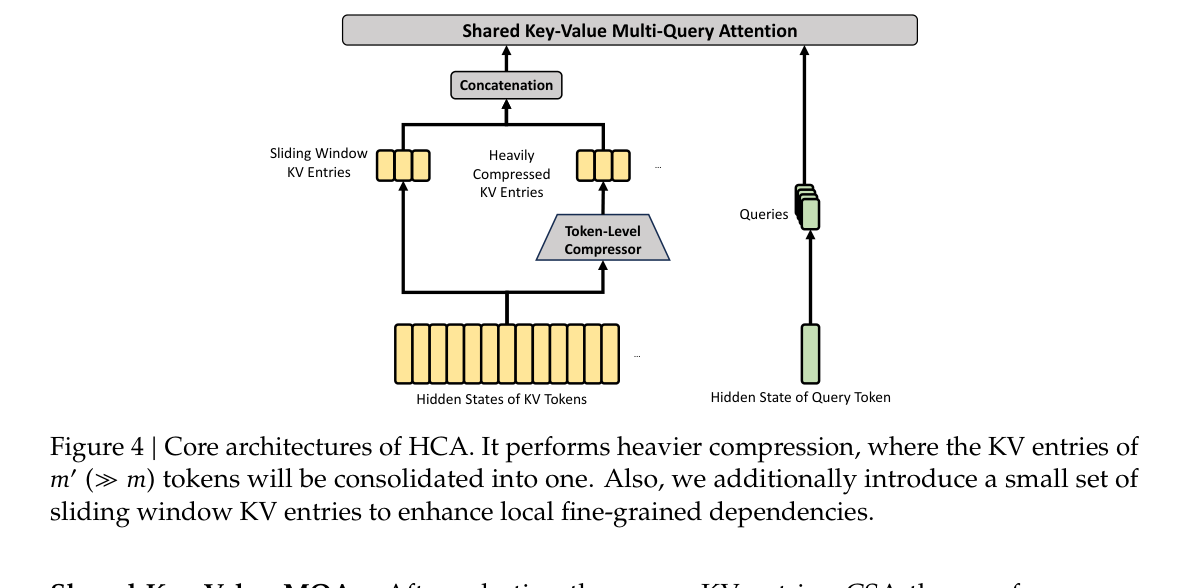
HCA 更适合承担长距离、低分辨率的信息保留。它牺牲部分细节,换取更低的 KV Cache 和计算开销。DeepSeek-V4 不单独依赖 CSA 或 HCA,而是交错使用二者。这样做的原因很清楚:CSA 保留相对细粒度的可选择信息,HCA 提供更大范围的全局覆盖,二者合起来才能支撑 1M Token。
mHC:让深层信息传播更稳定
mHC 的全称是 Manifold-Constrained Hyper-Connections,流形约束超连接。传统残差连接把上一层输出直接加到下一层,能够缓解深层网络训练退化,但在更深、更复杂的结构中,信息传播仍可能不稳定。
mHC 的思路是把残差信息映射限制在特定流形上,再通过 Pre-Block Mixing 和 Post-Block Mixing 控制进入和离开 Block 的信息混合。直观地说,它让层间信息流不只是简单相加,而是以更受约束的方式组合。论文认为这能提升信号传播稳定性,同时不明显损失表达能力。
Muon 与系统工程
Muon 是论文中另一个重要变化。它不是单独替代所有优化器,而是与 AdamW 分工使用。大部分权重使用 Muon,嵌入层、预测头、mHC 中的静态偏置和门控因子、RMSNorm 权重仍使用 AdamW。这样的设计更接近工程折中:在大规模矩阵权重上利用 Muon 的收敛特性,在对数值稳定更敏感的模块上保留成熟方案。
