
Embedding 与向量数据库实践
摘要
本文从文本相似度问题出发,整理 Embedding、余弦相似度、Word2Vec、现代 Embedding 模型选型和向量数据库的核心逻辑,并通过酒店内容推荐和向量元数据检索两个案例说明如何落地。
Embedding 与向量数据库实践
写在前面
Embedding 和向量数据库是检索增强生成( Retrieval-Augmented Generation, RAG)、语义搜索、推荐系统和多模态检索的基础。它们共同解决一个问题:如何让机器比较非结构化数据之间的相似性。
文本、图片、音频、商品、用户行为都不能直接做语义距离计算。Embedding 负责把对象映射成向量,向量数据库负责高效存储和检索向量,元数据系统负责把检索到的向量重新映射回原始文本、来源文件、章节、类别、权限和版本信息。
本文按总分结构展开。先说明整体链路,再解释表示方法、相似度计算、模型选择、向量数据库选型,最后用两个案例说明工程落地。
层次 | 核心问题 | 代表方法 |
|---|---|---|
表示层 | 如何把文本变成可计算特征 | N-Gram,N元语法;TF-IDF,词频-逆文档频率;Word2Vec;现代 Embedding |
检索层 | 如何判断两个对象是否相似 | 余弦相似度、欧氏距离、内积、Top-K 检索 |
工程层 | 如何把向量结果映射回业务数据 | Facebook AI Similarity Search,Facebook AI 相似度搜索库(FAISS);Milvus;Elasticsearch;元数据存储 |
核心结论是:Embedding 决定语义表示质量,向量数据库决定检索效率和工程可用性,元数据决定结果是否可解释、可追溯、可管理。
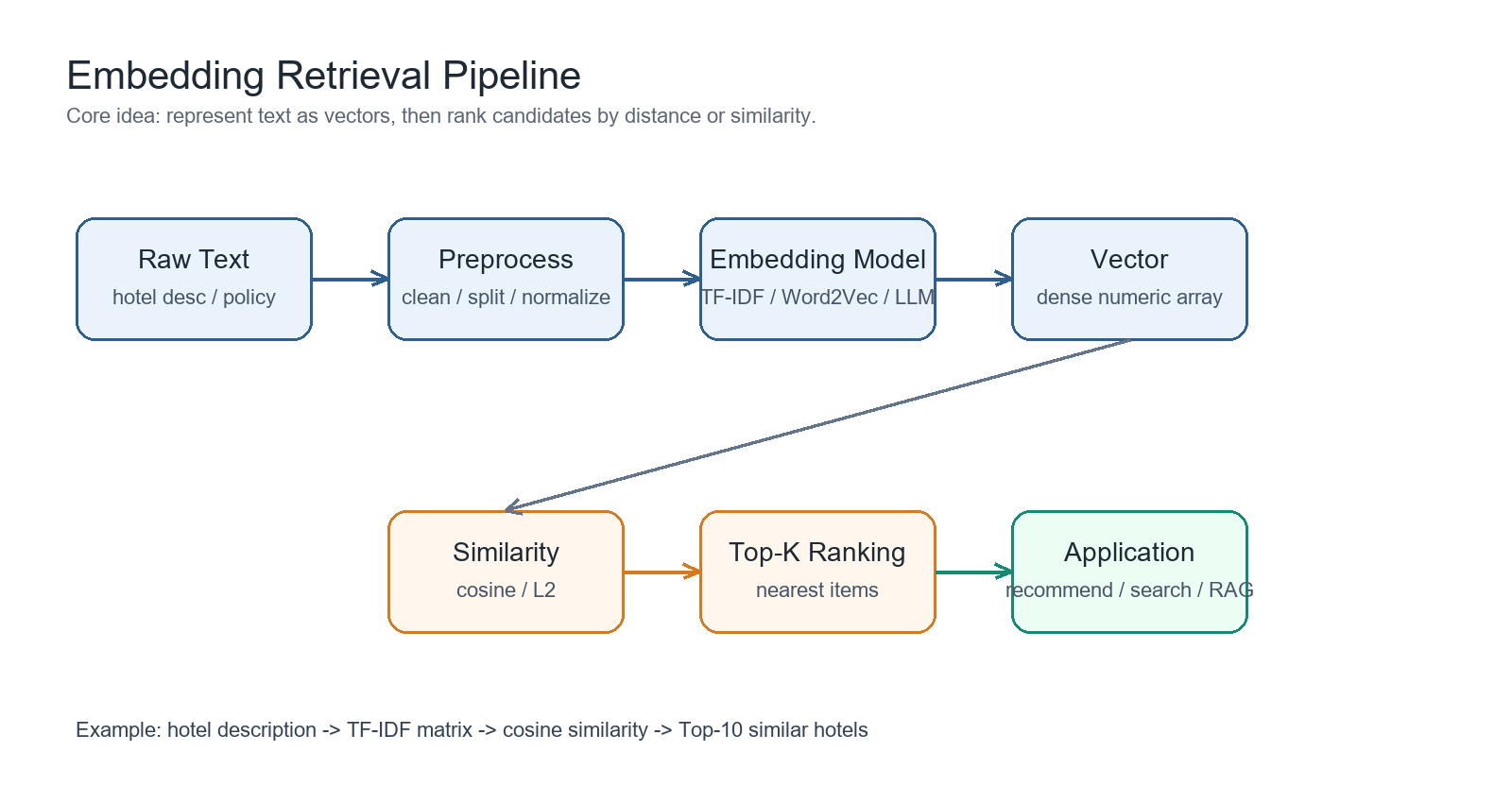
一、Embedding 的基本逻辑
Embedding 的本质是表示学习。它把离散对象映射到连续向量空间,使语义相近的对象在空间中距离更近。
在文本处理中,最早可以从词频向量理解这个问题。假设有两个句子:
先分词,再统计所有词出现的次数,就能得到两个词频向量。随后使用余弦相似度比较两个向量方向是否接近。方向越接近,文本越相似。
余弦相似度关注向量夹角,不直接关注文本长度。它适合文本相似度,因为文本更长不一定代表语义更相关。
当两个向量方向相同,相似度接近 1;方向正交,相似度接近 0;方向相反,相似度接近 -1。
这个思想可以推广到现代 Embedding。模型把句子、段落、文档、图片或代码转成向量,后续只需要比较向量距离,就能完成搜索、推荐、聚类、分类和 RAG 召回。
二、从 N-Gram、TF-IDF 到 Word2Vec
