
Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models论文阅读
摘要
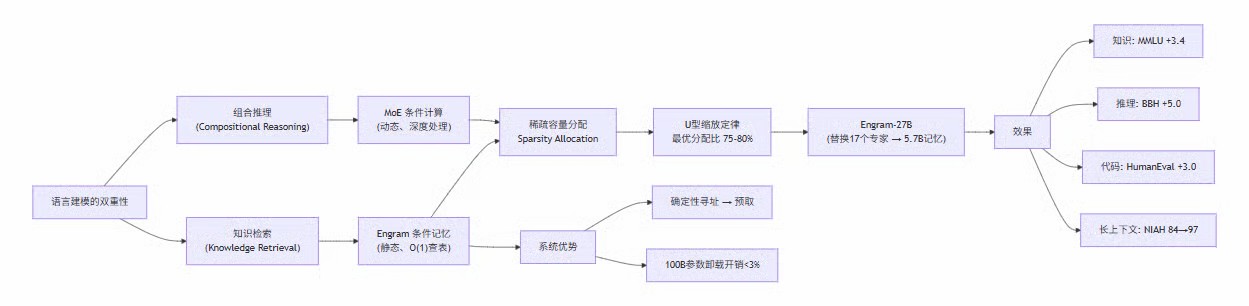
DeepSeek与北京大学提出Engram,将经典N-gram嵌入现代化为条件记忆模块,与MoE形成互补的稀疏性新维度。通过U型缩放定律指导稀疏容量分配,Engram-27B在iso-parameter/iso-FLOPs下全面超越纯MoE基线,推理增益甚至超过知识检索增益(BBH+5.0, HumanEval+3.0),并证实该模块等效于增加网络有效深度。
Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models论文阅读
写在前面
稀疏性是智能系统的核心设计原则——从生物神经回路到现代大语言模型(LLM),选择性激活一直是扩大模型容量而不等比增长计算成本的关键手段。当前这一原则主要通过MoE(Mixture-of-Experts,混合专家)实现。然而,语言建模中存在一种根本性的二元结构:组合推理(需要深度、动态的计算)和知识检索(处理本地的、静态的、高度固化的模式)。标准Transformer缺乏原生的知识查表原语,被迫用昂贵的计算来模拟检索。
DeepSeek与北京大学合作的这篇论文提出了一个全新的稀疏性维度——条件记忆(Conditional Memory),并通过Engram模块将其实现。Engram将经典的N-gram嵌入思想现代化,在MoE架构之上增加了一个可扩展的稀疏查表机制。本文的核心发现极具启发性:将一部分稀疏容量从条件计算(MoE专家)重新分配给条件记忆(Engram),不仅能提升知识密集型任务,对通用推理和代码/数学的提升甚至更大。
速读卡片
项目 | 内容 |
|---|---|
论文标题 | Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models |
作者 | Xin Cheng, Wangding Zeng, Damai Dai, Qinyu Chen, Bingxuan Wang, Zhenda Xie, Kezhao Huang, Xingkai Yu, Zhewen Hao, Yukun Li, Han Zhang, Huishuai Zhang, Dongyan Zhao, Wenfeng Liang |
机构 | 北京大学 & DeepSeek-AI |
发布时间 | 2026年1月 |
类型 | 模型架构 + 缩放定律论文 |
核心方法 | Engram:基于哈希N-gram的条件记忆模块 |
关键发现 | U型稀疏分配缩放定律,最优MoE:Engram分配比 ≈ 75-80%:20-25% |
代表模型 | Engram-27B(26.7B参数,3.8B激活)vs 纯MoE-27B |
推理增益 | BBH +5.0, ARC-Challenge +3.7, HumanEval +3.0, MATH +2.4 |
知识增益 | MMLU +3.4, CMMLU +4.0, MMLU-Pro +1.8 |
长上下文 | Multi-Query NIAH: 84.2→97.0; Variable Tracking: 77.0→89.0 |
系统效率 | 100B参数Engram卸载至主机内存,吞吐量损失<3% |
代码开源 |
一句话概括
Engram通过将经典N-gram嵌入改造为现代化的条件记忆模块(支持分词器压缩、多头哈希、上下文感知门控和多分支融合),在MoE架构中引入了一个互补的稀疏性维度,由U型缩放定律指导的最优分配策略使Engram-27B在固定参数和计算预算下全面超越纯MoE基线——且推理和代码/数学的增益甚至超过了知识检索的增益,因为Engram通过将浅层从静态知识重建中解放出来,等效地增加了模型的有效深度。
研究问题
语言建模的双重性
语言建模包含两种性质迥异的子任务:
组合推理(Compositional Reasoning):需要深度、动态的计算来处理复杂逻辑和上下文依赖。
知识检索(Knowledge Retrieval):大量文本是局部的、静态的、高度固化的——命名实体、惯用表达、公式化模式。N-gram模型的持续有效性证明了这些规律最适合用计算廉价的查表来处理。
Transformer的效率困境
标准Transformer架构缺乏原生的知识查表原语。当模型需要解析一个常见的多Token实体(如"Diana, Princess of Wales")时,必须消耗多个早期层的Attention和FFN来逐步组合特征——这个过程本质上是用昂贵的运行时计算重建一个静态查表。论文通过一个具体案例(Table 3)展示了LLM如何逐层将"Wales"从"英国的一个国家"逐步构建为"戴安娜,威尔士王妃(1961-1997)"的完整实体表征。这些珍贵的序列深度本可以分配给更高层次的推理。
稀疏容量分配问题(Sparsity Allocation)
MoE通过条件计算扩大模型容量,但所有稀疏参数都分配给了同一范式。问题在于:是否应该将一部分稀疏容量分配给一个不同类型的原语——条件记忆?如果是,最优分配比是多少?这构成了论文的核心问题。
核心贡献
提出条件记忆这一新的稀疏性维度:与条件计算(MoE)互补,通过稀疏查表来检索静态嵌入以处理固化知识。
Engram模块设计:将经典N-gram嵌入现代化,集成分词器压缩(23%词汇量缩减)、多头哈希、上下文感知门控(基于Attention的Query-Key匹配)、深度可分离因果卷积和多分支融合。