系统工程部分同样关键。论文提到的 TileLang 是 Domain-Specific Language,领域专用语言,用于平衡算子开发效率和运行效率。ZeRO 是 Zero Redundancy Optimizer,零冗余优化器,用于降低分布式训练中的显存冗余。FP4、FP8 和 BF16 分别是 4 位浮点、8 位浮点和 Brain Floating Point 16 位浮点格式,用于在不同路径上权衡精度、速度和显存。
这些细节共同指向一个结论:DeepSeek-V4 的长上下文效率来自结构、优化器、数值精度、内核和缓存管理的共同设计,不是单个注意力模块的结果。
训练与后训练
预训练阶段,DeepSeek-V4-Flash 使用 32T Token,DeepSeek-V4-Pro 使用 33T Token。论文强调两者在预训练后就能原生支持 1M 上下文,这一点与后期通过外部技巧扩展上下文窗口不同。
后训练采用两阶段范式。第一阶段是领域专家训练,分别面向数学、代码、Agent 和指令跟随等目标训练专家模型。这里使用 Supervised Fine-Tuning,有监督微调,和 Reinforcement Learning,强化学习,其中强化学习使用 Group Relative Policy Optimization,组相对策略优化。第二阶段是 On-Policy Distillation,在线策略蒸馏,将多个专家能力合并回统一模型。
