
企业知识库 RAG 系统实践
摘要
本文整理一次企业知识库 RAG 系统实践:先解释 RAG-Challenge-2 冠军方案的整体原理,再拆解文档解析、切块、路由、父页召回、LLM 重排、Prompt 约束和评估方法,最后对比原始方案、企业落地改造版本和个人论文知识库版本。
企业知识库 RAG 系统实践
写在前面
企业知识库问答不是简单的把 PDF 放进向量库。真正的问题在于,文档长、结构复杂、表格多、问题类型多,并且用户希望答案可追溯、可解释、可复查。只做 native RAG,系统通常能回答一些简单问题,但遇到长文档、多文档对比、表格事实和专业概念解释时,很容易检索错、上下文缺失或生成不稳定。
本文按三个层次展开。
第一层是原始方案。以 RAG-Challenge-2 企业知识库冠军方案为例,解释为什么要在 native RAG 基础上加入两个 router、父页召回和 LLM reranking。
第二层是企业落地改造。比赛方案追求评测集高分,实际真实知识库更关注可部署、可调试、可迁移、低成本和稳定运行,因此需要替换解析器、模型 API、索引结构、Prompt 体系和评估方式。
第三层是我自己的论文知识库版本。这个版本把企业知识库框架迁移到博士论文方向,构建 wireless_sensing 和 passive_radar 两个主题知识库,用本地 Gradio 界面观察路由、检索、重排、引用和耗时。
全文主线如下。
层次 | 核心问题 | 解决思路 |
|---|---|---|
原始 RAG 方案 | 长 PDF 和多问题类型导致 native RAG 不稳定 | 多向量库、数据库路由、Prompt 路由、父页召回、LLM 重排 |
企业落地改造 | 比赛方案不能直接用于真实企业环境 | 替换国内 API、优化解析流程、保留表格信息、增加调试与评估 |
个人论文知识库 | 面向研究方向的论文问答和文献复用 | 主题知识库、MinerU 解析、Qwen embedding、Qwen rerank、可观察界面 |
一、原始 RAG 原理图
RAG-Challenge-2 的冠军方案可以看成 native RAG 的工程增强版。它不是只做一次向量检索,而是把整个流程拆成文档入库和问题回答两条链路。
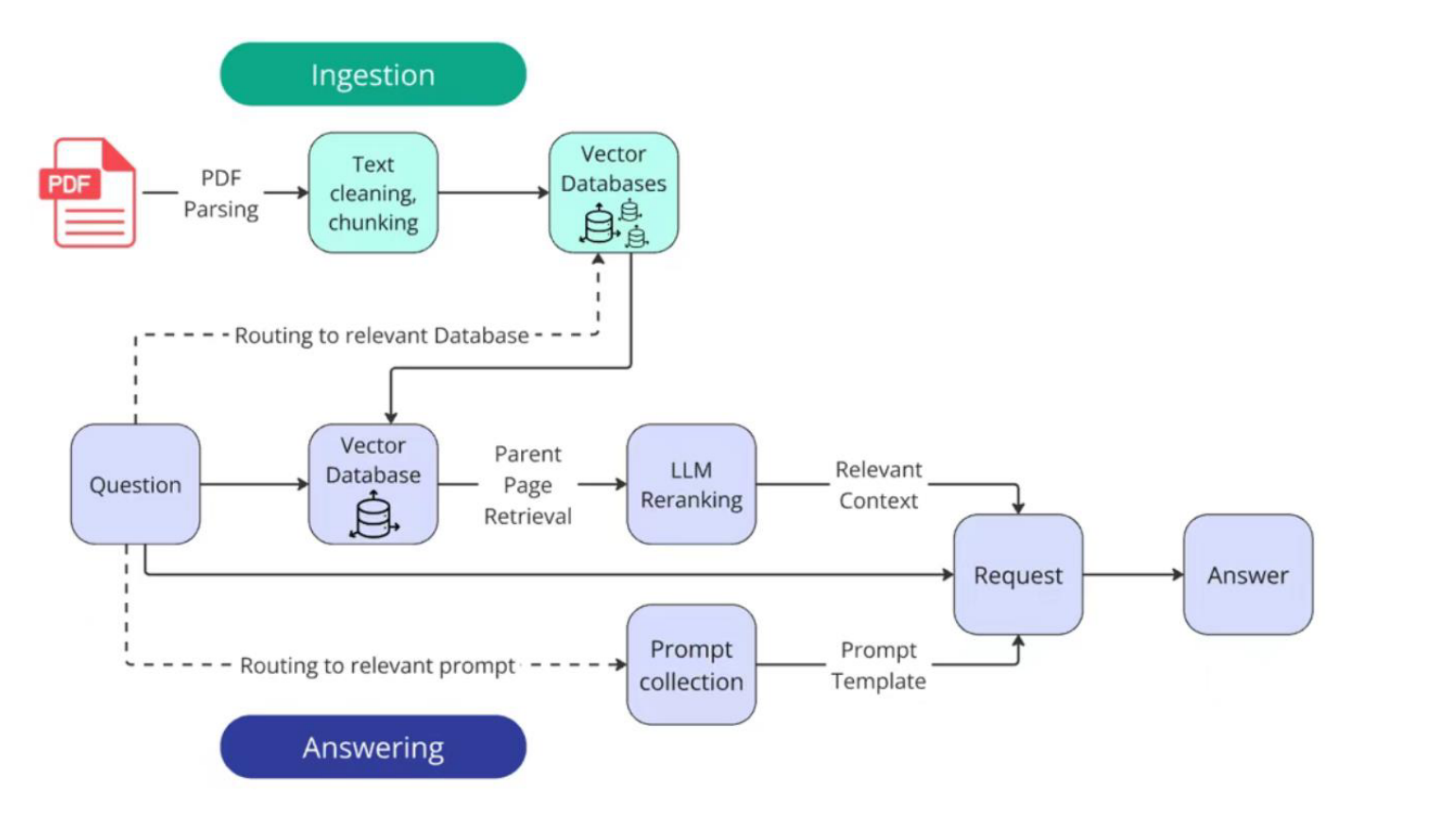
这张图需要按上下两部分理解。