N-Gram,N元语法,是最基础的文本特征方法。它把连续 N 个词作为一个特征。N=1 是 unigram,一元语法;N=2 是 bigram,二元语法;N=3 是 trigram,三元语法。
N-Gram 的价值在于保留短语结构。单独的 airport 表达有限,airport shuttle 的语义更明确;单独的 free 表达有限,free breakfast 更接近酒店推荐场景中的有效特征。
TF-IDF,Term Frequency-Inverse Document Frequency,词频-逆文档频率,是在词频基础上引入区分度。Term Frequency,词频(TF)表示一个词在当前文档中出现的频率;Inverse Document Frequency,逆文档频率(IDF)表示一个词在整个语料中有多稀缺。越常见的词,区分度越低;越少见但在当前文档中频繁出现的词,权重越高。
这类方法有两个优点:实现简单、可解释。但缺点也很明显:特征稀疏、维度高,对同义词、跨语言表达和深层语义不敏感。
Word2Vec 是从稀疏词频表示走向稠密语义表示的重要方法。它通过上下文预测学习词向量,使语义相近的词在向量空间中更接近。经典关系可以写成:
这说明向量不仅能表示词,还能承载一定语义关系。现代 Embedding 模型进一步扩展了这种能力,可以表示句子、段落、长文档、代码和图文内容。
三、案例一:酒店内容推荐
第一个案例用西雅图酒店数据集说明相似度检索的最小闭环。数据字段包括酒店名称、地址和描述。任务是:用户选择一家酒店后,系统根据描述内容推荐最相似的 Top 10 家酒店。
这个案例不依赖大语言模型,也不依赖向量数据库,但它完整展示了语义检索的底层结构。
核心代码如下。
这里的 tfidf_matrix 是酒店描述矩阵。每一行表示一家酒店,每一列表示一个文本特征。linear_kernel 用于计算酒店之间的相似度矩阵,在归一化 TF-IDF 向量上等价于余弦相似度。
推荐函数根据目标酒店找到相似度最高的其他酒店。
这个逻辑可以拆成三个步骤。
第一,根据酒店名称找到它在矩阵中的行号。第二,取出这一行对应的相似度向量,并按分数从高到低排序。第三,去掉自身后返回 Top-K 酒店。
下图用同一份数据复现了两个查询样例。机场会议酒店会推荐其他机场附近酒店,Bacon Mansion Bed and Breakfast 会推荐其他 Bed and Breakfast 类型酒店。结果符合内容推荐的直觉。

这个案例的工程启发是:Embedding 检索并不神秘,它本质上是把对象变成向量后做近邻搜索。区别只在于,TF-IDF 是稀疏词面特征,现代 Embedding 是稠密语义特征。
传统 TF-IDF 更适合词面相似任务。例如用户输入 quiet hotel near airport,它可以较好工作。但如果用户输入中文语义表达,例如适合早班飞机的住宿,TF-IDF 很难和英文酒店描述建立语义对应。这类场景需要多语言 Embedding 或跨语言语义模型。
