
AI赋能的智能测试与质量保障实践
摘要
本文整理 AI 编程场景下的软件测试与质量保障方法,重点讨论 SDD、TDD、Harness Engineering 和 Agent 编排之间的关系,并以 Mini Ralph 为例说明如何用 Python 和 Qwen 搭建一个具备规划、构建、测试、审查和终止能力的简化编排循环。
AI赋能的智能测试与质量保障实践
写在前面
AI 编程提高了代码生成速度,也放大了质量风险。以前的问题是人写得慢,现在的问题是 AI 写得太快。如果没有规格、测试和门禁,错误代码会以很高的速度进入项目。
所以 AI 时代的软件质量保障不能只依赖人工审查。更合理的方式是把需求写成规格,把规格转成测试,把测试放进自动化门禁,再让 Agent 在这些约束中工作。这里的核心不是让 AI 更自由,而是让 AI 在可验证的范围内发挥效率。
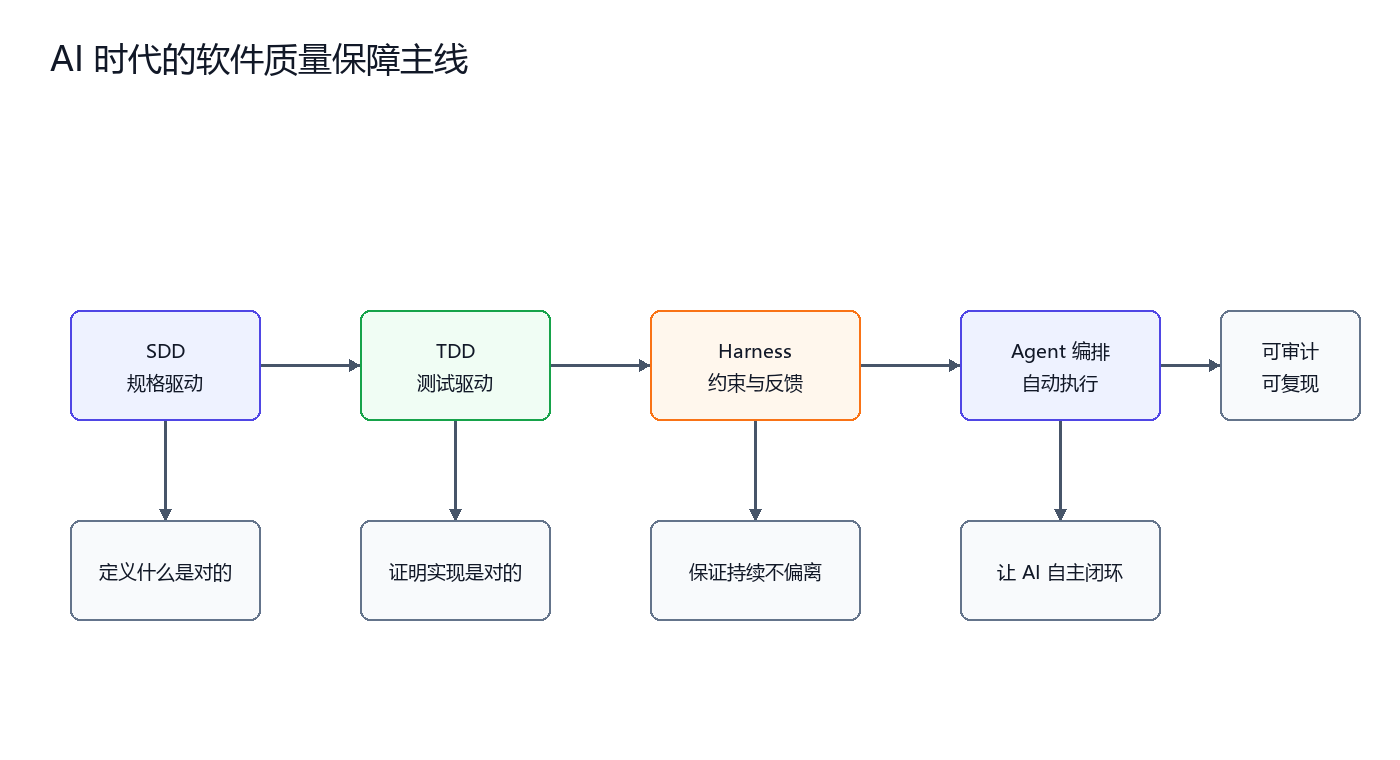
一句话概括
SDD 定义什么是对的,TDD 证明实现是对的,Harness Engineering 保证过程不偏离,Agent 编排让模型在这些约束中自动完成任务。
1. 从 SDD 到 TDD:先定义正确性,再生成代码
SDD 是 Specification-Driven Development,即规格驱动开发。它要求先写清楚系统应该满足什么约束,再让代码成为规格的可执行表达。
在 AI 编程中,Spec 不只是给人看的需求文档,也是给 Agent 看的上下文。需求如果只停留在脑子里,AI 无法读取;需求如果写进仓库,AI 才能基于它生成测试、实现和修复方案。