上半部分是离线入库。PDF 先经过解析,得到文本、表格和页面结构;然后进行清洗和切块;最后写入多个 vector databases。这里的重点不是有一个向量库,而是有多个向量库。在企业年报问答中,一个公司或一个文档集合可以对应一个独立知识库。这样做的好处是,问题来了以后不必在所有文档里盲目检索。
下半部分是 answering,也就是在线回答。用户提出问题后,系统不是直接检索,而是先做两类路由:第一类路由到相关数据库,第二类路由到相关 Prompt。数据库路由决定去哪里找证据,Prompt 路由决定用什么格式回答。随后系统执行向量检索、父页召回、LLM reranking,把最相关的上下文和对应 Prompt 一起送入最终请求,生成答案。
这套流程比 native RAG 多了三个关键结构。
结构 | 输入 | 输出 | 解决的问题 |
|---|---|---|---|
数据库路由 | 用户问题 | 相关向量库 | 缩小检索空间,避免在全部文档中混检 |
Prompt 路由 | 用户问题 | 回答模板 | 约束不同问题类型的输出格式 |
LLM reranking | 初始召回候选 | 重排后的相关上下文 | 用语义判断过滤表面相似但无用的内容 |
如果把 RAG 看成一个信息筛选系统,这三个结构分别对应三个问题:从哪里找、按什么形式答、哪些证据最可信。
二、为什么 native RAG 不够
native RAG 的逻辑很清楚:解析文档,切块,向量化,用户提问后做 Top K 相似度检索,再把检索结果交给大模型回答。这个流程适合文档数量少、结构简单、问题范围明确的场景。
企业知识库一般不满足这些条件。
第一,文档很长。年报、制度、合同、技术手册都可能有几十到上千页。切块后,一个问题可能只命中局部文本,但真正的解释在同一页前后段落或表格脚注中。
第二,表格很重要。企业知识库中大量事实存在于表格里,例如营收、成本、指标、部门职责、合同条款。PDF 表格如果解析不好,后面的检索和生成都会失真。
第三,问题类型不同。用户可能问数值、名称、列表、判断、对比、解释。不同问题需要不同输出约束。数值问题要求简洁和单位,对比问题要求分项,解释问题要求上下文完整。
第四,检索空间太大。如果所有文档进入同一个向量库,语义相近但实体错误的内容很容易被召回。例如用户问 A 公司收入,检索结果可能混入 B 公司收入;用户问某个制度条款,系统可能召回同类制度但不是目标文档。