U型稀疏分配缩放定律:在固定总参数和计算预算下,验证损失与MoE/Engram分配比呈U型关系,最优分配点约为ρ≈75-80%(即20-25%的稀疏参数分配给Engram)。该最优比例在两种计算预算下保持稳定。
Engram-27B/40B大规模验证:在iso-parameter和iso-FLOPs条件下,Engram-27B全面超越纯MoE-27B——不仅在知识密集型任务上(MMLU +3.4),在通用推理(BBH +5.0)、代码(HumanEval +3.0)和数学(MATH +2.4)上的增益更大。
机制分析揭示"有效深度"效应:通过LogitLens和CKA分析证明,Engram通过将早期层从静态知识重建中解放出来,使浅层表征等效地对应到纯MoE模型的更深层——即Engram等效地增加了模型的有效深度。
长上下文的结构性优势:Engram将局部依赖的处理委托给查表操作,释放了Attention容量用于全局上下文,在Multi-Query NIAH上从84.2提升至97.0。
系统效率的硬件-算法协同设计:Engram的确定性寻址实现了运行时预取,100B参数的Embedding表卸载至主机内存仅导致<3%的吞吐量损失。
方法
Engram架构总览

图1说明:Engram模块通过检索静态N-gram记忆并与动态隐藏状态通过上下文感知门控融合来增强Transformer骨干网络。该模块仅应用于特定层(由建模和系统延迟约束共同决定),以将记忆从计算中解耦。标准输入嵌入和输出解嵌模块保持不变。
Engram的每个Token处理包含两个功能阶段:检索(Retrieval)和融合(Fusion)。
阶段一:基于哈希N-gram的稀疏检索
分词器压缩(Tokenizer Compression)
标准子词分词器(如BPE)优先无损重建,经常为语义等价的词项分配不同的ID(如"Apple"和"␣apple")。Engram通过一个词汇投影层解决此问题:
计算一个满射函数P: V→V',将原始Token ID基于规范化文本等价性(NFKC、小写化等)映射为规范ID
实践中对128k分词器实现了23%的有效词汇量缩减
将每个Token的原始ID x_t映射为规范ID x't,形成后缀N-gram g{t,n}
多头哈希(Multi-Head Hashing)
直接参数化所有可能的N-gram组合空间是不可行的。Engram采用基于哈希的方法:
对每个N-gram阶数n,使用K个不同的哈希头
每个头k通过确定性函数φ_{n,k}将压缩后的上下文映射到嵌入表E_{n,k}中的索引
哈希函数实现为轻量级的乘性XOR哈希
最终记忆向量e_t由所有检索到的嵌入拼接而成
这个设计的关键优势在于确定性寻址——与MoE的动态路由不同,Engram的检索索引仅取决于输入Token序列,可以在前向传播之前确定。
阶段二:上下文感知门控
静态检索的嵌入e_t本质上是上下文无关的先验知识,它缺乏上下文适应性,且可能因哈希碰撞或多义性而引入噪声。为此,Engram引入上下文感知门控机制:
Key-Value投影:当前隐藏状态h_t(通过前置Attention层聚合了全局上下文)作为动态Query;检索到的记忆e_t作为Key和Value的来源
门控标量计算:α_t = σ(RMSNorm(h_t)^T · RMSNorm(k_t) / √d),输出值在(0,1)之间
门控输出:ṽ_t = α_t · v_t
如果检索到的记忆e_t与当前上下文h_t矛盾,门控α_t趋向于零,有效抑制噪声。
最后,通过一个短的深度可分离因果卷积(核大小=4,膨胀率=最大N-gram阶数,SiLU激活)扩展感受野并增强非线性能力。Engram通过残差连接集成到骨干网络:H^(ℓ) ← H^(ℓ) + Y。
多分支架构集成
Engram的骨干网络采用先进的多分支架构(基于流形约束超连接Manifold-Constrained Hyper-Connections,M=4个分支)。在多分支框架下:
单一稀疏嵌入表和Value投影矩阵W_V在所有M个分支间共享
M个独立的Key投影矩阵{W_K^(m)}实现分支特定的门控行为
分支特定的门控信号:α_t^(m) = σ(RMSNorm(h_t^(m))^T · RMSNorm(W_K^(m) e_t) / √d)
该设计允许线性投影融合为单个密集FP8矩阵乘法,最大化GPU计算利用率
系统效率:计算与存储的解耦
Engram的确定性寻址自然支持参数存储与计算资源的解耦:
训练阶段:大规模嵌入表跨GPU分片存储,使用All-to-All通信原语在前向传播中收集活跃行、在反向传播中分发梯度。
推理阶段:利用确定性检索的特性实现预取-重叠策略。Engram模块放置在特定层,利用前置层的计算作为缓冲区来掩盖PCIe通信延迟。这需要硬件-算法协同设计:放置更深可以延长计算窗口以隐藏延迟,但建模性能(见消融实验)倾向于早期介入以卸载局部模式重建。

图2说明:(a)训练阶段:嵌入表跨GPU分片,通过All-to-All通信检索活跃嵌入行。(b)推理阶段:Engram表卸载至主机内存,主机利用确定性检索逻辑异步预取嵌入,将通信与前置Transformer块的计算重叠。
此外,自然语言N-gram遵循Zipf分布——少数模式占绝大多数访问。这一统计特性支持多级缓存层次:高频嵌入缓存在快速存储(GPU HBM或主机DRAM),长尾稀有模式驻留在较慢的大容量介质(如NVMe SSD)。
缩放定律与稀疏分配
U型分配定律
论文形式化了稀疏分配问题:给定固定的总参数预算P_tot和激活参数P_act,如何将非活跃参数预算P_sparse分配给MoE专家和Engram嵌入?