以股票深度研究工具为例,目标是输入股票代码,采集基本面、市场面、消息面和分析师观点,再生成结构化研报。这个任务如果直接让 AI 写代码,模型很容易生成一个看似完整、实际不可验证的报告函数。更稳妥的做法是先写规格。
这些约束可以直接变成测试。测试不是事后补充,而是规格的一部分。
这个测试对应 C4。它先把不合法评级写进报告,再断言 validate_report() 必须报错。只有测试先存在,后续实现才有清晰目标。
2. AI 投研工具:把规格变成测试对象
股票深度研究工具的结构可以分为四层:API 客户端、数据采集、分析汇总、报告生成。每层都有明确职责,也对应不同测试方式。
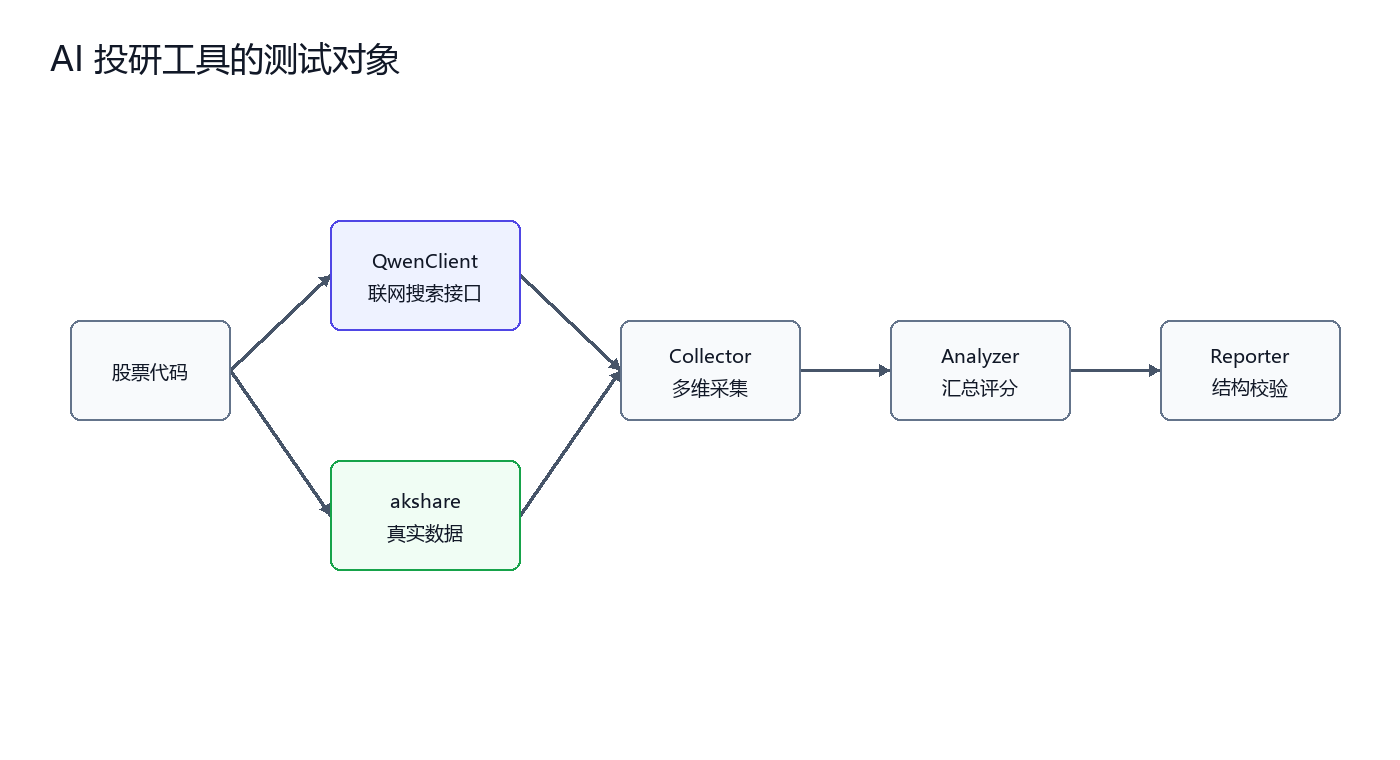
Collector 的目标是把真实数据和模型分析组织起来。它不直接生成最终报告,而是负责按维度采集数据,并把结果交给后续模块。
这里的测试重点不是判断模型分析内容是否“聪明”,而是检查编排逻辑是否稳定。例如是否默认采集四个维度,是否能处理部分维度失败,是否把真实数据放进提示词。
这个测试用 Mock 隔离了真实 API。它验证的是 Collector 自身的流程,不依赖 Qwen 是否可用,也不依赖外部数据源是否稳定。
Reporter 则负责最终结构校验。这里最重要的函数是 validate_report(),它把规格约束转成可执行规则。
这里的 fix 字段很重要。普通错误只告诉人哪里错了;Harness 式错误会告诉 Agent 如何修复。这样错误信息本身就成为反馈回路的一部分。
3. Harness Engineering:用约束控制 AI
Harness 可以理解为模型之外的一整套工程控制系统,包括规则、上下文、工具、测试、Lint、CI 和反馈回路。它不替代模型,而是限制模型的行为边界。