论文还给出三种推理模式。Non-think 面向常规任务,强调低延迟。Think High 面向复杂任务,允许更多推理 Token。Think Max 面向最难任务,使用更长上下文和更高推理预算。这个设计很有工程意义,因为真实应用里并不是所有问题都值得使用最高成本模式。
实验结果
效率:百万 Token 的核心指标不是窗口长度,而是成本
论文首页给出了最重要的效率对比。在 1M Token 场景下,DeepSeek-V4-Pro 相比 DeepSeek-V3.2 的单 Token 推理 Floating Point Operations,浮点运算次数,只需要 27%,KV Cache 只需要 10%;DeepSeek-V4-Flash 分别只需要 10% 和 7%。
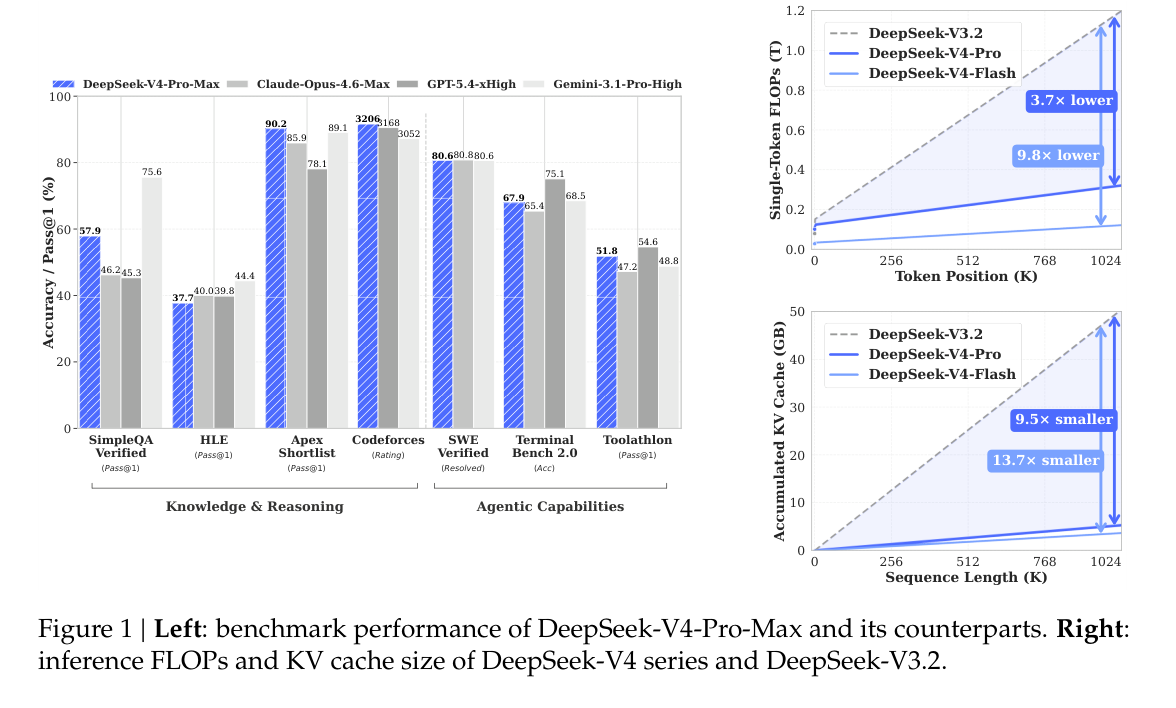
这张图说明,DeepSeek-V4 的目标不是单纯宣布上下文窗口达到 1M,而是让 1M 上下文在推理成本上接近可用。对于长文档分析、代码仓库理解和长轮次 Agent 来说,这比窗口大小本身更关键。
基座模型:Pro 提升能力上限,Flash 强调参数效率
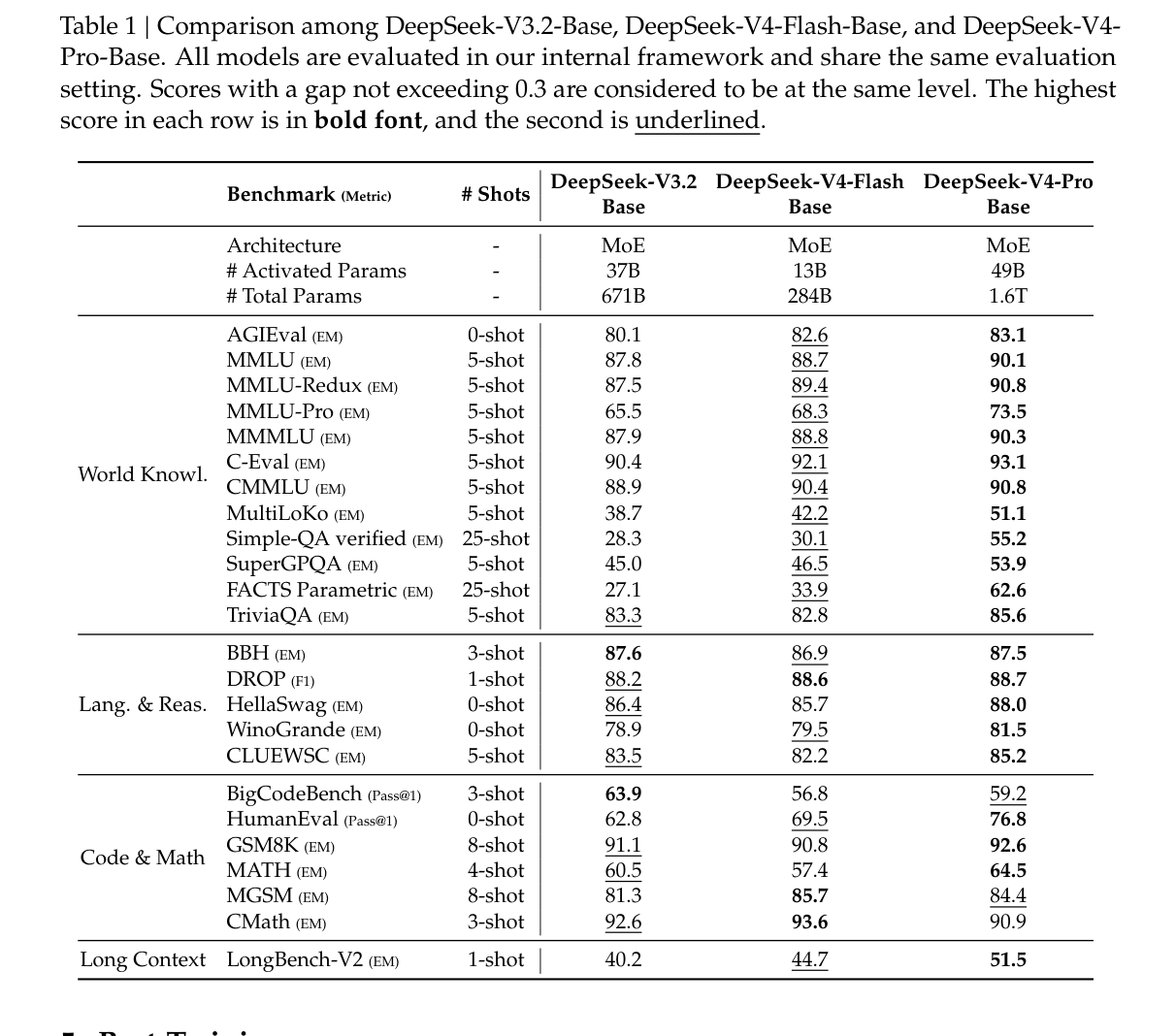