定义分配比ρ∈[0,1]为非活跃参数分配给MoE专家的比例:
P_MoE^(sparse) = ρ · P_sparse
P_Engram = (1-ρ) · P_sparse
ρ=1:纯MoE模型
ρ<1:减少路由专家数量,释放参数给Engram
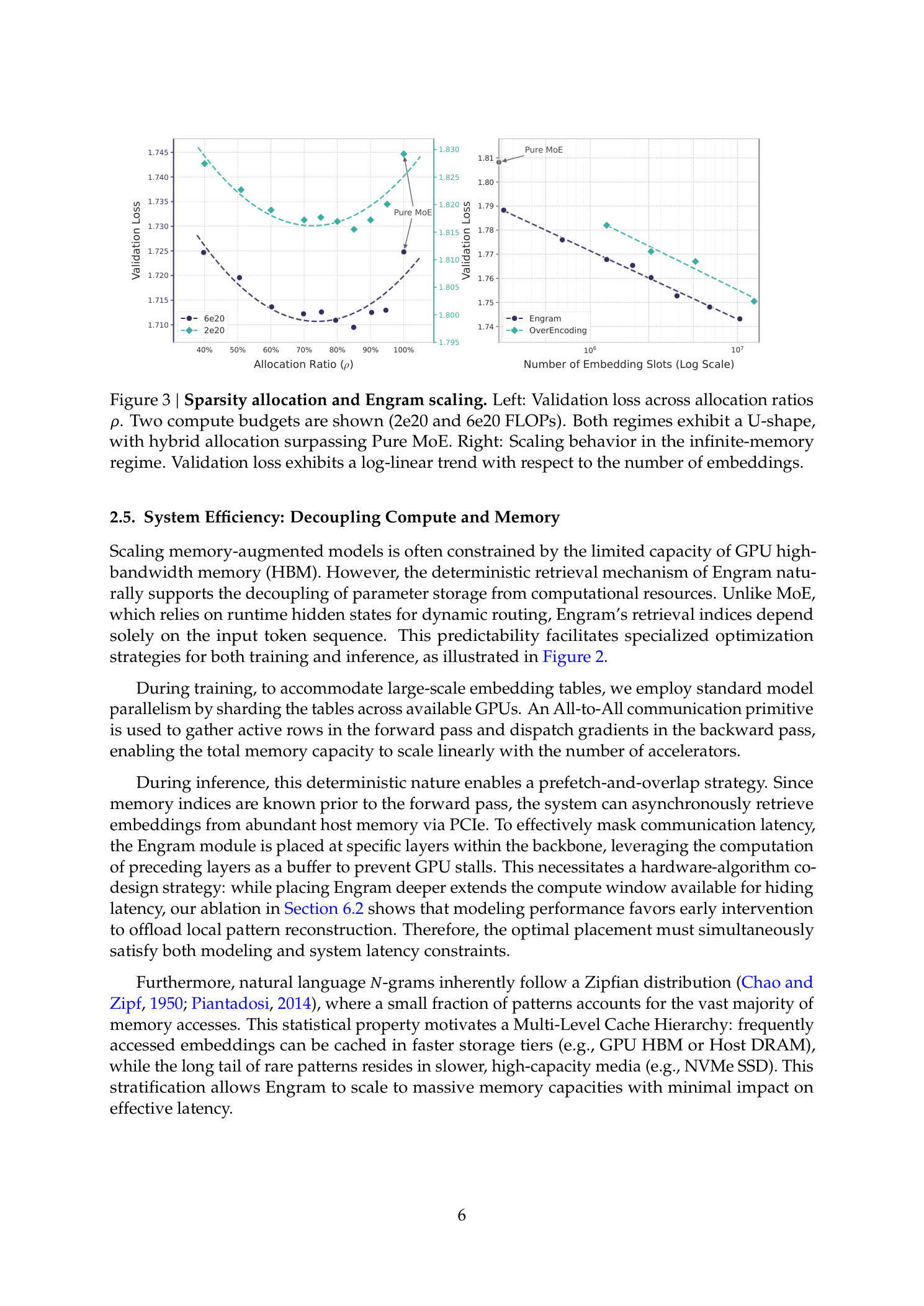
图3说明:左图为两种计算预算(2e20和6e20 FLOPs)下的验证损失与分配比的关系,两者均表现出U型曲线——纯MoE(ρ=100%)是次优的,重新分配约20-25%的稀疏参数给Engram达到最佳性能。在10B规模(C=6e20),验证损失从ρ=100%时的1.7248降至ρ≈80%时的1.7109。最优ρ≈75-80%在两种预算下保持稳定。右图为无限记忆规模下的缩放行为,验证损失随嵌入槽位数量呈对数线性趋势。
关键洞察:
MoE主导(ρ→100%):模型缺乏处理静态模式的专用记忆,被迫通过深度和计算来低效重建
Engram主导(ρ→0%):模型失去条件计算能力,损害需要动态、上下文相关推理的任务——记忆不能替代计算
无限记忆缩放
在固定3B MoE骨干网络上,将Engram表从2.58×10^5扩展到1.0×10^7个槽位(增加约13B参数),验证损失遵循严格的幂律缩放(对数空间中线性)。每次增加记忆容量都持续带来收益——无需额外计算成本。
大规模预训练实验
实验设置