四、Embedding 模型选择
Embedding 模型选型不能只看排行榜。MTEB,Massive Text Embedding Benchmark,大规模文本嵌入基准,提供了检索、语义相似度、重排序、分类、聚类、对分类、双语挖掘、摘要相似度等任务评估。它适合作为初筛工具,但不能替代业务测试集。
选型时至少考虑五个因素。
因素 | 判断问题 |
|---|---|
任务类型 | 是检索、分类、聚类、重排,还是跨语言搜索 |
语言范围 | 中文单语言、多语言,还是中英混合 |
向量维度 | 是否值得用更高维度换取更强表达 |
上下文长度 | 是否需要处理长文档、表格、代码或图文内容 |
部署成本 | Application Programming Interface,应用程序编程接口(API)调用、私有化部署、延迟和并发是否可接受 |
向量维度是常见误区。维度越高,表达能力通常越强,但存储、计算和索引成本也更高。假设从 768 维升到 1024 维,检索指标只提升不到 1%,但内存占用增加约 35%,通常不值得。反过来,如果降维后指标下降超过 5%,说明信息损失明显,应保留更高维度。
有些模型支持 Matryoshka Representation Learning,俄罗斯套娃表示学习。它会生成一个高维向量,但前 128、256、512、1024 维也能单独作为较高质量的短向量使用。这样可以按场景动态调整维度:短文本、实时评论、移动端可以用低维;财报、法律、技术文档可以用高维。
单语言和多语言模型也要区分。中文客服、中文制度问答可以优先测试中文模型;跨境酒店评论、国际客服和中英混合知识库应优先测试多语言模型。多语言模型的价值在于把不同语言映射到同一语义空间,使 clean room、部屋が綺麗 和 干净的房间 在向量空间中更接近。
更稳妥的选型流程如下。
Recall@K 表示 Top-K 结果中是否召回正确答案;NDCG,Normalized Discounted Cumulative Gain,归一化折损累计增益,用于评价排序质量;MRR,Mean Reciprocal Rank,平均倒数排名,用于衡量第一个正确结果排得是否足够靠前。这些指标比单纯看模型榜单更接近实际业务效果。
五、向量数据库解决什么问题
当数据量很小时,可以直接用矩阵计算相似度。数据量变大后,就需要向量数据库或向量检索库。
向量数据库的核心能力是高效相似性检索。它存储高维向量,并根据余弦相似度、L2 距离或内积快速返回最接近的 Top-K 向量。
它和传统数据库的区别如下。
对比项 | 传统数据库 | 向量数据库 |
|---|---|---|
数据对象 | 行、列、结构化字段 | 高维向量 |
查询方式 | 精确匹配、范围查询、聚合 | 相似度搜索、近邻搜索 |