表 1 对比了 DeepSeek-V3.2-Base、DeepSeek-V4-Flash-Base 和 DeepSeek-V4-Pro-Base。结果显示,V4-Pro-Base 在多数知识、语言推理、代码数学和长上下文指标上领先。V4-Flash-Base 虽然激活参数更少,但在不少指标上也超过 V3.2-Base,说明架构效率确实转化为了模型能力。
需要注意的是,表中评估来自论文内部框架。它能说明模型之间的相对趋势,但仍需要第三方复测来确认不同应用场景下的稳定性。
对比闭源与开源模型:开源模型的上限继续逼近
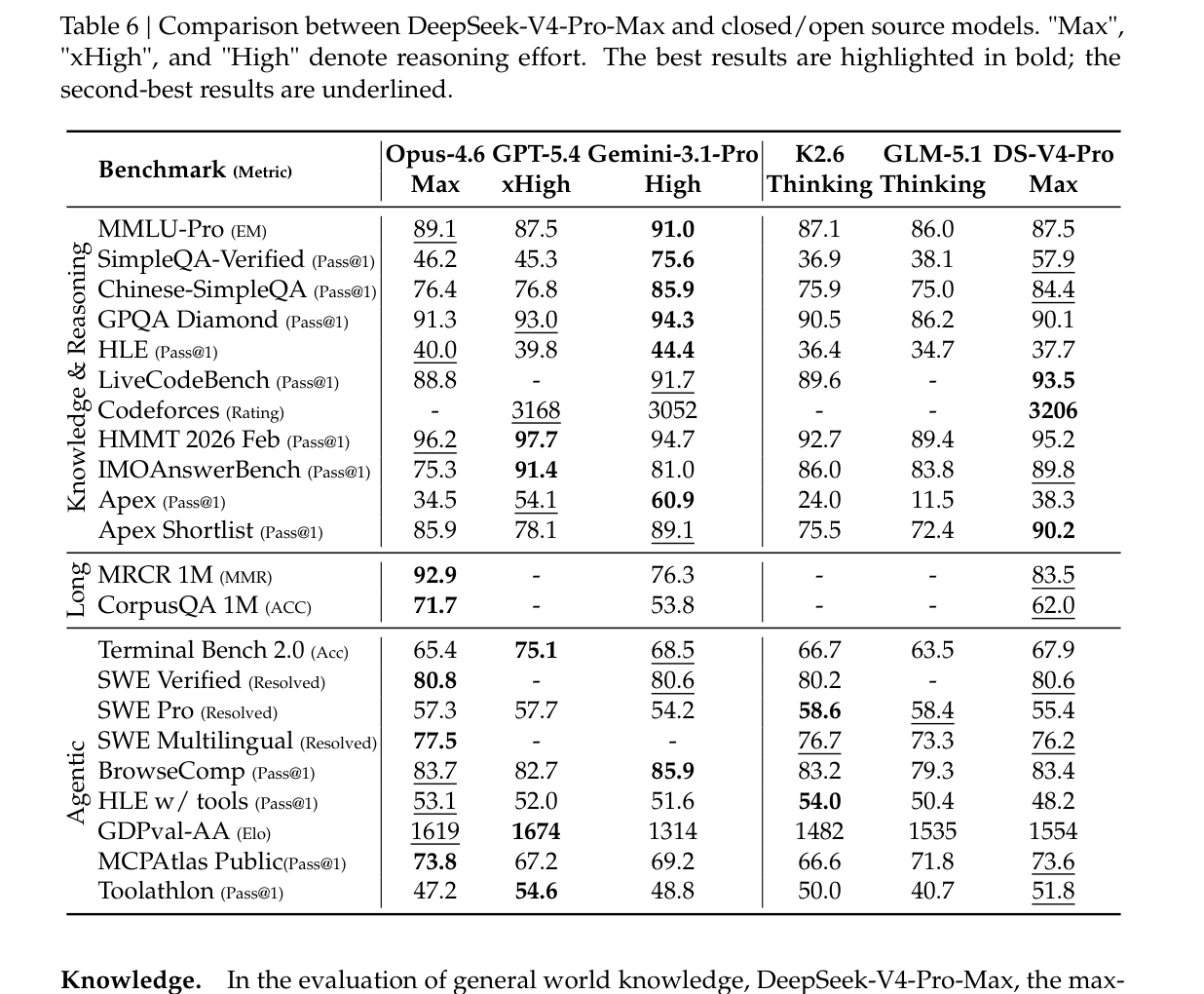
表 6 展示 DeepSeek-V4-Pro-Max 与多个闭源和开源模型的对比。DeepSeek-V4-Pro-Max 在 Codeforces、LiveCodeBench、Apex Shortlist、SWE Verified、MCPAtlas Public 和 Toolathlon 等任务上表现很强。长上下文部分,MRCR 1M 达到 83.5,CorpusQA 1M 达到 62.0。
但这张表也说明了边界。Gemini-3.1-Pro High 在 SimpleQA-Verified、Chinese-SimpleQA、GPQA Diamond 等知识指标上仍然明显领先;Claude Opus-4.6 Max 在 MRCR 1M 和 CorpusQA 1M 上更强。因此,DeepSeek-V4-Pro-Max 可以认为显著提升了开源模型上限,但还不是在所有维度上超过最强闭源模型。
