
ReAct: Synergizing Reasoning and Acting in Language Models论文阅读
摘要
本文解读 ICLR 2023 论文 ReAct: Synergizing Reasoning and Acting in Language Models。论文提出 ReAct prompting,将语言模型的推理轨迹与环境行动交替生成,使模型能够一边思考、一边查询外部信息或操作环境,从而提升知识密集型问答、事实验证和交互式决策任务的表现。
ReAct: Synergizing Reasoning and Acting in Language Models论文阅读
写在前面
ReAct 是今天很多 Agent 系统的基础范式。它把大语言模型的输出拆成三类信号:Thought、Action 和 Observation。
这篇论文的重要性不在于提出复杂模型结构,而在于给出了一个简单但影响深远的交互模式:模型不再只是在内部生成推理链,也不再只是机械调用工具,而是在推理和行动之间循环。
如果用一句工程化语言概括,ReAct 是早期 LLM Agent 的核心控制循环雏形。
速读卡片
项目 | 内容 |
|---|---|
论文 | ReAct: Synergizing Reasoning and Acting in Language Models |
作者 | Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, Yuan Cao |
会议/版本 | ICLR 2023;arXiv v3 为 camera-ready version |
论文主页 | |
arXiv | |
代码 | |
核心问题 | 如何让语言模型同时具备显式推理和外部行动能力 |
方法 | 在 prompt 中交替生成 |
任务 | HotpotQA、FEVER、ALFWorld、WebShop |
主要结论 | 推理帮助行动更有计划,行动帮助推理更接地 |
适合读者 | 想理解 Agent、Tool Use、Reasoning-Acting loop 的读者 |
一句话概括
ReAct 让语言模型在任务执行过程中交替生成推理轨迹和环境行动:推理用于规划、记忆和纠错,行动用于检索外部信息或改变环境状态,两者结合后比单独推理或单独行动更可靠。
研究问题
论文关注两个原本相对分离的方向。
第一类是 reasoning。典型代表是 Chain-of-Thought,模型通过中间推理步骤解决问题。但 CoT 主要依赖模型内部知识,无法主动访问外部环境,因此容易产生事实幻觉,也难以及时修正错误。
第二类是 acting。模型可以生成行动,例如搜索网页、点击按钮、执行环境操作。但如果缺少显式推理,行动往往缺少目标分解、状态跟踪和异常处理能力。
ReAct 的问题定义正是在这两者之间建立闭环:语言模型能否一边推理,一边行动,并根据外部反馈更新后续推理。
核心方法
ReAct 的方法非常直接:把语言模型的动作空间扩展为两部分。
其中 Thought 是语言形式的内部推理,不直接改变外部环境;Action 是对环境的操作,例如搜索、查找、点击、移动、拿取物体或提交答案;Observation 是环境返回给模型的新信息。
一个典型 ReAct 循环如下:
论文用 HotpotQA 和 ALFWorld 展示了 ReAct 与 Standard、CoT、Act-only 的差异。

图中可以看到,CoT 只有推理,没有外部反馈;Act-only 有行动,但缺少显式计划;ReAct 则在搜索、观察和推理之间交替进行。这个结构使模型能够根据检索结果调整下一步行动。
为什么 ReAct 有效
ReAct 的有效性来自推理与行动的互补。
推理的作用包括:
分解任务目标;
记录当前进度;
提取观察结果中的关键信息;
发现搜索失败或行动失败;
重新规划下一步行动。
行动的作用包括:
查询外部知识;
获取实时或更准确的信息;
改变交互环境状态;
验证模型内部推理是否成立。
因此,ReAct 不是单纯让模型“想得更久”,而是让推理过程被外部观察不断校正。
实验设置
论文在两类任务上评估 ReAct。
第一类是知识密集型推理任务:
HotpotQA:多跳问答;FEVER:事实验证。
这类任务中,模型可以使用一个简化 Wikipedia API,包括 search[entity]、lookup[string] 和 finish[answer]。
第二类是交互式决策任务:
ALFWorld:文本形式的家庭环境任务;WebShop:在线购物网页导航任务。
这类任务中,模型需要在长时序环境里完成目标,例如寻找物品、移动物品、筛选商品、选择选项并提交购买。
论文主要使用 PaLM-540B 进行 few-shot prompting,并在附录中补充 GPT-3 实验。
结果一:知识问答中,ReAct 更接地
HotpotQA 和 FEVER 的结果如下。
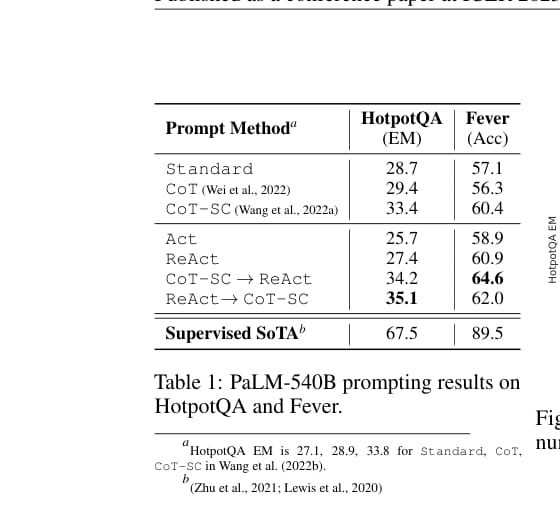
单独看 ReAct,它在 FEVER 上达到 60.9% accuracy,高于 CoT 的 56.3% 和 Act-only 的 58.9%。在 HotpotQA 上,ReAct 的 27.4 EM 略低于 CoT 的 29.4 EM。
这说明 ReAct 并不是在所有知识问答指标上直接超过 CoT。它的优势在于让推理更接地,尤其适合需要外部事实验证的任务。
论文进一步提出 ReAct 与 CoT-SC 结合:
CoT-SC -> ReAct:当 CoT-SC 多数答案不够稳定时,切换到 ReAct;ReAct -> CoT-SC:当 ReAct 在限定步数内没有完成时,回退到 CoT-SC。
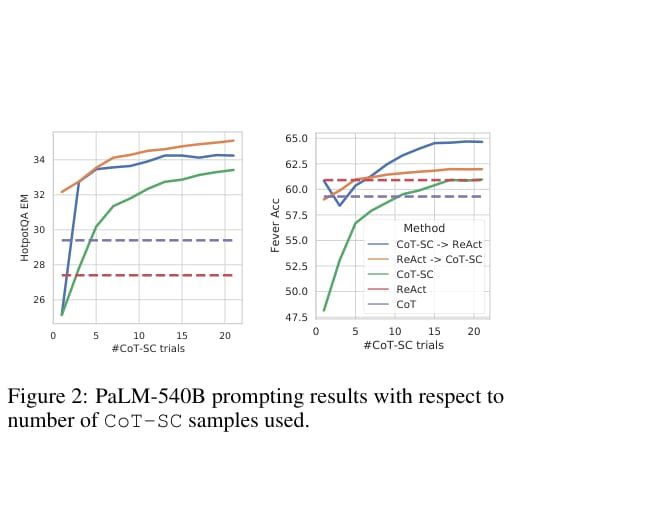
结果显示,组合方法在 HotpotQA 和 FEVER 上都能超过单独 CoT-SC。这说明内部知识和外部知识不是替代关系,而是互补关系。
结果二:ReAct 降低幻觉,但会引入检索依赖
论文人工分析了 HotpotQA 上 ReAct 和 CoT 的成功与失败模式。

表中最重要的结论是:CoT 的失败主要来自幻觉,失败样本中 56% 与 hallucination 有关;ReAct 的失败中 hallucination 为 0%,但有 23% 来自 search result error。
这揭示了 ReAct 的取舍。
ReAct 将一部分内部幻觉风险转移成外部检索风险。它更事实驱动、更可检查,但如果搜索结果为空、检索实体错误或观察信息不足,后续推理也可能被带偏。
因此,ReAct 并没有消除错误,只是让错误来源更可见、更容易诊断。