典型问题 |
| 哪些文本和这个问题语义最接近 |
主要场景 | 事务、报表、业务系统 | 语义搜索、推荐、RAG、多模态检索 |
常见选型如下。
工具 | 全称或定位 | 适用场景 |
|---|---|---|
FAISS | Facebook AI Similarity Search,Facebook AI 相似度搜索库 | 本地实验、算法验证、深度集成 |
Milvus | 开源分布式向量数据库 | 企业级大规模向量检索 |
Pinecone | 托管向量数据库服务 | 快速上线、减少运维 |
Weaviate | 支持自动向量化的开源向量数据库 | 快速构建端到端语义应用 |
Qdrant | Rust 实现的向量数据库 | 复杂 metadata filter 场景 |
Elasticsearch | 通用搜索引擎,支持向量检索 | 关键词搜索和向量搜索混合场景 |
如果只是验证原理,FAISS 最合适。它足够轻量,能让人理解向量索引和元数据映射的本质。如果要做企业级在线服务,需要考虑 Milvus、Qdrant、Elasticsearch 或托管服务。如果业务强依赖关键词、过滤、聚合和权限,Elasticsearch 或 OpenSearch 的混合搜索能力往往更实用。
六、案例二:FAISS 与元数据管理
第二个案例更接近 RAG 的最小工程形态。任务是把几条迪士尼相关政策文本向量化,存入 FAISS,然后根据用户问题检索最相关文本,并返回元数据。
用户问题是:
样例文档包括四类内容:一般退票政策、年卡权益、在线购票退票规则、项目维护公告。系统应该优先返回退票流程相关文本,而不是年卡权益或维护公告。
整体流程如下。
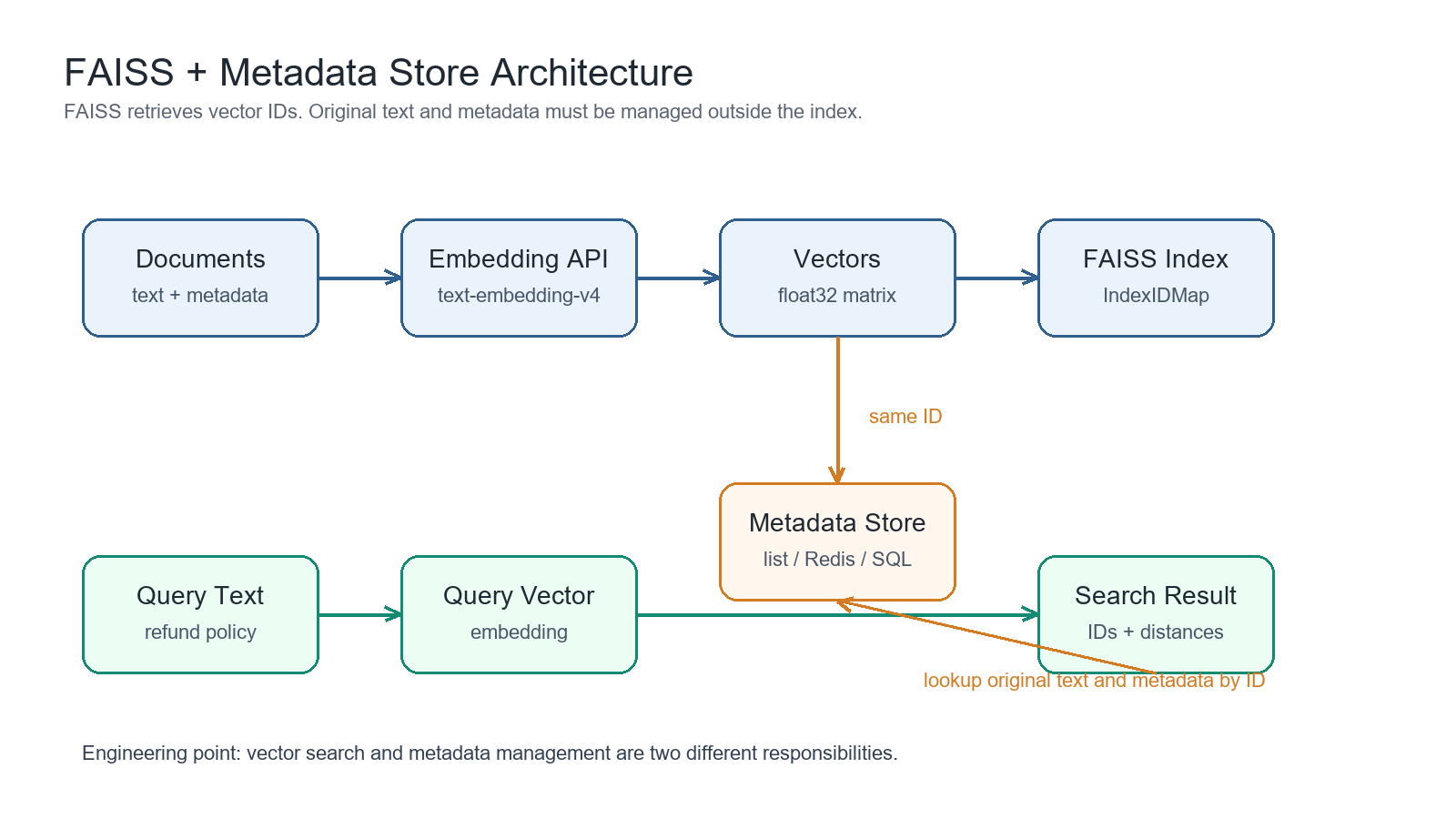
文档准备阶段,文本和元数据要一起设计。
随后调用 text-embedding-v4 生成向量。
FAISS 本身只负责向量检索,不负责保存原始文本和业务元数据。因此需要维护外部 metadata_store。
构建索引时使用 IndexIDMap。它的作用是让 FAISS 返回自定义 ID,而不是只返回内部位置。
检索时,FAISS 返回距离和 ID。系统再用 ID 查询元数据。
运行结果显示,排名第一的是在线购买门票的退票流程,排名第二是一般退换规则,排名第三才是年卡权益。这个结果符合预期:用户问退款流程,系统优先命中退票政策,而不是会员权益或园区公告。

这个案例说明一个重要工程事实:向量检索和元数据管理是两件事。FAISS 能快速找相似向量,但它不会替你管理来源文件、类别、权限、版本、删除、更新和审计。生产环境中,元数据应该交给更合适的系统。
元数据存储 | 适用场景 |
|---|---|
Python list / dict | 本地实验、小数据验证 |