比较实用的划分是三类能力。
能力 | 作用 | 项目中的形式 |
|---|---|---|
告知 | 告诉 Agent 项目是什么、文件在哪里、规则是什么 |
|
约束 | 明确不能违反什么结构和规则 | Lint、类型检查、架构边界 |
验证 | 自动判断结果是否正确 | pytest、集成测试、CI |
AGENTS.md 不适合写成长篇手册。它更像地图,只告诉 Agent 关键入口和约束位置。细节应该放在 Spec、测试和 Lint 中,因为这些文件可以被执行或验证。
结构 Linter 则把这些约束机械化。例如检查 reporter.py 中是否存在 validate_report(),检查 REQUIRED_DIMENSIONS 是否包含全部维度,检查 src/ 下每个模块是否有对应测试。
这个检查很简单,但对 AI 编程很有效。因为它把“应该写测试”从建议变成了不可跳过的规则。
4. 三道质量门禁
质量门禁应按成本从低到高排列。越便宜、越确定的检查越应该提前运行。
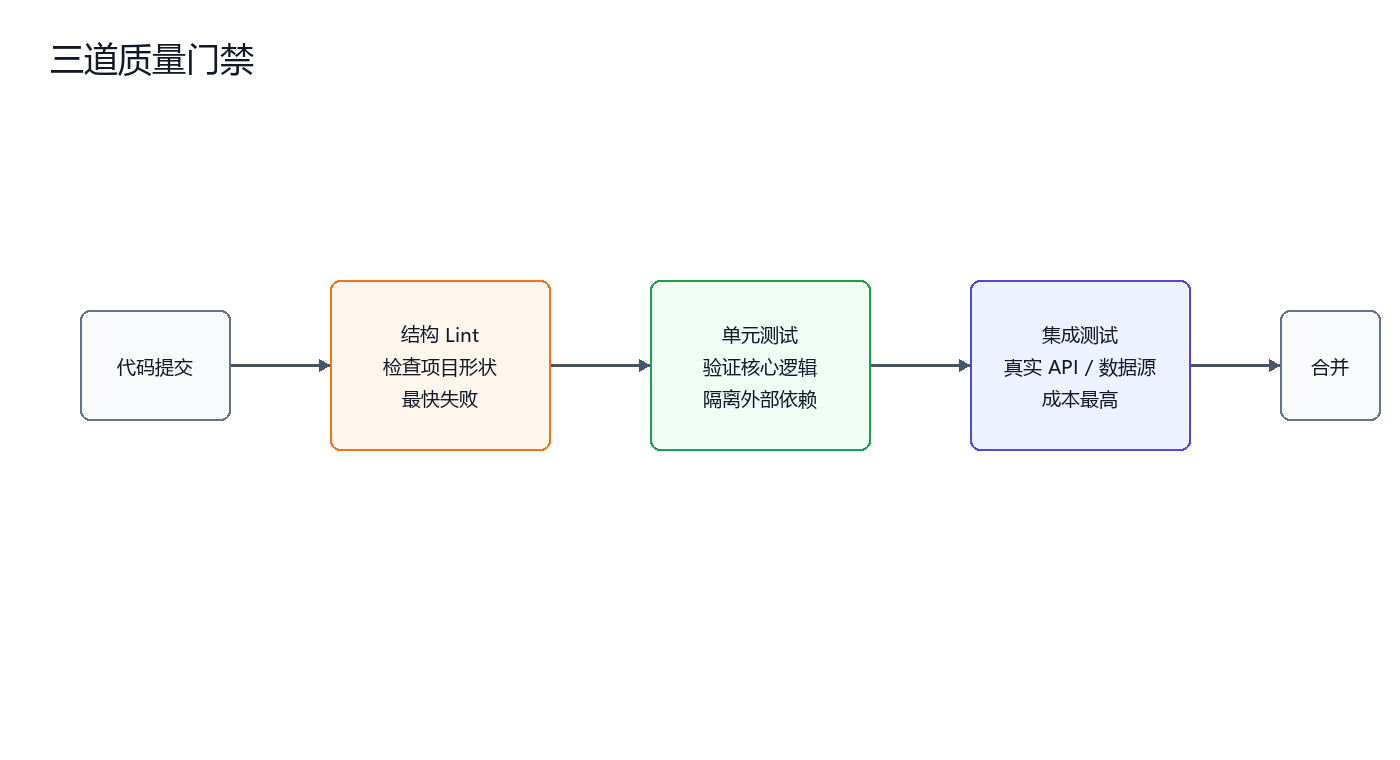
第一道门是结构 Lint,用来检查项目形状是否正确。它运行快,失败信息明确,适合作为最前置门禁。
第二道门是单元测试,用来验证核心逻辑。单元测试应隔离外部 API,不依赖真实网络和密钥。
第三道门是集成测试,用来验证真实 API、真实数据源和真实环境。它成本最高,也最不稳定,因此应该放在最后。
这种门禁设计对 Agent 很重要。Agent 可以生成代码,但不能自己宣布代码合格。合格与否必须由外部验证系统决定。
5. Mini Ralph:用 Qwen 搭建一个简化编排循环