配置 | Dense-4B | MoE-27B | Engram-27B | Engram-40B |
|---|---|---|---|---|
总参数 | 4.1B | 26.7B | 26.7B | 39.5B |
激活参数 | 3.8B | 3.8B | 3.8B | 3.8B |
训练Token | 262B | 262B | 262B | 262B |
路由专家 | - | 2+72(top-6) | 2+55(top-6) | 2+55(top-6) |
Engram参数 | - | - | 5.7B | 18.5B |
所有模型使用相同的训练数据课程、相同的Token预算和顺序。Engram-27B严格从MoE-27B派生:将路由专家从72减至55(ρ=74.3%),释放的参数分配给5.7B的Engram记忆模块。
主要实验结果
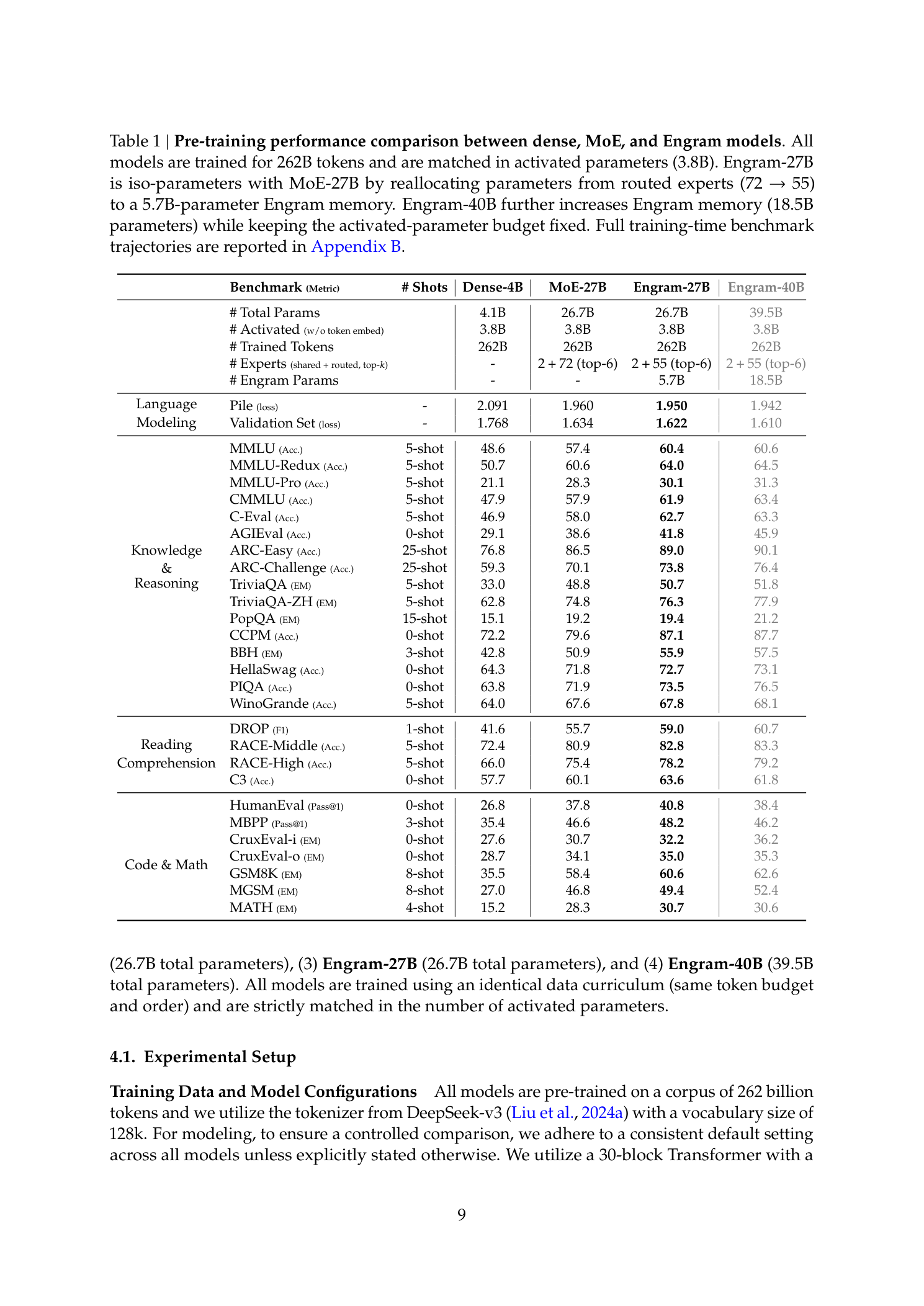
跨领域的全面超越:
知识检索:
MMLU: MoE 57.4 → Engram 60.4 (+3.0)
MMLU-Pro: 28.3 → 30.1 (+1.8)
CMMLU: 57.9 → 61.9 (+4.0)
C-Eval: 58.0 → 62.7 (+4.7)
通用推理(增益最大):
BBH: 50.9 → 55.9 (+5.0)
ARC-Challenge: 70.1 → 73.8 (+3.7)
DROP: 55.7 → 59.0 (+3.3)
代码与数学:
HumanEval: 37.8 → 40.8 (+3.0)
MATH: 28.3 → 30.7 (+2.4)
GSM8K: 58.4 → 60.6 (+2.2)
Engram-40B进一步扩展至18.5B参数后,在大部分基准上继续提升。基于训练损失缺口仍在扩大的趋势,论文认为在当前Token预算下扩大后的记忆容量尚未完全饱和。
长上下文
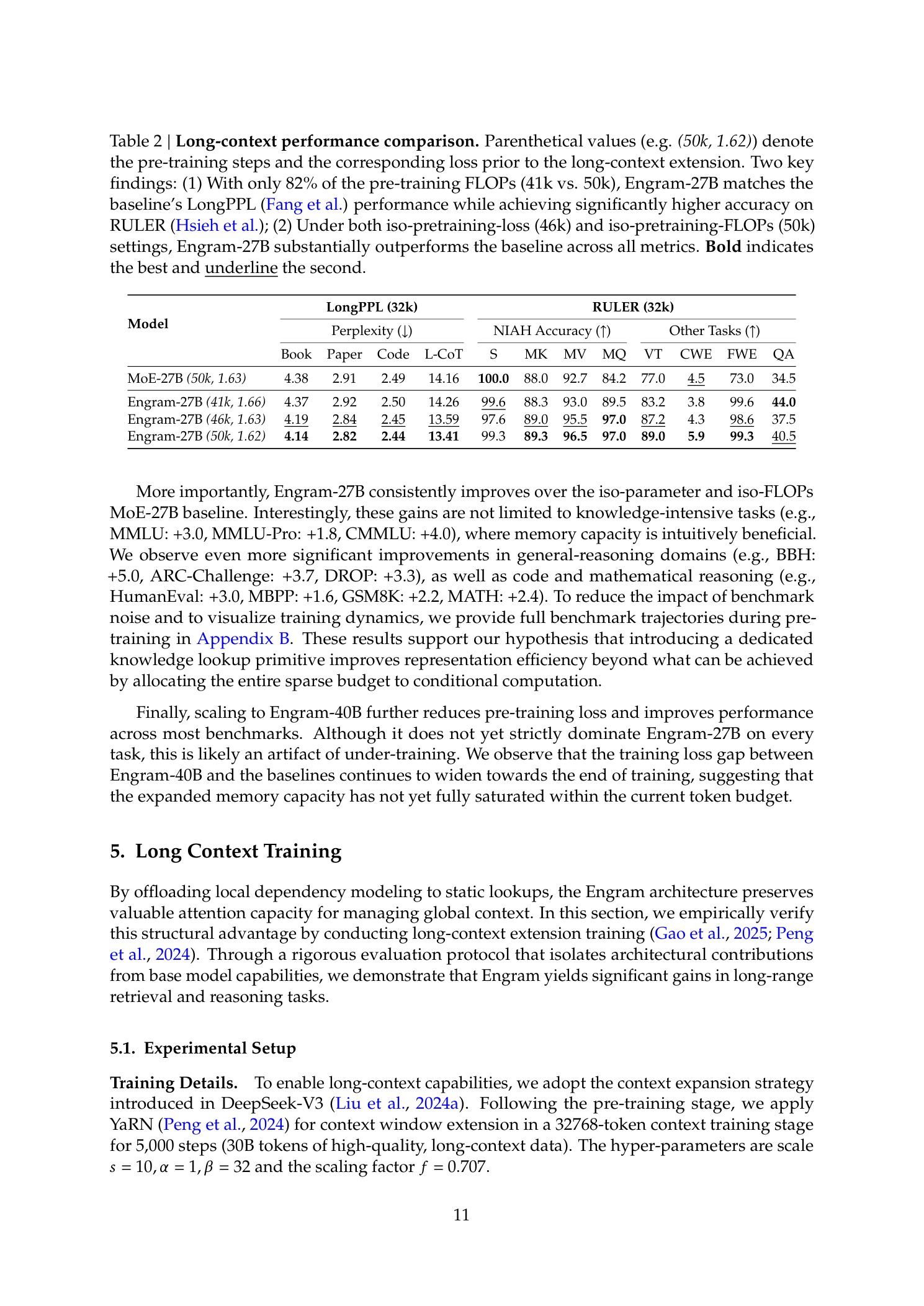
长上下文扩展实验揭示了Engram的结构性优势:
Iso-Loss设置(46k步Engram vs 50k步MoE基线,预训练损失对齐):
指标 | MoE-27B(50k) | Engram-27B(46k) |
|---|---|---|
Multi-Query NIAH | 84.2 | 97.0 |
Multi-hop VT | 77.0 | 87.2 |
Iso-FLOPs设置(50k步Engram-27B):在所有RULER指标上建立了最高性能。
极低计算设置(Engram 41k步,约82% FLOPs):在以82%计算量匹配基线LongPPL的同时,在RULER上超越基线。
论文通过两阶段策略精确归因Engram的结构贡献:首先解耦基础模型能力与架构设计的影响,然后进行受控比较。结果表明Engram通过将局部依赖委托给查表操作,释放了Attention容量用于全局上下文管理。
机制分析
Engram是否等效于增加模型有效深度?