Redis | 高性能 ID 查询和缓存 |
SQLite / PostgreSQL | 结构化元数据、事务、过滤 |
MongoDB | JSON 文档型 metadata |
Elasticsearch | 文本检索、过滤、聚合、混合搜索 |
七、向量数据库不是 RAG 的全部
很多 RAG 效果问题并不是向量数据库本身造成的。向量数据库只是链路的一环。
Large Language Model,大语言模型(LLM),最终只能基于检索到的上下文回答。因此,实际系统通常包含以下步骤:
如果 PDF 解析错误、切块断裂、Embedding 模型不适合业务语料、metadata 过滤缺失、rerank 没有做好,生成结果都会受到影响。
因此,优化 RAG 不能只问换哪个向量数据库,还要同时检查六个问题。
问题 | 影响 |
|---|---|
文档解析是否可靠 | 决定原始文本质量 |
切块是否保留语义边界 | 决定召回粒度 |
Embedding 模型是否适合业务语言 | 决定语义空间质量 |
相似度指标是否匹配模型训练方式 | 决定排序合理性 |
metadata 是否可过滤和回溯 | 决定结果可用性 |
是否需要 reranker | 决定最终证据质量 |
八、工程选型建议
本地实验和概念验证,推荐从 FAISS 开始。它简单、透明、速度快,适合理解向量检索原理。
企业级系统需要更早考虑服务化能力。
场景 | 建议 |
|---|---|
数据量小,本地实验 | FAISS |
数据量大,需要分布式扩展 | Milvus、Qdrant |
快速上线,减少运维 | Pinecone 或云厂商托管向量服务 |
关键词检索仍然重要 | Elasticsearch / OpenSearch |
过滤条件复杂 | Qdrant、Milvus、Elasticsearch |
需要图文统一检索 | 先确认 Embedding 模型是否支持多模态 |
Embedding 模型也应按业务测试集选择。中文知识库优先测试中文模型,中英混合和跨语言检索优先测试多语言模型,长文档和图文混合文档要额外测试上下文长度和多模态能力。不要只看榜单,必须用自己的数据评估 Recall@K、NDCG、MRR、延迟和成本。
小结
Embedding 解决表示问题,向量数据库解决检索问题,元数据系统解决可用性问题。三者缺一不可。
酒店推荐案例说明了相似度检索的基本闭环:文本特征化、相似度矩阵、Top-K 推荐。FAISS 案例说明了向量数据库落地时必须处理元数据映射,否则只能得到向量 ID,无法形成可解释结果。
真正的工程重点不是单独选择某个数据库,而是建立一条完整链路:合适的 Embedding 模型、合理的维度、可控的向量索引、可靠的元数据管理和可验证的评估集。只有这条链路成立,向量检索才有实际价值。