因此,企业 RAG 的重点不是“大模型更聪明”,而是把文档、检索、Prompt、评估这些工程边界先设计清楚。
三、关键技术细节
1. PDF 解析:决定知识库的上限
PDF 解析是 RAG 的入口。解析质量差,后面模型再强也只能在错误文本上工作。
企业文档和论文 PDF 都有复杂版面。常见问题包括多栏文本顺序错误、表格单元格丢失、跨页表格断裂、页眉页脚污染正文、公式和图注混入段落。原始方案中曾对多种解析器进行比较,最终强调高质量 PDF parser 的重要性。
在实际改造中,我把解析流程迁移到 MinerU。原因是它对论文版面、表格、公式和多栏内容更稳定,也更适合后续把页面结构转为可检索文本。原始的docling更适合英文版的PDF,国内PDF中文居多,所以用功能类似的第3方PDF解析工具MinerU代替,配置好相关API即可。解析后的结果先进入 debug_data/01_parsed_reports,然后再合并为页面级文本。这个中间结果必须保留,方便定位解析错误。
解析阶段的目标不是得到看起来像文本的内容,而是得到后续可以被检索、引用和回溯的结构化页面。
2. 文本切块:不能只追求固定长度
切块的目标是在上下文窗口、召回精度和语义完整性之间做平衡。
块太小,召回会更精确,但容易丢失定义、上下文、表格说明和实验条件。块太大,召回噪声增多,模型输入成本变高。原始方案采用 chunk 召回后再回到 parent page 的方式,比较适合长文档问答。
在我的版本中,切块时保留以下元数据。
字段 | 作用 |
|---|---|
| 标识来源论文或文档 |
| 用于答案引用和结果展示 |
| 辅助区分同主题论文 |
| 帮助模型理解论文背景 |
| 支持页级引用 |
| 当前 chunk 文本 |
| 当前 chunk 所在页面全文 |
这里最重要的是 parent_text。它让系统可以先用小块做精确召回,再用整页做上下文补全。
3. 多知识库路由:先确定检索边界
数据库路由的作用是先确定问题应该进入哪个知识库。原始企业年报场景中,路由对象可以是公司、报告或文档集合。我的论文知识库版本中,路由对象变成研究主题。
当前有两个主题知识库。
主题库 | 覆盖范围 |
|---|---|
| WiFi sensing、CSI、Fresnel、device-free sensing、呼吸检测、人体活动识别 |