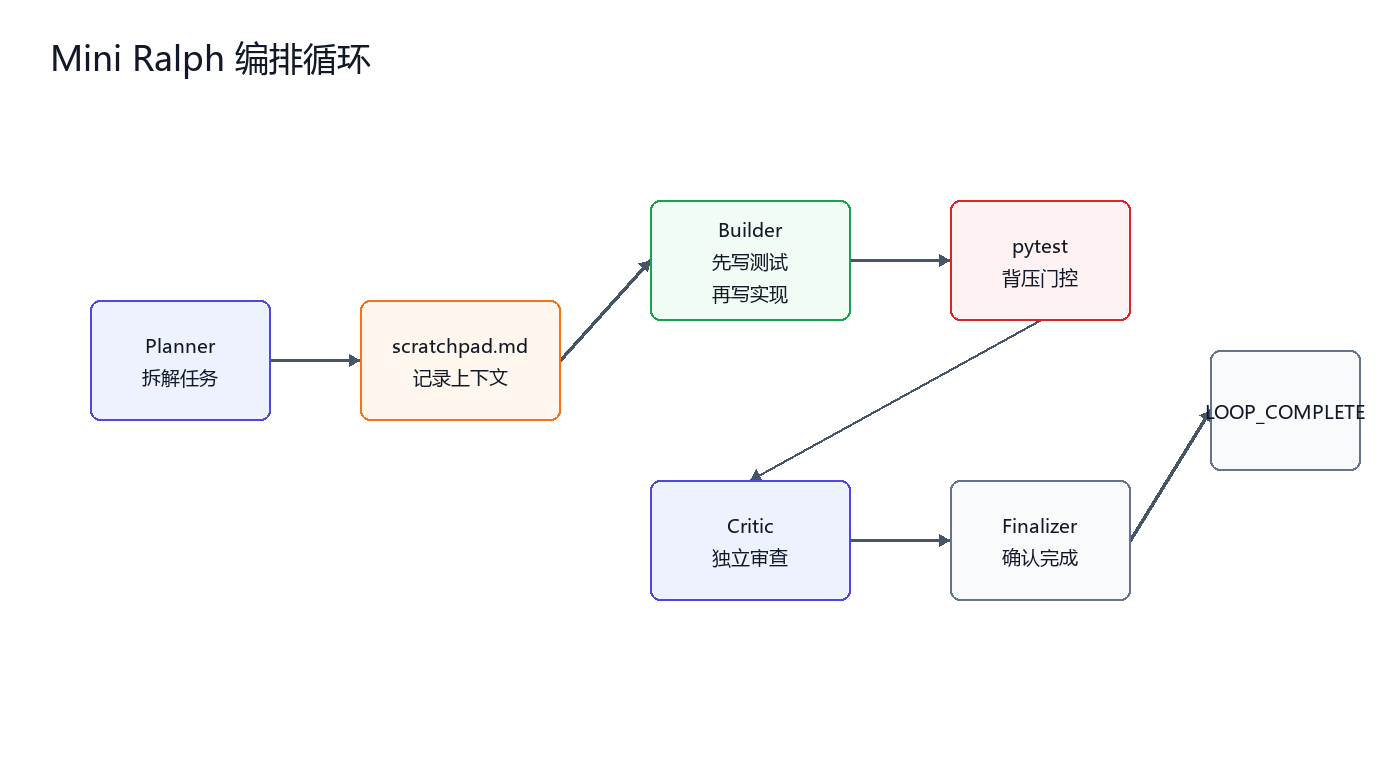
Mini Ralph 的目标是模拟一个轻量级 Agent 编排器。它不追求复杂能力,只验证一件事:能否让模型在固定角色和测试门控中完成一个小任务。
这里的示例任务是构建一个计算器模块。人类只提供 PROMPT.md,之后由 Qwen 依次完成规划、构建、测试、审查和终止。
5.1 项目结构
复现时可以保持最小目录结构。
PROMPT.md 是人类唯一输入。它不写实现细节,只写任务目标和完成条件。
5.2 环境准备
依赖非常少,核心是 OpenAI SDK 和 pytest。Qwen 通过 DashScope 的 OpenAI 兼容接口调用。
脚本中只需要配置模型、输出目录、上下文记录文件和最大迭代次数。
5.3 四顶帽子
Mini Ralph 用四段 system prompt 模拟四个角色。角色拆分的意义是减少模型在同一轮中同时规划、写代码和审查带来的混乱。
角色 | 职责 | 关键约束 |
|---|---|---|
Planner | 读取任务并拆解步骤 | 只输出计划,不写代码 |
Builder | 根据计划生成测试和实现 | 必须先写测试,再写实现 |
Critic | 独立审查代码和测试结果 | 最后一行输出判定 |
Finalizer | 判断任务是否完成 | 通过后输出 |
Builder 的提示词是最关键的部分。它必须输出可被脚本解析的文件格式,否则后续无法写入磁盘。
这里体现了 Harness 的一个基本原则:不要只告诉模型“请规范输出”,而要给它一个机器可解析的协议。
5.4 调用模型
Qwen 调用通过 OpenAI 兼容接口完成。温度设置得较低,减少输出格式漂移。