论文使用两种机制可解释性工具验证一个核心假说:Engram通过绕过早期特征组合过程,等效地增加了模型的有效深度。
LogitLens分析:
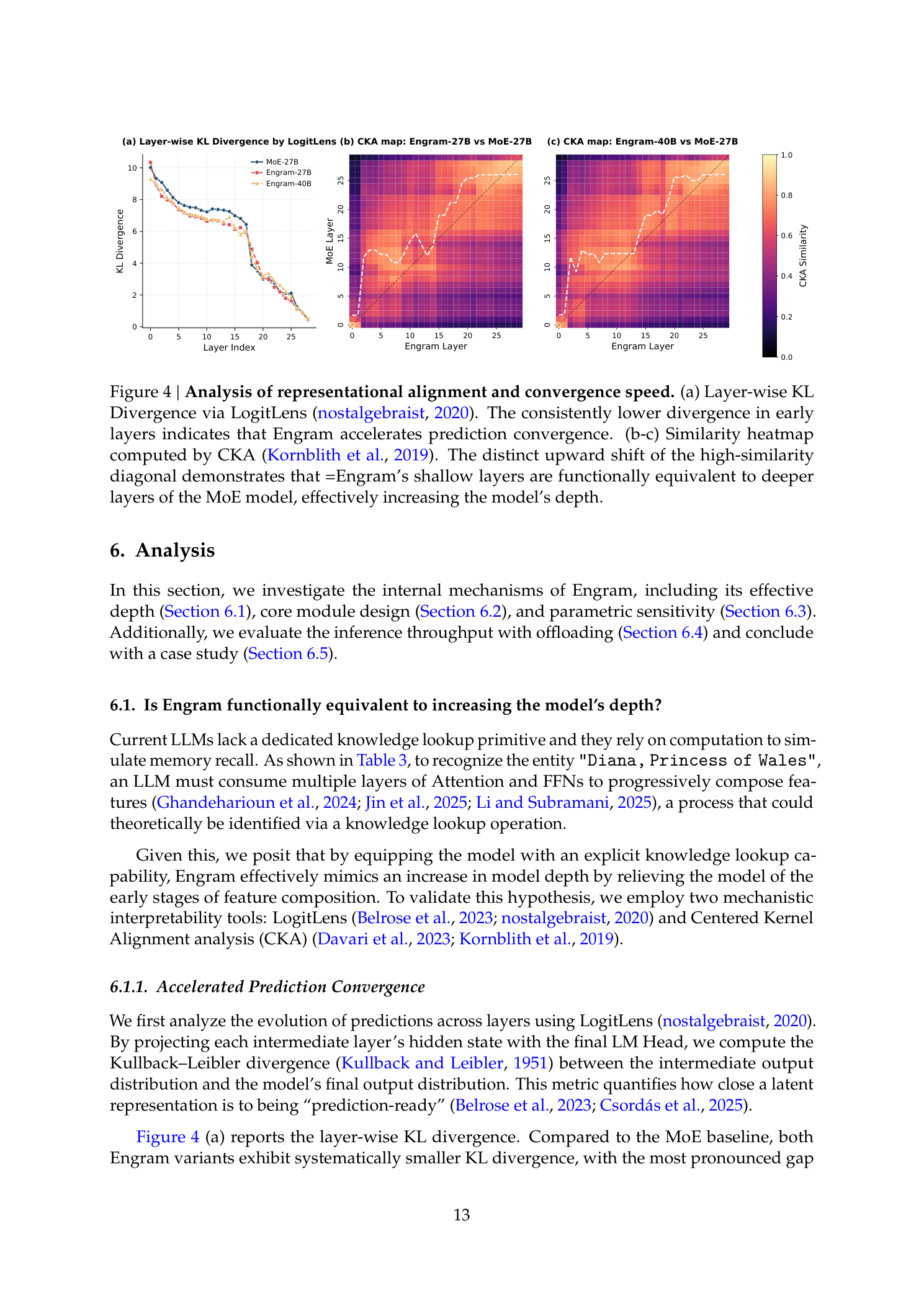
图4说明:(a)通过LogitLens计算的逐层KL散度——Engram变体在早期层中系统性地表现出更低的散度,更陡峭的下降曲线表明模型更快地完成了特征组合。(b-c)CKA相似度热力图——高相似度对角线的明显向上偏移表明Engram的浅层表征在功能上等效于MoE模型的更深层。
通过将每个中间层隐藏状态用最终的LM Head投影,计算中间输出分布与最终输出分布之间的KL散度(量化"预测就绪"程度):
两个Engram变体系统性地表现出更小的KL散度
最显著的差距出现在早期块
通过显式访问外部知识,Engram减少了所需的计算步数
CKA表征对齐分析:
引入软对齐指数a_j(定义为与Engram层j最相似的top-5个MoE层的加权质心)。观察到一个明显的对角线上偏移:
Engram-27B在第5层形成的表征与MoE基线约第12层的表征最接近
这个偏移量在整个层范围内保持一致
将LogitLens和CKA结果合并,结论是:Engram通过显式查表绕过早期阶段的特征组合,在功能上等效于增加模型的有效深度。

Table 3说明:LLM如何逐层消耗Attention和FFN来构建"Diana, Princess of Wales"的内部表征——这个过程可以被Engram的显式查表操作所取代。
结构消融与层敏感性
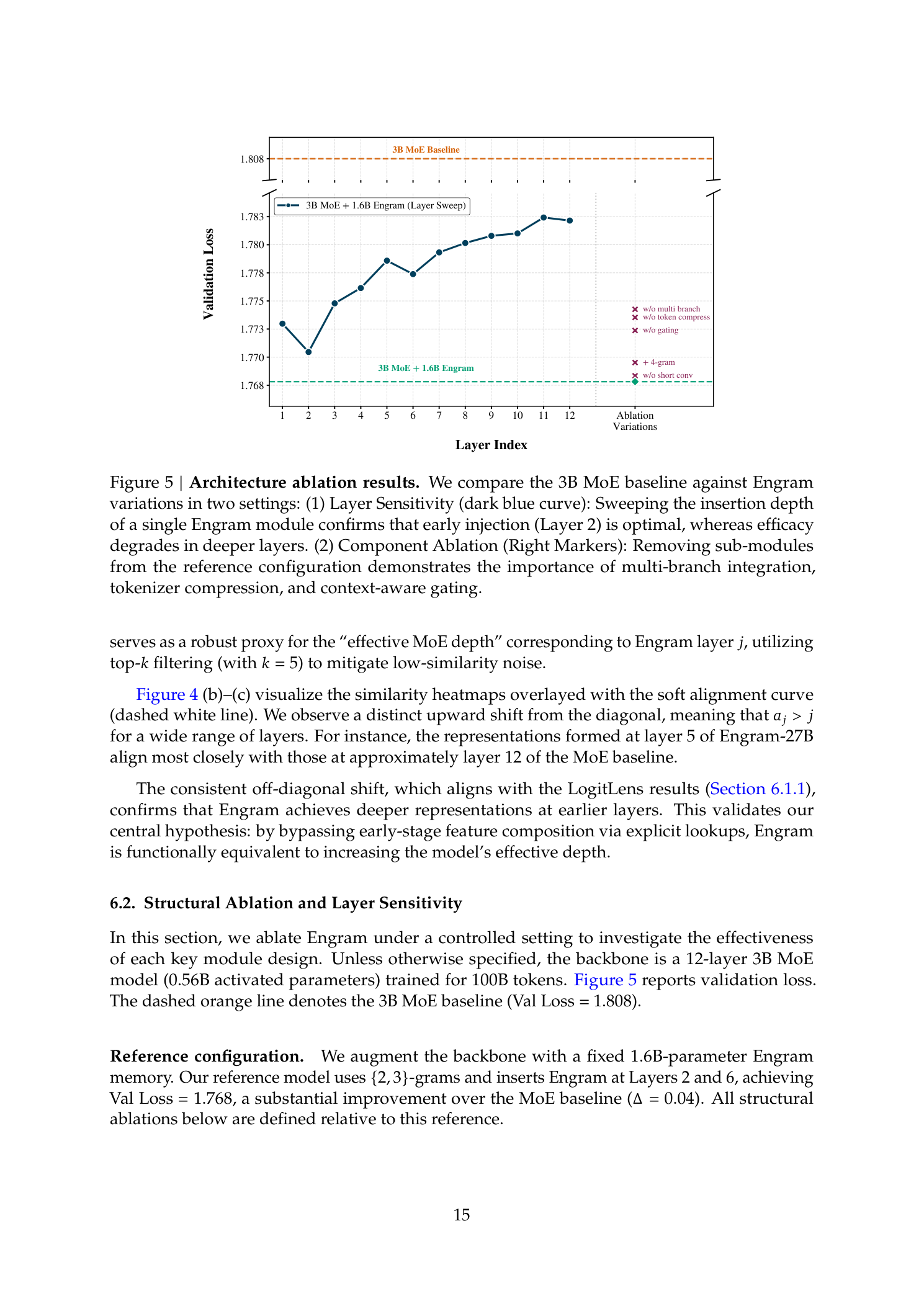
图5说明:左图为层敏感性扫描——在固定1.6B Engram预算下将单个Engram模块的插入深度从第1层扫到第12层,Layer 2达到最佳性能(早期介入以卸载局部模式重建,同时已有足够的全局上下文用于精确门控)。右图为组件消融——多分支集成、分词器压缩和上下文感知门控是最关键的三个组件。
层放置的权衡:
早期注入优势:在骨干网络消耗计算深度之前卸载局部模式重建
延迟注入优势:更强的上下文Query带来更精确的门控(后期隐藏状态已聚合更丰富的全局上下文)
分层设计(Layer 2 + Layer 6)调和了这种权衡——结合了早期干预和丰富的后期上下文门控
关键组件消融(按重要性排序):
多分支特定融合(w/o multi branch:损失大幅回升)
上下文感知门控(w/o gating:损失明显回升)
分词器压缩(w/o token compress:损失回升)
深度可分离卷积(w/o short conv:影响较小)
4-gram扩展(在固定1.6B预算下略微次优,因为稀释了更频繁的2/3-gram模式的容量)
Engram功能二义性

图6说明:在推理时完全抑制Engram模块输出(同时保持骨干网络不变),不同能力维度的性能保留率揭示了尖锐的功能二义性——事实知识类基准崩溃至原始性能的29-44%,而阅读理解任务保留81-93%。