结果三:微调后 ReAct 潜力更明显
论文还研究了少量 ReAct 轨迹微调小模型的效果。
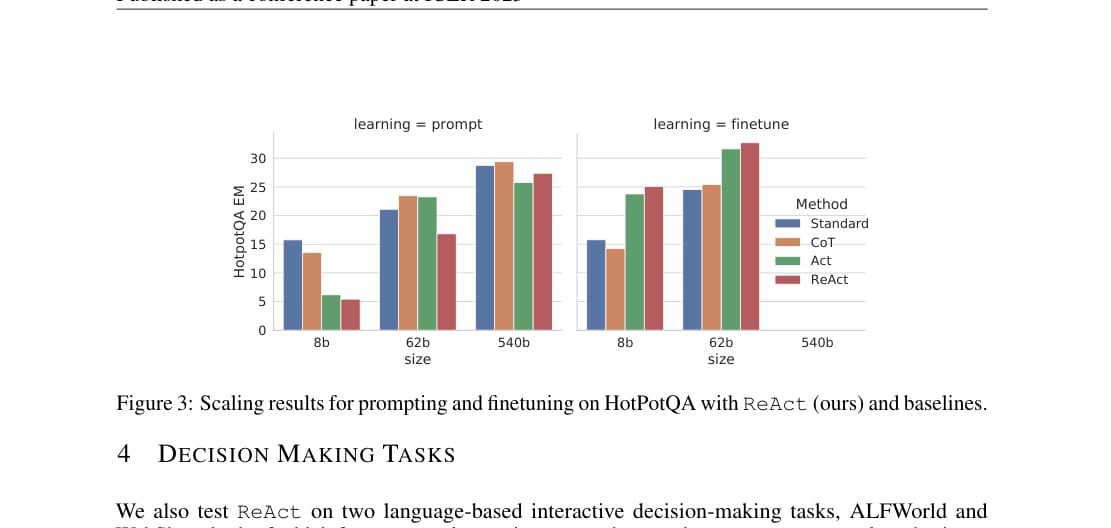
在纯 prompting 设置下,小模型很难从少量示例中同时学会推理和行动。但用 3000 条正确 ReAct 轨迹进行微调后,ReAct 成为表现最好的方法。
论文指出,PaLM-8B 微调 ReAct 可以超过所有 PaLM-62B prompting 方法;PaLM-62B 微调 ReAct 可以超过所有 PaLM-540B prompting 方法。
这个结果说明 ReAct 不只是 prompt 技巧,也可以作为训练数据格式。后续很多 Agent trajectory training 的思路,都可以在这里看到早期雏形。
结果四:交互式任务中,ReAct 明显优于 Act-only
在 ALFWorld 中,ReAct 需要在文本家庭环境里完成任务。结果如下。
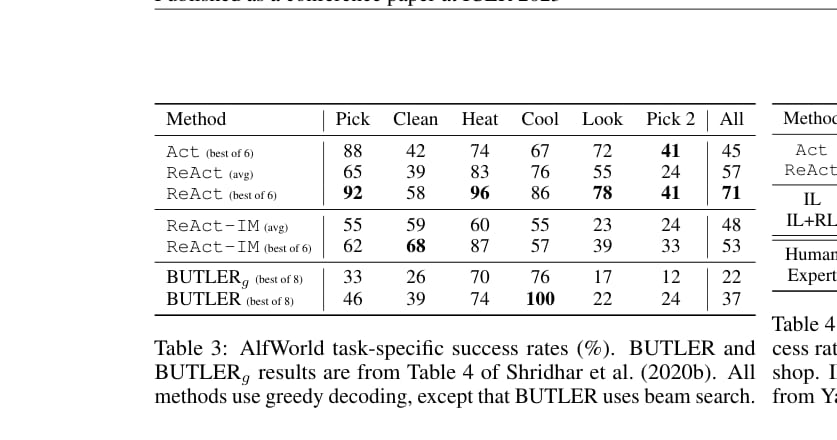
最佳 ReAct trial 的整体成功率为 71%,显著高于 Act-only 的 45% 和 BUTLER 的 37%。论文特别强调,即使最差的 ReAct trial 也能达到 48%,仍高于 Act-only 和 BUTLER 的最佳结果。
在 WebShop 中,ReAct 也带来明显提升。
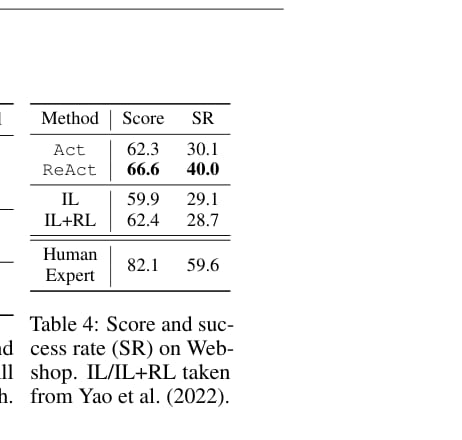
ReAct 的成功率为 40.0%,高于 Act-only 的 30.1%、IL 的 29.1% 和 IL+RL 的 28.7%。这说明在网页导航和商品筛选任务中,显式推理可以帮助模型识别哪些产品属性与用户需求真正相关。
案例:ReAct 如何处理过期知识
论文附录中给出一个很有代表性的 HotpotQA 案例:数据集标签已经过期。

Standard 和 CoT 依赖内部知识,给出了错误或过期答案。Act-only 虽然可以访问网页,但缺少推理引导,无法完成有效搜索链。ReAct 则通过搜索、观察和后续推理,找到了更新后的信息。
这个案例说明 ReAct 的价值不只是提高分数。更重要的是,它把模型从静态知识库变成了可以主动验证信息的交互式系统。
案例:推理轨迹让人工纠错更容易
ReAct 的另一个优点是可编辑性。论文展示了一个 ALFWorld 中的人类介入案例。

原始 ReAct 轨迹因为一个错误 thought 失败。人类只需要修改少量 thought,就能改变后续行动轨迹,使任务最终成功。
这说明 Thought 不只是给模型看的中间文本,也是人类理解和干预模型行为的接口。相比直接修改模型参数或逐条指定行动,编辑 thought 更轻量,也更接近人类协作方式。
案例:WebShop 中的思考如何改善选择
WebShop 示例展示了 ReAct 如何避免表面匹配。

Act-only 直接选择了搜索结果中并不满足价格和口味要求的商品。ReAct 则显式分析候选商品是否符合“apple cinnamon”“sixteen pack”“price lower than 50.00 dollars”等约束,再点击合适选项。
这个案例体现了 ReAct 在网页环境中的作用:它把网页观察转化为可检查的条件判断。