5.5 scratchpad:仓库即记录系统
Mini Ralph 不依赖模型记忆,而是把每轮结果追加到 scratchpad.md。这样做有两个好处:第一,后续角色能读取前序结果;第二,整个过程可以事后审计。
这里的思路很实用。不要把关键上下文只放在聊天窗口里。对 Agent 来说,不在仓库里的信息就是不可持续的信息。
5.6 提取文件
Builder 返回的是文本。脚本需要从文本中提取文件名和文件内容,再写入 ralph_output/。
这个函数处理的是 AI 输出的不确定性。即使提示词要求不要输出 markdown 代码块,模型仍可能输出,所以这里做了最小格式清理。
5.7 测试门控
测试门控是 Mini Ralph 的核心。Builder 生成代码后,脚本立即运行 pytest。测试不过,不进入下一阶段,而是把错误输出反馈给 Builder 修复。
这就是背压门控。模型可以生成代码,但测试结果决定流程是否继续。
5.8 主循环
主循环只有四个阶段。每个阶段只做一件事。
这个循环并不复杂,但它包含了 Agent 工程中最关键的四个要素:角色隔离、上下文记录、测试反馈和终止条件。
5.9 运行结果
示例中 Builder 先生成了 test_calc.py。
随后生成 calc.py。
本地运行 Mini Ralph 输出目录中的测试,结果为 4 个测试全部通过。
这个例子虽然小,但已经体现了完整闭环:人类给规格,Planner 拆任务,Builder 先写测试再写实现,pytest 执行验证,Critic 独立审查,Finalizer 确认完成。
6. 这个例子的工程启发
Mini Ralph 的价值不在于计算器本身,而在于它把 Agent 工作过程拆成了可控制的几个节点。