| 被动雷达、Passive WiFi Radar、illuminators of opportunity、USRP、reference channel、surveillance channel |
当前路由采用关键词匹配,而不是直接使用 LLM router。原因是主题数量少,边界清晰,关键词路由更快、更稳定,也更容易调试。当主题数量增加或出现交叉主题时,可以再升级为 embedding router 或 LLM router。
这个模块曾暴露一个实际问题:旧评估集中 WiFi 感知如何用于人体呼吸检测? 没有命中任何主题关键词,系统直接路由失败。这个问题不是生成模型的问题,也不是向量库的问题,而是入口路由没有覆盖“呼吸检测”这类中文表达。补充关键词后,该问题可以正常进入 wireless_sensing 知识库。
4. 检索:向量检索、BM25 和混合检索
向量检索适合语义相近的问题,例如“CSI 通常表征什么信息”和“channel state information captures what”。BM25 更适合关键词明确的问题,例如 USRP、CAF、reference channel 这类专有词。混合检索则把两者结合,适合既有语义解释又有明确术语的问题。
当前代码支持三种模式。
模式 | 适用场景 | 风险 |
|---|---|---|
| 概念解释、跨语言问答、同义表达 | 可能漏掉精确术语 |
| 专有名词、缩写、设备型号、固定术语 | 对改写问题不敏感 |
| 同时包含语义和关键词的问题 | 参数需要调,结果解释更复杂 |
当前默认以 vector 为主,同时保留 BM25 和 hybrid 作为调试选项。这样设计的好处是,先用简单稳定的路径跑通,再在特定问题上比较检索策略。
5. 父页召回:解决 chunk 上下文不足
父页召回是原始方案中很关键的设计。
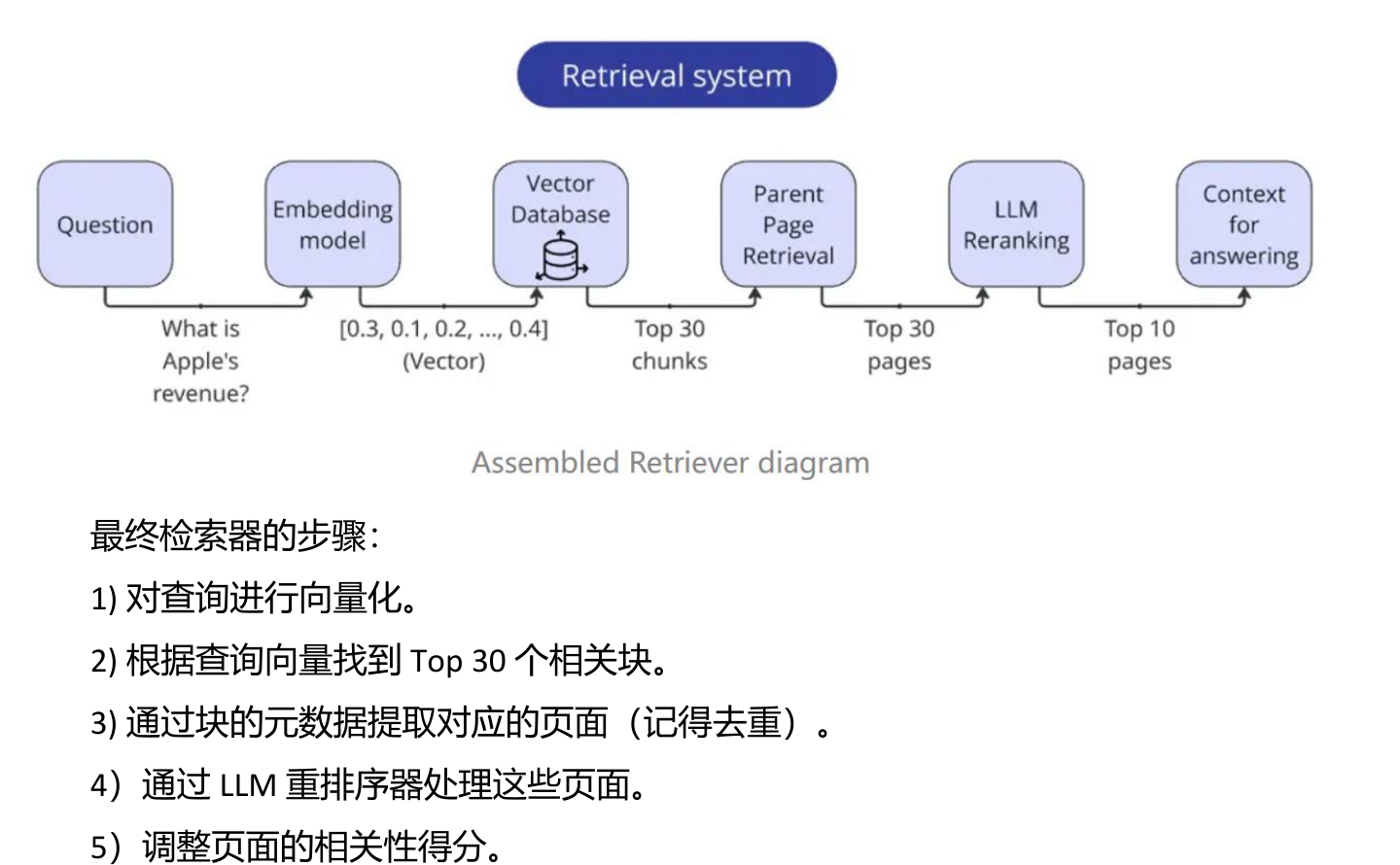
它的流程是:用户问题先向量化,在向量库中找到 Top K chunk;然后根据 chunk 元数据找到对应页面;再对页面去重;最后把这些页面交给 LLM reranker 排序。
这样做的原因很直接:chunk 适合检索,page 适合阅读。检索需要粒度细,回答需要上下文完整。特别是论文问答中,一个概念可能在前半页定义,后半页解释实验结果,只给模型一个局部 chunk 容易造成回答片面。