推理模式:更多 Token 能换来更强能力,但不是线性收益
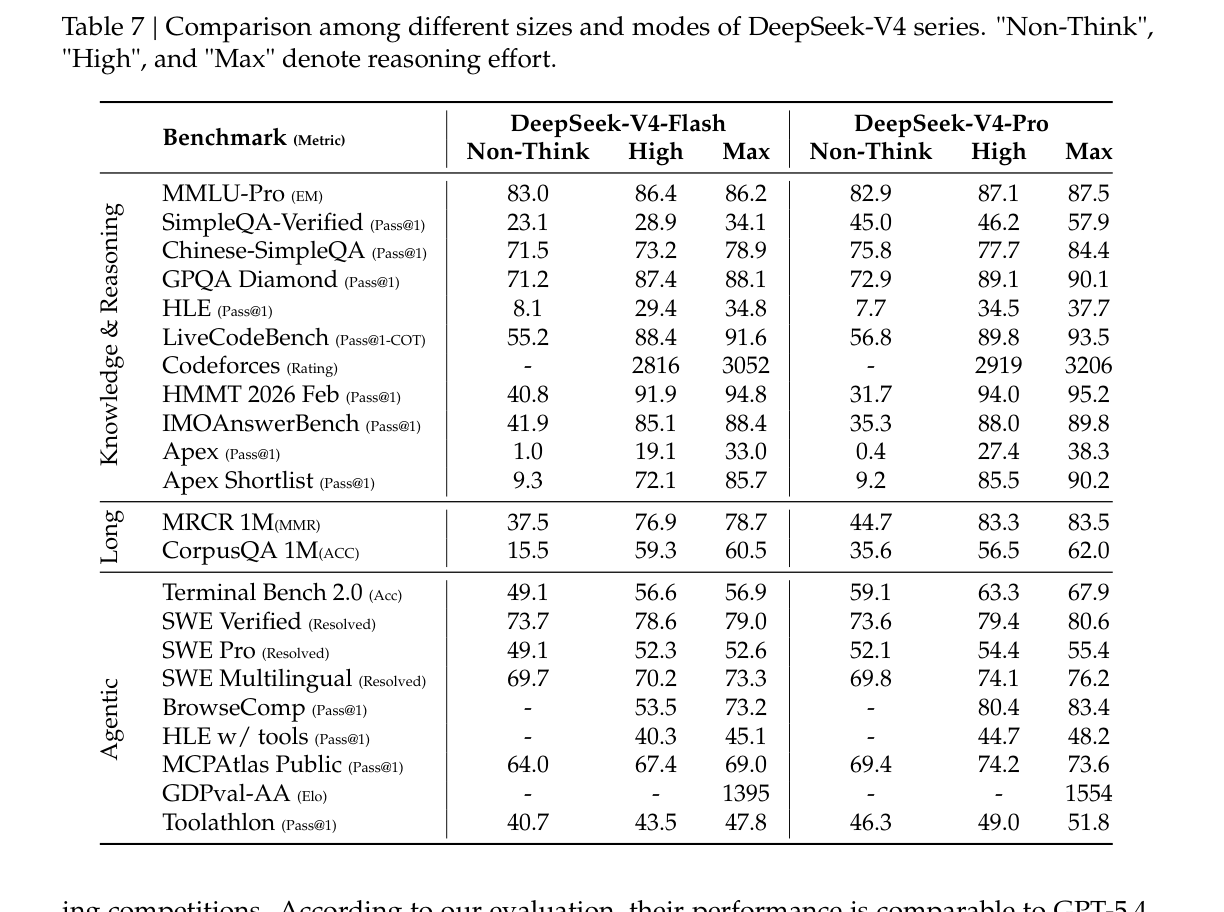
表 7 的价值在于,它把模型能力和推理预算的关系展示得很清楚。以 MRCR 1M 为例,DeepSeek-V4-Pro 从 Non-Think 的 44.7 提升到 High 的 83.3,Max 为 83.5;DeepSeek-V4-Flash 从 37.5 提升到 76.9,Max 为 78.7。长上下文任务明显受益于更高推理预算。
但提升不是无限的。Pro 在 MRCR 1M 上从 High 到 Max 几乎不再提升,而 Flash 仍有小幅提升。这说明推理预算需要根据模型规模和任务类型配置。工程上更合理的做法是先路由任务难度,再决定是否启用高推理模式,而不是所有请求默认 Max。
长上下文:128K 后开始出现退化
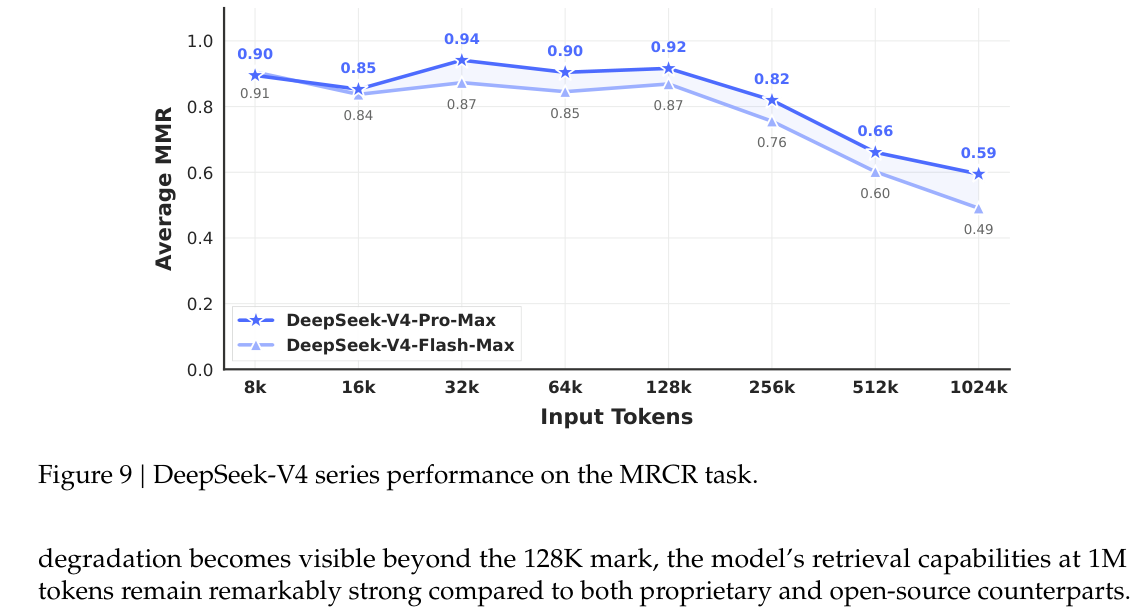
Figure 9 展示 MRCR 8-needle 任务在不同输入长度下的结果。DeepSeek-V4-Pro-Max 在 8K 到 128K 范围内表现稳定,128K 后开始下降,1024K 时仍保持 0.59。DeepSeek-V4-Flash-Max 走势相似,但整体略低。