核心贡献
论文贡献可以概括为四点。
第一,提出 ReAct prompting。它将语言模型的推理轨迹和环境行动交替生成,形成统一的任务求解轨迹。
第二,在多类任务上验证 ReAct。论文覆盖知识问答、事实验证、文本游戏和网页导航,说明该范式具有较强通用性。
第三,系统分析 reasoning 与 acting 的互补关系。推理能让行动更有计划,行动能让推理更事实驱动。
第四,展示 ReAct 的可解释性和可控性。人类可以通过阅读或编辑 thought 理解并干预模型行为。
局限性
ReAct 也有明显限制。
第一,prompt 长度限制会约束复杂任务。对于大动作空间和长轨迹任务,少量 in-context 示例可能不足以覆盖足够多的行为模式。
第二,ReAct 依赖外部行动质量。搜索失败、观察不完整或环境反馈噪声都会影响后续推理。
第三,ReAct 可能出现循环或重复行动。论文在错误分析中提到,模型有时会重复生成之前的 thought 和 action,无法跳出错误轨迹。
第四,ReAct 暴露了更强的外部行动能力,也带来安全风险。论文在 ethics statement 中提醒,如果模型连接真实网页、物理环境或敏感系统,需要严格限制行动空间。
未来工作
论文提出了几个方向。
第一,使用更多高质量人工轨迹进行微调。初步实验已经显示,ReAct 轨迹训练可以显著提升小模型表现。
第二,扩大到多任务训练。让模型在更多任务中学习通用的 thought-action-observation 结构,可能比单任务 prompt 更稳定。
第三,将 ReAct 与强化学习结合。ReAct 提供可解释轨迹,RL 可以进一步优化长时序决策。
第四,研究更系统的人类介入机制。论文只展示了 thought editing 的初步案例,后续可以发展成更完整的人机协作范式。
第五,设计更安全的行动边界。未来 Agent 接入真实工具和环境时,需要权限、沙箱、审计和回滚机制配合。
对 Agent 系统的启发
ReAct 对今天的 Agent 系统仍然有直接启发。
第一,工具调用不能脱离推理。模型需要说明为什么调用某个工具、期望获得什么信息、观察结果如何改变下一步计划。
第二,推理也不能脱离环境。只依赖模型内部知识会放大幻觉风险,尤其在知识更新快或事实要求高的场景中。
第三,Agent 轨迹应该可读。Thought -> Action -> Observation 的结构不仅服务模型,也服务调试、审计和人工接管。
第四,少样本 prompt 可以验证范式,但生产系统需要训练和工程约束。ReAct 的思想需要与权限系统、工具描述、上下文管理和失败恢复结合,才能形成可靠 Agent。
第五,ReAct 的价值不只是“让模型思考”。它真正重要的地方,是把思考放进一个可观察、可反馈、可干预的闭环中。
小结
ReAct 是一篇基础性 Agent 论文。它用非常简洁的方式回答了一个核心问题:语言模型如何同时推理和行动。
论文的结论可以浓缩为一句话:推理让行动更有目标,行动让推理更接近事实。
从今天的视角看,ReAct 已经成为许多工具调用 Agent、浏览器 Agent、代码 Agent 和多步骤任务系统的基本结构。理解 ReAct,有助于理解为什么现代 Agent 不只是一次模型调用,而是一条不断被观察结果修正的执行轨迹。