6. LLM reranking:用语义判断重排证据
向量相似度只衡量文本和问题在 embedding 空间中的距离,并不等价于“这段文本能回答问题”。LLM reranking 的作用是让模型逐条判断候选上下文和问题的相关性。
当前版本使用 qwen3.5-flash 做 reranker,并关闭思考模式。
这里关闭思考模式是有必要的。重排任务不需要长链推理,它需要快速、稳定地给出相关性分数。启用长推理会增加耗时,也可能让模型输出多余解释,影响结构化解析。
7. Prompt 与结构化输出:控制答案形态
原始企业年报问答中,不同问题类型使用不同 Prompt 和 schema,例如数值、布尔、名称、名称列表、对比问题。这个设计很重要,因为企业问答不是开放式聊天,答案要能被检查和提交。
论文知识库问答中,问题更多是解释型、总结型和方法对比型,因此当前主要使用 str 类型输出。它要求模型返回分析过程摘要、引用页面、来源论文标题和最终答案。
这种约束有两个作用。第一,减少模型自由发挥。第二,让系统可以把引用页和最终答案一起展示,方便人工复查。
四、案例一:原始企业知识库方案
原始方案解决的是企业年报类问答。假设用户问:
如果使用 native RAG,系统可能直接在全部年报中做向量检索。这种做法有两个隐患:一是可能召回其他公司的 revenue 信息,二是可能只召回表格附近的局部文本,缺少单位、年份和上下文。
冠军方案的处理路径更稳。
第一步,问题进入数据库路由。系统根据问题中的公司名、报告名或实体信息,把问题路由到 Apple 对应的向量库,而不是所有企业文档。
第二步,在对应向量库中检索 Top K chunk。这个阶段只负责找到可能相关的局部片段。
第三步,根据 chunk 元数据回到 parent page。这样可以拿到完整页面,包括表格标题、单位、脚注和上下文说明。
第四步,LLM reranking 对候选页面重新评分。它判断页面是否真的能回答 revenue 问题,而不只是包含 revenue 这个词。
第五步,Prompt 路由选择数值类回答模板。最终输出需要包含数值、单位、年份和引用页,不能写成泛泛解释。
这个案例说明,原始方案的核心不是某个模型,而是把企业问答拆成了可控链路:先选库,再检索,再补上下文,再重排,再按问题类型生成。
五、案例二:面向企业落地的改造版本