这个结果很重要。1M 上下文并不意味着模型在任意 1M 输入上都能无损理解。对于实际工程,长上下文仍然需要结构化输入、章节索引、问题路由和必要的检索机制。也就是说,长上下文能力会削弱一部分 Retrieval-Augmented Generation,检索增强生成,压力,但不会直接替代 RAG。
推理成本:强能力来自更高预算
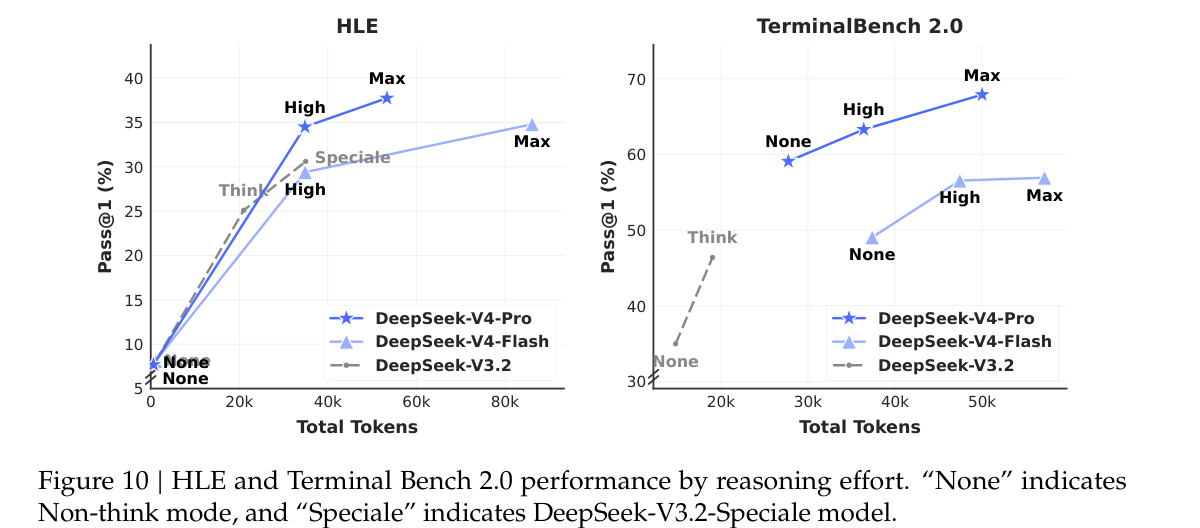
Figure 10 对比 HLE 和 TerminalBench 2.0 上不同推理努力程度的表现。HLE 是 Humanity's Last Exam,综合高难度知识与推理评测;TerminalBench 2.0 是面向终端环境任务的 Agent 评测。图中可以看到,DeepSeek-V4-Pro 随 Token 预算增加持续提升,而 Flash 的收益更早趋缓。
这说明推理模式不仅是产品选项,也是成本控制策略。高价值任务可以使用 Think Max,常规问答和简单文档任务更适合 Non-think 或 Think High。
局限性
论文自身也承认,DeepSeek-V4 为了追求极端长上下文效率,采用了较复杂的架构。CSA、HCA、mHC、Muon、FP4 量化和系统内核优化叠加在一起,提升了效率,也提高了复现、调试和后续演进成本。