第一,提示词不是越长越好,关键是角色边界明确。Planner 不写代码,Builder 不做最终判断,Critic 不参与实现。
第二,测试不是辅助材料,而是控制流的一部分。测试失败会改变执行路径,迫使 Builder 修复。
第三,上下文应该文件化。scratchpad.md 保存了每轮决策,便于审计,也便于后续角色读取。
第四,错误信息要能指导修复。validate_report() 和结构 Linter 中的 FIX 字段,本质上是在为 Agent 准备可执行反馈。
7. 实际使用建议
如果是从零开发一个 AI 辅助项目,可以按下面顺序做。
阶段 | 产物 | 目的 |
|---|---|---|
规格 |
| 定义功能、输入输出和约束 |
测试 |
| 把约束转成可执行验证 |
实现 |
| 只写满足测试的最小实现 |
Lint |
| 固化结构规则和架构边界 |
CI |
| 阻止不合格代码进入主分支 |
Agent 编排 |
| 让 AI 在约束内自动完成任务 |
对 AI 编程来说,最危险的不是模型不会写代码,而是模型写出了一段看起来正确、但没有任何外部验证的代码。规格、测试、Lint 和 CI 的作用,就是把“看起来正确”变成“可以被证明正确”。
小结
AI 赋能测试与质量保障,本质上是把软件工程中的正确性约束前置并自动化。SDD 让需求可见,TDD 让正确性可验证,Harness 让约束不可跳过,Agent 编排让模型在闭环中工作。
Mini Ralph 是一个简化模型,但它展示了一个重要方向:未来的 AI 开发不是人把所有代码手写出来,而是人设计规格、测试和门禁,让 AI 在可审计的工程系统中生成、修复和验证代码。