比赛方案可以取得高分,但真实企业环境还要考虑另一类问题:能不能部署,能不能调试,能不能迁移到国内 API,能不能处理企业内部文档,能不能解释错误来源。
因此,落地版需要做几类改造。
改造点 | 原始比赛思路 | 落地版处理 |
|---|---|---|
文档解析 | 选择高分 parser | 保留解析中间结果,方便人工检查 |
API 调用 | 可使用国外模型和服务 | 迁移到 DashScope/Qwen,降低环境依赖 |
表格处理 | 追求评测集效果 | 表格可选序列化,避免无意义增加成本 |
检索方式 | 固定竞赛参数 | 支持 vector、BM25、hybrid 调试 |
Prompt | 面向固定题型 | 按企业实际问题类型重写 |
调试方式 | 关注最终提交文件 | 展示路由、召回、重排、引用、耗时 |
一个实际企业需求可以这样理解:企业内部有制度文档、产品手册、合同模板、财务报告和项目总结。员工提问时,系统不仅要回答,还要指出答案来自哪份文档、哪一页,并且不能把相似部门、相似产品或相似年份的信息混在一起。
这种场景下,推荐流程如下。
这里的关键变化是,知识库不再只是所有文档的集合,而是按照业务边界组织。对企业来说,业务边界比模型参数更重要。人事制度、财务报表、技术手册、合同条款混在同一个库里,检索质量通常会下降。
落地版还需要保留可观察性。一次失败回答至少要能判断下面几个问题。
观察点 | 判断的问题 |
|---|---|
路由结果 | 问题是否进入正确知识库 |
初始召回 | 是否找到相关文档 |
父页召回 | 是否补齐上下文 |
rerank 分数 | 相关证据是否排到前面 |
引用页面 | 答案是否可追溯 |
耗时统计 | 系统是否具备交互性 |
如果没有这些中间信息,RAG 调优只能靠猜。企业知识库中最常见的问题不是模型完全不会答,而是答得像对的,但引用错、年份错、部门错或依据不充分。
六、案例三:我的论文知识库版本
在企业知识库框架基础上,我把项目迁移到个人论文知识库。这个版本的目标不是问公司财报,而是服务于博士论文方向的文献阅读和方法复用。
当前知识库包含两个主题:wireless_sensing 和 passive_radar。每个主题目录下放多篇论文 PDF,每个主题最终生成一个 FAISS 向量库和一个 BM25 索引。用户提问后,系统先根据中英文关键词选择主题库,再做检索、父页召回、Qwen reranking 和 Qwen 回答。