论文通过在推理时抑制稀疏嵌入输出进行后验消融分析。实验结果揭示了一个尖锐的功能二义性:
事实知识(Factual Knowledge)领域遭受灾难性崩溃:TriviaQA仅保留29%,PopQA仅保留36%,MMLU-Pro仅保留44%
阅读理解(Reading Comprehension)任务几乎未受影响:C3保留93%,RACE-Middle保留89%,RACE-High保留84%
这一明确的分化确认了:Engram模块是参数化知识的主要存储库,而上下文相关推理仍然依赖于骨干网络的Attention机制。
门控机制可视化

图7说明:Engram-27B的门控标量α_t热力图——在完成局部静态模式时(如"Alexander the Great"、"the Milky Way"、"Princess of Wales"以及中文的"四大发明"和"张仲景"),门控一致地激活。这验证了Engram按预期识别和处理固化的语言依赖。
推理效率

在NVIDIA H800上,将100B参数的Engram表完全卸载至主机内存的吞吐量比较:
骨干模型 | 配置 | 吞吐量 (tok/s) | 损失 |
|---|---|---|---|
4B-Dense | 基线 | 9,031.62 | - |
4B-Dense | +100B Engram(CPU卸载) | 8,858.28 | 1.9% |
8B-Dense | 基线 | 6,315.52 | - |
8B-Dense | +100B Engram(CPU卸载) | 6,140.02 | 2.8% |
前置密集块的计算强度提供了足够的时间窗口来掩盖检索延迟。这还是一个保守基线——在实际层级设计中,Zipf局部性会进一步降低有效检索延迟。
局限性
最优分配比的尺度依赖性:论文仅在两个计算预算(2e20和6e20 FLOPs)下探索了U型曲线,在更大尺度(如千亿参数级别)下最优ρ值可能变化。
Engram-40B的欠训练:Engram-40B的训练损失缺口仍在扩大,表明18.5B的记忆容量在当前Token预算下尚未完全饱和,更大规模的缩放特性有待验证。
N-gram阶数的限制:论文主要使用{2,3}-gram组合。4-gram在固定小预算下稀释了高频模式的容量,但在更大记忆规模下高阶N-gram可能带来增益——这一点未被充分探索。
仅文本模态:Engram的设计和评估完全在文本领域。视觉或多模态领域中的条件记忆潜力未被研究。
注意力机制的竞争性替代:虽然论文在长上下文实验中展示了Engram的结构优势,但与更高效的注意力变体(如线性注意力、状态空间模型)的系统性比较尚未进行。
预取策略的部署复杂度:100B参数卸载实验是基于简化的两骨干块设置进行的。在更复杂的生产环境中,多Engram层之间的通信调度优化仍有大量工作。
未来工作
论文暗示的前进方向:
在更大尺度(>100B参数)验证U型分配定律的普适性
将条件记忆扩展到多模态场景(视觉记忆、音频记忆等)
探索更高阶N-gram在更大记忆容量下的收益
完善层级缓存架构以进一步降低推理延迟