训练稳定性仍有待进一步解释。论文提到 Anticipatory Routing 和 SwiGLU Clamping 对缓解训练不稳定有效,但其原理仍没有完全清楚。对于这种规模的模型,知道某个技巧有效还不够,未来更需要可预测、可监控的训练稳定性理论和指标。
评估也需要谨慎理解。论文包含大量与闭源模型的对比,但闭源模型版本、推理预算和评测协议难以完全复现。DeepSeek-V4 在开源模型中表现突出,但在知识类任务和部分长上下文任务上仍落后于最强闭源模型。
最后,百万 Token 上下文不等于所有长程任务都被解决。MRCR 结果显示,超过 128K 后性能开始下降。真实任务中的噪声、重复、跨文档冲突和权限边界会进一步增加难度。
未来工作
论文给出的未来方向主要有五类。第一,继续简化架构,把当前有效但复杂的设计蒸馏为更本质、更优雅的结构。第二,研究训练稳定性,尤其是 Anticipatory Routing、SwiGLU Clamping 等技巧背后的机制。第三,探索 MoE 和稀疏注意力之外的新稀疏维度,例如更稀疏的 Embedding,嵌入模块。第四,优化低延迟架构和系统技术,让长上下文交互更快。第五,继续扩展长程多轮 Agent、多模态能力以及数据筛选和合成策略。
这些方向都指向同一个趋势:下一代大模型不会只比较参数量,而会比较在固定成本下能维持多长的有效推理链、能管理多大的工作记忆、能否在真实工具环境中稳定完成任务。
启发