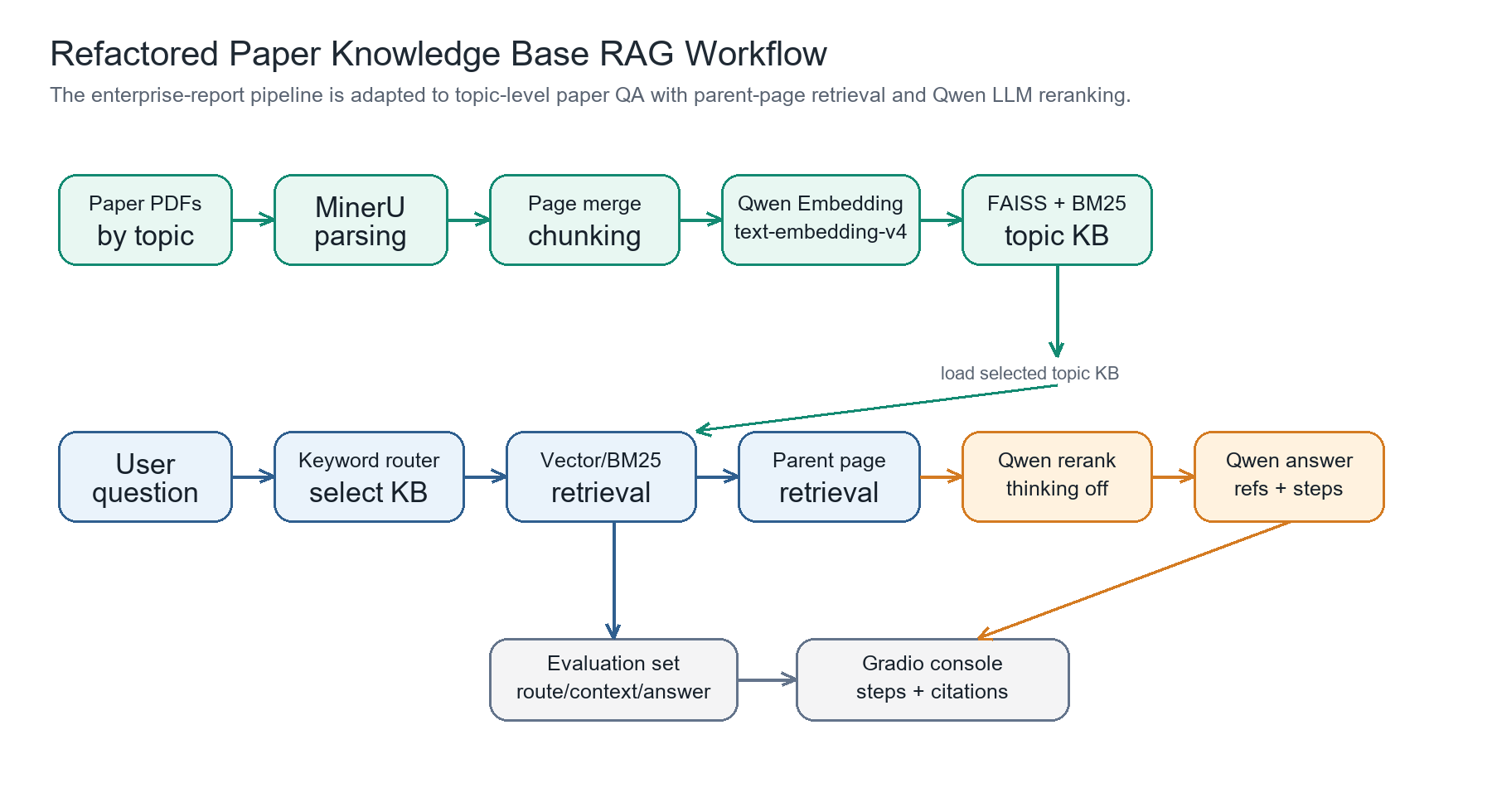
核心配置如下。
离线构建过程如下。
被动雷达主题执行同样流程。
构建完成后,父目录通过 knowledge_bases.json 管理多个主题库。问答时运行跨主题处理流程,或直接使用 Gradio 调试台。
示例 3.1:WiFi 呼吸检测
第一个问题用于验证无线感知主题。
这个问题需要系统找到三个层次的信息:WiFi 感知中的 CSI 或信号变化,人体呼吸造成的胸腔微动,Fresnel 区或相位变化对检测机制的解释。也就是说,它不是只问一个术语,而是问一个物理机制。
当前版本的执行结果如下。
步骤 | 结果 |
|---|---|
主题路由 | 命中 |
初始检索 | 返回 9 条候选 |
LLM 重排 | 保留 6 条上下文 |
上下文长度 | 13689 字符 |
回答生成 | 完成 |
总耗时 | 18.804 秒 |
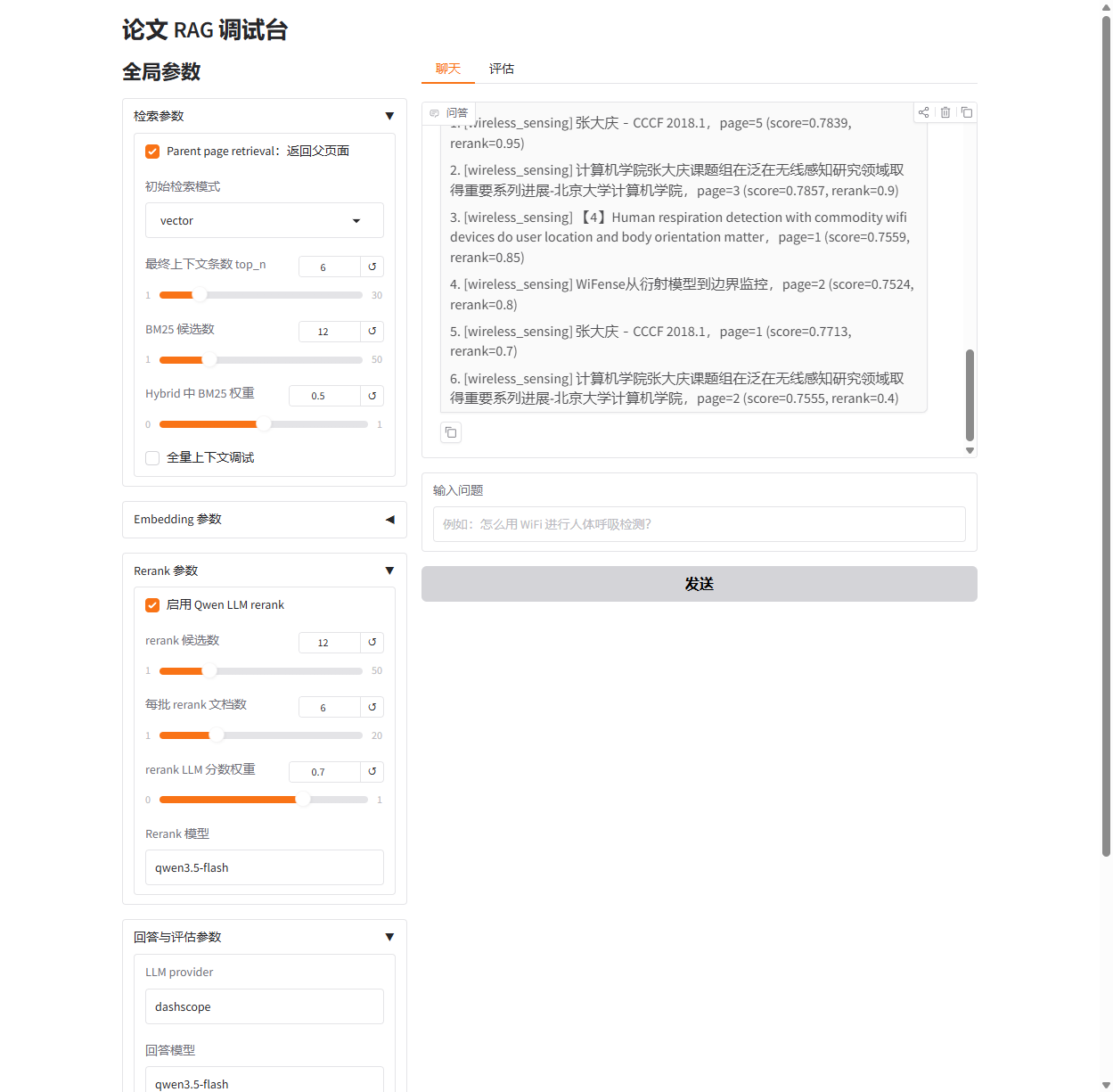
答案解释了呼吸引起胸腔起伏,进而导致反射路径长度和相位变化,最终在 WiFi 信号中表现为可检测的周期性变化。更重要的是,系统给出了引用来源,包括呼吸检测、毫米级 WiFi 感知和泛在无线感知相关论文页面。
这个例子也说明了评估的重要性。旧版本中该问题曾因为关键词缺失而路由失败。修复后,系统不仅能回答,还能展示路由、检索、重排和引用。
示例 3.2:Passive radar 机会照射源
第二个问题用于验证被动雷达主题。
这个问题的关键不是解释 radar 这个词,而是解释 passive radar 的系统机制:它不主动发射信号,而是利用环境中已有的 FM 广播、电视、蜂窝基站、卫星信号或 WiFi AP 作为机会照射源;系统通常通过 reference channel 接收直达信号,通过 surveillance channel 接收目标反射回波,再用信号处理方法完成检测或跟踪。
当前版本执行结果如下。
步骤 | 结果 |
|---|---|
主题路由 | 命中 |
初始检索 | 返回 10 条候选 |
LLM 重排 | 保留 6 条上下文 |
上下文长度 | 32780 字符 |
回答生成 | 完成 |
总耗时 | 19.576 秒 |
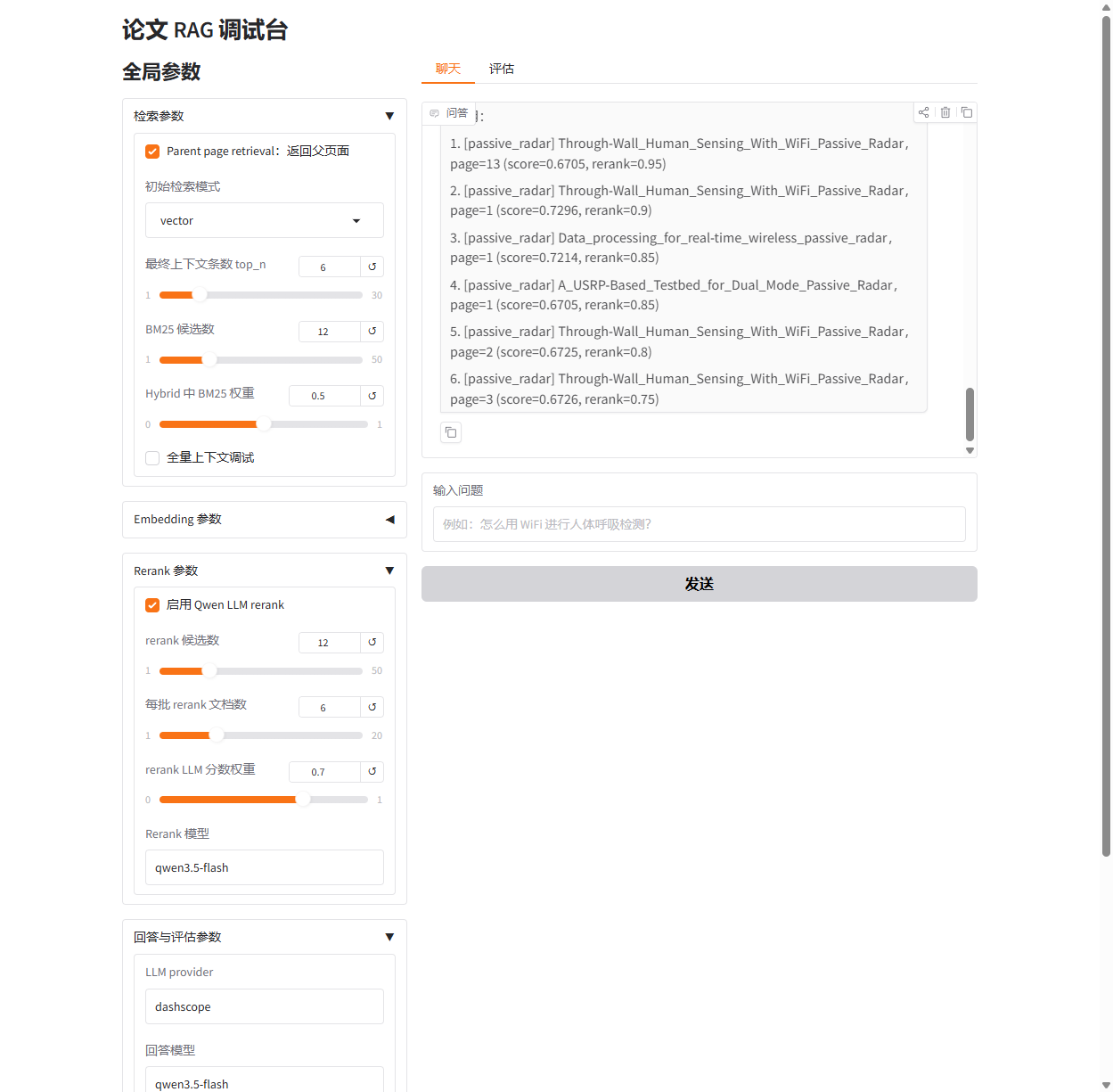