将Engram与其他高效的注意力替代方案结合
笔者的补充判断:
条件记忆的概念可以自然地扩展到更结构化的知识形式,如知识图谱三元组或代码API签名
Engram的确定性寻址特性使其天然适合联邦学习或隐私保护场景——记忆表可以在不暴露原始数据的情况下共享
启发
工程实践层面
"宁做查表,不做计算"是新的效率原则:Engram的核心哲学是用O(1)查表替代O(d^2)的计算来编码固化知识。这提醒架构设计者:当大量文本模式实际上是静态且高频重复的时候,将计算资源分配给他们是低效的。对于任何需要处理大量结构化或半结构化文本的系统,显式的记忆查表模块是一种值得考虑的架构选择。
U型分配曲线的工程意义:论文发现的U型曲线给出了明确的优化方向——在给定的稀疏参数预算下,分配约20-25%给条件记忆是最优的。这一比例可以作为构建新MoE架构时的初始参考。
确定性寻址的部署优势被低估:MoE的动态路由在推理时需要全局All-to-All通信,而Engram的确定性寻址允许预取和卸载。对于需要在资源受限环境中部署大模型的团队,这一特性有直接的工程价值。
研究设计层面
语言建模的双重性提供了一个新的研究视角:将语言建模任务分解为"推理"和"检索"两个维度,并分别为每个维度设计专门的架构原语——这一思路可以推广到更多任务领域。任何同时要求推理能力和知识存储的AI任务,都可以从"专用计算+专用记忆"的架构设计范式中受益。
有效深度是一个被低估的模型性能指标:论文通过CKA和LogitLens证明了Engram的增益本质上是"等效地增加了模型有效深度"。这一发现提示:未来的架构创新不应仅关注参数效率,还应关注"每个参数能为有效计算层贡献多少"。
N-gram的现代复兴具有启示意义:一个被普遍认为已经过时的技术(N-gram嵌入),经过合适的现代化改造(多头哈希、上下文门控、多分支集成),可以成为与MoE互补的强大建模原语。这提醒研究者不要轻易忽视经典思想的潜力。
小结
Conditional Memory via Scalable Lookup通过Engram模块将条件记忆确立为与条件计算(MoE)互补的稀疏性新维度。论文的核心洞察——"语言建模中相当大比例的知识检索可以用O(1)查表替代昂贵的深度计算"——既有理论基础(N-gram的效率在数十年间已被反复验证),也有实证支持(Engram-27B在iso-parameter/iso-FLOPs下全面超越纯MoE基线)。
最具启发性的发现可能是推理增益(BBH +5.0, ARC-Challenge +3.7)超过了知识检索增益(MMLU +3.4, CMMLU +4.0)——因为将静态知识重建从早期层中卸载,使模型可以将宝贵的序列深度重新分配给更高层次的推理。Engram的价值不仅在它存储了什么,更在于它让Transformer骨干网络不需要做什么。
对于从事大模型架构设计的任何研究者或工程师,这项工作中的U型分配定律、确定性寻址的系统效率优势,以及"显式记忆+动态计算"的二元架构范式,都是值得深入理解和借鉴的。