对工程实践来说,DeepSeek-V4 最大的启发是长上下文不是 RAG 的反面。更长上下文可以减少短文档切片和反复检索的成本,但当输入达到几十万甚至上百万 Token 时,问题会从找不到信息变成如何组织信息、压缩信息和控制推理预算。
对 Agent 系统来说,1M 上下文会让长期任务日志、工具调用轨迹和多轮反馈更容易进入同一个上下文窗口。但 Agent 仍然需要外部记忆、权限控制、工具校验和任务路由。模型上下文变长,只是降低了记忆管理的压力,不会消除工程约束。
对模型架构来说,DeepSeek-V4 说明注意力设计正在从单纯稀疏化走向混合压缩。局部窗口、压缩 KV、稀疏选择、低精度存储和缓存布局会成为长上下文模型的基础组件。未来模型能力提升,很大一部分会来自这些看起来不显眼的系统细节。
对使用者来说,推理模式值得被显式管理。不是所有任务都应该交给最高推理预算。合理的策略是按任务难度、答案风险和成本预算选择 Non-think、Think High 或 Think Max。这样才能把模型能力稳定转化为可用生产力。
小结
DeepSeek-V4 的核心价值在于,它把百万 Token 上下文做成了一个完整系统:CSA/HCA 解决注意力效率,mHC 改善深层信息传播,Muon 和系统工程支撑训练稳定与推理效率,后训练和推理模式让能力按成本释放。
这篇论文对长上下文模型、RAG 和 Agent 都有直接参考价值。它说明未来的模型竞争不会只看谁的窗口更长,而要看谁能在更低成本下维持有效上下文、稳定推理和真实任务表现。