这个例子验证了跨主题路由的必要性。问题中可能出现 WiFi AP,但系统仍然应进入 passive_radar,因为问题核心是被动雷达的机会照射源机制,而不是一般 WiFi 感知。
七、评估方法
RAG 不能只看最终答案。最终答案正确时,可能只是模型猜对了;最终答案错误时,也需要知道错误来自解析、路由、检索、重排还是生成。
当前评估拆成五类指标。
指标 | 含义 | 用途 |
|---|---|---|
| 预测主题是否等于期望主题 | 评估路由是否正确 |
| 检索上下文是否覆盖期望关键词 | 评估证据召回 |
| 返回块中相关块比例 | 评估上下文噪声 |
| 答案是否覆盖期望关键词 | 评估回答要点 |
| 单问题耗时 | 评估交互可用性 |
评估集包含 24 个问题,覆盖无线感知和被动雷达两个主题。第一版本的结果中,23 个问题正确路由,1 个问题因为“呼吸检测”关键词缺失失败;上下文关键词召回均值为 0.875,上下文块精度均值为 0.8889,答案关键词召回均值为 0.6667。
路由错误的原因是,第一版本设计了2个主题的数据库,然后通过关键词去路由,如果关键词没有命中,则不选择任何数据库,直接导致检索失败,解决方案是让主题关键词模糊化,设计更多的关键词,同时设计多路由方案,一个问题可以同时路由多个数据库,最终结果符合预期,在当前较少的数据库下可以达到100%正确路由。
这组结果不能简单理解为系统最终准确率,而应理解为一次调试定位:检索和重排整体可用,但路由关键词表需要补齐,答案关键词召回仍有提升空间。后续可以继续扩展评估集,引入人工标准答案和引用页标注,再分别计算 Hit@K、MRR、nDCG、faithfulness 和 citation accuracy。
小结
企业知识库 RAG 的核心是工程链路设计,而不是单点模型调用。原始冠军方案的价值在于,它把 native RAG 拆成了可控模块:文档入库、数据库路由、Prompt 路由、父页召回、LLM 重排和结构化生成。真实落地时,需要进一步考虑解析质量、知识库边界、API 可用性、调试界面、评估集和引用追溯。
我的论文知识库版本在这个框架上做了主题化迁移。当前系统已经可以对无线感知和被动雷达论文进行问答,能够展示路由、检索、重排、引用和耗时。后续继续扩展时,优先方向不是盲目增加模型能力,而是增加主题库、完善路由策略、补充人工评估集,并把引用页准确性作为核心指标之一。